瞭解DOCSIS環境中的資料吞吐量
目錄
簡介
在嘗試測量電纜網路的效能之前,應該考慮一些限制因素。要設計和部署高度可用和可靠的網路,您必須瞭解電纜網路效能的基本原理和測量引數。本文檔介紹其中一些限制因素,然後討論如何實際最佳化和驗證已部署系統的吞吐量和可用性。
必要條件
需求
本文檔的讀者應瞭解以下主題:
-
有線電纜資料服務介面規範(DOCSIS)
-
射頻(RF)技術
-
Cisco IOS®軟體指令行介面(CLI)
採用元件
本檔案所述內容不限於特定軟體或硬體版本。
本文中的資訊是根據特定實驗室環境內的裝置所建立。文中使用到的所有裝置皆從已清除(預設)的組態來啟動。如果您的網路正在作用,請確保您已瞭解任何指令可能造成的影響。
慣例
如需文件慣例的詳細資訊,請參閱思科技術提示慣例。
背景資訊
位、位元組和鮑率
本節介紹位、位元組和波特之間的差異。bit是BInary digiT的收縮,通常用小寫字母b表示。二進位制數字表示兩種電子狀態:「開啟」或「關閉」狀態,有時也稱為「1s」或「0s」。
位元組以大寫B表示,通常長度為8位。一個位元組可能超過8位,因此8位字更準確地稱為八位位元組。此外,一個位元組中還有兩個小位元組。半位元組定義為4位字,是位元組的一半。
位元率或吞吐量以位元/秒(bps)為測量單位,與訊號通過給定介質的速度相關。例如,該訊號可以是基帶數位訊號,或者可能是調製的模擬訊號,該模擬訊號被調節為表示數位訊號。
一種調製的模擬訊號是正交相移鍵控(QPSK)。 這是一種調制技術,對訊號的相位進行90度處理,以建立四個不同的簽名,如圖1所示。這些簽名稱為符號,它們的速率稱為鮑率。波特等於每秒符號數。
圖1 - QPSK圖 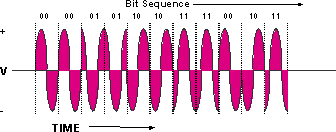
QPSK訊號有四個不同的符號;4等於22。指數給出了可以表示的每週期(符號)的理論位數,在本例中等於2。四個符號代表二進位制數00、01、10和11。因此,如果使用2.56 Msymbols/s的符號速率傳輸QPSK載波,則它稱為2.56 Mbaud,而理論位元率為2.56 Msymbols/s × 2位/符號= 5.12 Mbps。本檔案稍後將進一步說明。
您還可能熟悉術語packets per second(PPS)。 這是一種根據封包來評估裝置輸送量的方式,無論封包是否包含64位元組或1518位元組的乙太網路訊框。有時,網路的「瓶頸」是CPU處理一定量PPS的功率,而不一定是總bps。
什麼是吞吐量?
資料吞吐量首先計算理論上的最大吞吐量,然後得出有效的吞吐量。服務的訂閱者可用的有效吞吐量將始終低於理論最大值,您應嘗試計算此值。
吞吐量取決於許多因素:
-
使用者總數
-
瓶頸速度
-
訪問的服務型別
-
快取和代理伺服器使用情況
-
MAC層效率
-
電纜裝置上的噪音和錯誤
-
許多其他因素
本文檔的目標是解釋如何在DOCSIS環境中最佳化吞吐量和可用性,並解釋影響效能的固有協定限制。如果要測試或排除效能問題,請參閱排除電纜數據機網路中效能緩慢故障。有關上游(US)或下游(DS)埠上的最大建議使用者數的准則,請參閱每個CMTS的最大使用者數是多少?。
傳統有線網路依賴輪詢或載波偵聽多路訪問衝突檢測(CSMA/CD)作為MAC協定。目前的DOCSIS資料機依賴一個預留方案,在該方案中,資料機請求傳送時間,而CMTS根據可用性授予時隙。纜線資料機獲分配一個服務ID(SID),此服務ID(SID)對映到服務類別(CoS)或服務品質(QoS)引數。
在突發時分多路複用接入(TDMA)網路中,如果要保證所有請求使用者有一定的接入速度,您必須限制可以同時傳輸的總纜線資料機(CM)的數量。併發使用者總數基於泊松分佈,這是一種統計概率演算法。
流量工程(在基於電話的網路中使用的統計資料)表示峰值使用率約為10%。此計算超出本檔案的範圍。另一方面,資料流量不同於語音流量;而且當使用者對電腦更加精通,或者通過IP語音(VoIP)和影片點播(VoD)服務更加可用時,情況也會發生變化。為簡單起見,假設50%的峰值用×和20%的使用者實際上同時下載。這也相當於10%的峰值使用率。
所有同時使用的使用者都在爭奪US和DS訪問許可權。對於初始輪詢,許多數據機可以處於活動狀態,但在任何給定時間時刻,在美國只有一台數據機處於活動狀態。這在噪音方面效果很好,因為每次只有一個數據機將其噪音新增到整體效果中。
現行標準的一個固有限制是,當許多數據機連線到單個纜線資料機終端系統(CMTS)時,維護和調配需要一些吞吐量。 這將從活動客戶的實際負載中移除。這稱為keepalive polling,對於DOCSIS,此輪詢通常每20秒發生一次,但可能會更頻繁地發生。此外,每個數據機的美國速度可能受到請求和授予機制的限制,本文檔後面將對此進行說明。
附註: 請記住,對檔案大小的引用以位元組為單位,由8位組成。因此,128 kbps等於16 KBps。同樣地,1 MB實際上等於1,048,576位元組,而不是100萬位元組,因為二進位制數字總是得出2的冪。5 MB檔案實際上為5 × 8 × 1,048,576 = 41.94 Mb,下載時間可能比預期的長。
吞吐量計算
假設使用的是一個DS和六個美國埠的CMTS卡。一個DS埠被拆分以饋送大約12個節點。圖2顯示了此網路的一半。
圖2 — 網路佈局 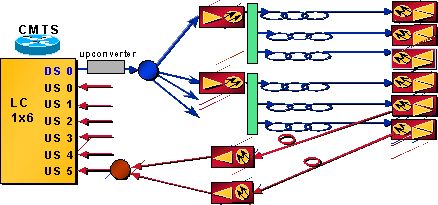
-
每個節點500個家庭× 80%電纜佔用率× 20%數據機佔用率=每個節點80個數據機
-
12個節點×每個節點80個數據機=每個DS埠960個數據機
注意:許多多服務運營商(MSO)現在將他們的系統量化為每節點的家庭通過(HHP)。這是當今架構中唯一不變的,在當今架構中,您可能擁有直接廣播衛星(DBS)使用者購買高速資料(HSD)服務,或者只有電話沒有影片服務。
注意:來自其中每個節點的使用者訊號可能以2:1的比例合併,以便兩個節點饋送一個使用者埠。
-
6個美國埠×每個美國2個節點= 12個節點
-
每個節點80個數據機×每個美國2個節點=每個美國埠160個數據機。
下游
DS符號速率= 5.057 Msymbols/s或Mbaud。如圖3所示,約18%的濾鏡滾出(α)可得到5.057 ×(1 + 0.18)= ~6 MHz寬「幹線棧」。
圖3 — 數字「Haystack」 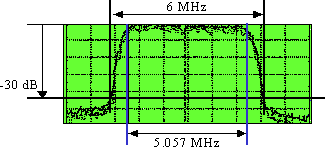
如果使用64-QAM,則64 = 2到第6次功率(26)。 6的指數表示64-QAM的每個符號6位;這表示5.057 × 6 = 30.3 Mbps。在計算整個前向糾錯(FEC)和運動影象專家組(MPEG)開銷後,有效負載將保持約28 Mbps。此負載會進一步降低,因為它也與DOCSIS訊號共用。
註:ITU-J.83 Annex B表示Reed-Solomon FEC的代碼為128/122,這意味著每128個符號有6個開銷符號,因此6/128 = 4.7%。網格編碼是每15個位元組(64-QAM)1個位元組,每20個位元組(256-QAM)1個位元組。這兩個數字分別為6.7%和5%。MPEG-2由188位元組的封包組成,額外負荷為4位元組(有時為5位元組),因此會產生4.5 / 188 = 2.4%。因此,您會看到列出的速度為27 Mbps(64-QAM)和38 Mbps(256-QAM)。請記住,無論是1500位元組的封包還是46位元組的封包,乙太網路封包也具有18位元組的額外負荷。還有6位元組的DOCSIS開銷和IP開銷,這總計大約為額外開銷的1.1%至2.8%,並且可能為DOCSIS MAP流量增加額外開銷的2%。實際測試的64-QAM速度接近26 Mbps。
如果所有960數據機同時下載資料,這種可能性極小,那麼它們各自只能獲得大約28 kbps。如果檢視更現實的情況並假設10%的峰值使用率,您會得到最繁忙時最壞情況的理論吞吐量280 kbps。如果只有一個客戶線上,理論上該客戶可以達到26 Mbps;但是,為TCP而必須傳輸的美國確認會限制DS吞吐量,其他瓶頸(如PC或網路介面卡[NIC])也會變得明顯。 實際上,有線電視公司會將此速率限制在1或2 Mbps,以免造成對可用吞吐量的印象,這種印象在更多使用者註冊後是永遠無法實現的。
上游
DOCSIS使用者對QPSK進行2位/符號的調制後產生了大約2.56 Mbps。這是由1.28 Msymbols/s的符號速率×2位/符號計算的。濾波器α為25%,其頻寬(BW)為1.28 ×(1 + 0.25)= 1.6 MHz。如果使用FEC,請減去約8%。此外還有大約5%到10%的維護開銷、預留的爭用時隙以及確認(「Acks」)。 因此,大約有2.2 Mbps,每個美國埠由160個潛在客戶共用。
注意:DOCSIS層開銷=每64位元組到1518位元組的乙太網幀6位元組(如果使用VLAN標籤,可能為1522位元組)。 這也取決於最大突發大小,以及是否使用串聯或分段。
-
美國FEC可變:~128 / 1518或~12 / 64 = ~8或~18%。約10%用於維護、預留爭用時隙和插孔。
-
BPI安全性或擴展報頭= 0到240位元組(通常為3到7)。
-
前導碼= 9到20位元組。
-
Guardtime >= 5符號= ~2位元組。
假設峰值使用率為10%,則每個使用者的最壞情況負載為2.2 Mbps /(160 × 0.1)= 137.5 kbps。對於典型的住宅資料使用(例如Web瀏覽),您可能不需要像DS那樣多的美國吞吐量。此速度可能足以滿足住宅使用,但不足以用於商業服務部署。
限制因素
有很多限制因素會影響「實際」資料吞吐量。這些範圍從請求和授予週期到DS交錯。瞭解這些限制將有助於實現預期和最佳化。
下游效能 — MAP
傳送到數據機的MAP消息的傳輸會降低DS吞吐量。在DS上傳送時間MAP,以允許數據機請求時間用於使用者傳輸。如果每2毫秒傳送一次MAP,則其合計為1 / 0.002s = 500個MAP/s。如果MAP佔用64位元組,則等於64位元組×每位元組8位× 500 MAP/s = 256 kbps。如果CMTS機箱中的單個刀片上有6個US埠和1個DS埠,則這是6 × 256000 bps = ~1.5 Mbps的DS吞吐量,用於支援所有數據機的MAP消息。假設MAP為64位元組,並且實際上每2毫秒傳送一次。實際上,MAP的大小可能稍大,這取決於調制方案和使用的美國頻寬量。這很容易造成3%到10%的開銷。此外,還有其它系統維護消息在DS通道中傳輸。這也增加了管理費用;然而,這種影響通常可以忽略不計。由於CPU需要跟蹤所有MAP,MAP消息可能會給中央處理器(CPU)以及DS吞吐量效能帶來負擔。
當您在同一使用者上放置任何TDMA和標準分碼多重進接(S-CDMA)通道時,CMTS必須為每個物理埠傳送「雙對映」。因此,DS MAP頻寬消耗增加了一倍。這是DOCSIS 2.0規範的一部分,並且這是互操作性所必需的。此外,美國的通道描述符(US channel descriptors)和其他美國控制消息也翻了一番。
上游效能 — DOCSIS延遲
在美國路徑中,CMTS和CM之間的請求和授權週期最多只能利用其他每個MAP,這取決於來回時間(RTT)、MAP的長度和MAP的提前時間。這是因為受DS交織影響的RTT,以及DOCSIS僅允許數據機在任何給定時間具有未處理的單個請求,以及與之關聯的「請求授予延遲」。此延遲歸因於CM和CMTS之間的通訊,後者依賴於協定。簡而言之,CM必須先向CMTS請求許可權才能傳送資料。CMTS必須為這些請求提供服務,檢查MAP排程程式的可用性,並將其排隊等待下一次單播傳輸機會。這種往返通訊由DOCSIS協定強制執行,會產生這樣的延遲。數據機可能錯過所有其它MAP,因為它正在等待授權從其上次請求返回到DS。
2毫秒的MAP間隔會導致每秒500個MAP / 2 =每秒約250個MAP機會,因此會產生250個PPS。500個MAP除以2,因為在一個「真實」工廠中,請求和授權之間的RTT將遠遠超過2毫秒。它可能超過4毫秒,這將是MAP的每一個機會。如果由1518位元組的乙太網路訊框組成的典型封包以250 PPS的速度傳送,則相當於3 Mbps左右,因為一個位元組有8位。因此,這是單個數據機對美國吞吐量的實際限制。如果限製為大約250 PPS,那麼如果資料包較小(64位元組)該怎麼辦?這只有128 kbps。這就是連線有幫助的地方;請參閱本檔案的級聯和分段效果一節。
根據美國通道使用的符號速率和調制方案,傳送1518位元組資料包可能需要5毫秒。如果向CMTS傳送資料包需要超過5毫秒,則CM將錯過DS上大約3個MAP機會。現在PPS只有165左右。如果減少MAP時間,可能會出現更多的MAP消息,但會增加更多的DS開銷。更多MAP報文將為美國傳輸帶來更多機會,但是在一個真正的混合光纖同軸電纜(HFC)裝置中,反正您會錯過更多的機會。
幸運的是,DOCSIS 1.1新增了未經請求的授權服務(UGS),它允許語音流量避免此請求和授權週期。相反,語音資料包每10或20毫秒排程一次,直到呼叫結束。
註:當CM向US傳輸大資料塊(例如,20 MB的檔案)時,它將依附於資料包中的頻寬請求,而不是使用離散請求,但數據機仍然必須執行請求和授予週期。通過搭載功能,可以在專用時段(而不是爭用時段)隨資料傳送請求,從而消除衝突和損壞的請求。
TCP還是UDP?
當測試吞吐量效能時,經常被忽略的一點是實際使用的協定。它是面向連線的協定(如TCP)還是無連線協定(如使用者資料包協定(UDP))?UDP傳送與接收品質無關的資訊。這通常稱為「盡力交付」。如果錯誤接收了某些位,則您可以執行操作並轉到下一個位。TFTP是此盡力協定的另一個示例。這是即時音訊或影片流的一個典型協定。另一方面,TCP需要確認以證明已傳送的資料包正確接收。FTP就是一個例子。如果網路維持得很好,通訊協定可能足夠動態,足以在要求確認之前連續傳送更多封包。這稱為「增加視窗大小」,這是傳輸控制協定的標準部分。
注意:關於TFTP,需要注意的一點是,儘管它使用UDP,所以開銷較少,但它通常使用步進ack方法,這對於吞吐量非常不利。這意味著不會存在多個未完成的資料包。因此,它永遠不是真正吞吐量的良好測試。
這裡的一點是,DS流量將以更多確認的形式生成美國流量。此外,如果使用者短暫中斷導致TCP確認丟失,則TCP流將減慢。使用UDP就不會發生這種情況。如果美國路徑被切斷,CM將在約30秒後最終無法執行keepalive輪詢,並且它將開始再次掃描DS。TCP和UDP都會經歷短暫的中斷,因為TCP資料包將排隊或丟失,並且會保留DS UDP流量。
美國的吞吐量也會限制DS吞吐量。例如,如果DS流量通過同軸或衛星傳輸,而美國流量通過電話線路傳輸,則28.8 kbps的美國吞吐量可以將DS吞吐量限製為小於1.5 Mbps,即使它可能已被通告為最大10 Mbps。這是因為低速連結會增加確認使用者流量的延遲,進而導致TCP減慢DS流量。為了幫助緩解這個瓶頸問題,Telco Return利用點對點通訊協定(PPP)使確認量大大減少。
DS上的MAP生成會影響美國的請求和授權週期。處理TCP流量時,確認還必須經過請求和授予週期。如果確認沒有在美國級聯,DS可能會受到嚴重阻礙。例如,「遊戲玩家」可能在DS上以512位元組資料包傳送流量。如果美國限製為234 PPS,且DS是每次確認2個資料包,則等於512 × 8 × 2 × 234 = 1.9 Mbps。
視窗的TCP/IP堆疊
典型的視窗速率為2.1至3 Mbps的下載。UNIX或Linux裝置的效能通常更好,因為它們具有改進的TCP/IP堆疊,不需要為收到的其他所有DS資料包傳送一個確認消息。您可以驗證效能限制是否在Windows TCP/IP驅動程式內部。通常,此驅動程式在有限的ack效能期間表現不佳。您可以從Internet使用協定分析器。這個程式旨在顯示您的Internet連線引數,這些引數是從您傳送到伺服器的TCP資料包中直接提取的。協定分析器用作專用的Web伺服器。不過,它並不提供不同的網頁;相反,它用相同的頁面響應所有請求。根據請求客戶端的TCP設定修改這些值。然後,它將控制權轉移至執行實際分析並顯示結果的CGI指令碼。協定分析器可以幫助您檢查下載的資料包的長度是否為1518位元組(DOCSIS最大傳輸單元[MTU]),並檢查使用者確認是否在160到175 PPS附近運行。如果資料包低於這些速率,請更新Windows驅動程式並調整UNIX或Windows NT主機。
您可以更改登錄檔中的設定,以調整Windows主機。首先,您可以增加您的MTU。資料包大小(稱為MTU)是指網路上單個物理幀中可傳輸的最大資料量。乙太網路的MTU為1518位元組;PPPoE為1492;而對於撥號連線,則通常為576。不同之處在於,當使用較大的資料包時,開銷會較小,路由決策也較少,而客戶端的協定處理和裝置中斷也較少。
每個傳輸單元由報頭和實際資料組成。實際資料稱為最大片段大小(MSS),它定義了可以傳輸的TCP資料的最大片段。實質上,MTU = MSS + TCP/IP標頭。因此,您可能希望將MSS調整為1380,以反映每個資料包中的最大有用資料。此外,調整目前的MTU和MSS設定後,您可以最佳化預設接收視窗(RWIN):協定分析器將建議最佳值。協定分析器還可以幫助您確保這些設定:
不同的網路協定可以從Windows登錄檔中的不同網路設定中獲益。纜線資料機的最佳TCP設定似乎與Windows中的預設設定不同。因此,每個作業系統都有有關如何最佳化登錄檔的特定資訊。例如,Windows 98及更高版本在TCP/IP堆疊中有一些改進。其中包括:
-
大視窗支援,如RFC1323中所述

-
選擇性確認(SACK)支援
-
快速重傳和快速恢復支援
Windows 95的WinSock 2更新支援TCP大視窗和時間戳,這意味著如果您將原始Windows Socket更新到版本2,則可以使用Windows 98建議。Windows NT與Windows 9x在處理TCP/IP的方式上略有不同。請記住,如果您應用Windows NT調整,效能提升會比Windows 9x更少,僅僅因為NT更適合網路。
但是,要更改Windows登錄檔,需要具備一定的Windows自定義能力。如果您對編輯登錄檔不滿意,則需要從Internet下載「準備使用」修補程式,該修補程式可以自動設定登錄檔中的最佳值。要編輯登錄檔,必須使用編輯器,例如Regedit(選擇START > Run,然後在Open欄位中鍵入Regedit)。
效能改進因素
吞吐量確定
有許多因素會影響資料吞吐量:
-
使用者總數
-
瓶頸速度
-
訪問的服務型別
-
快取伺服器使用情況
-
MAC層效率
-
電纜裝置上的噪音和錯誤
-
許多其他因素,例如Windows TCP/IP驅動程式內部的限制
共用「管道」的使用者越多,服務速度就越慢。此外,瓶頸可能是您正在訪問的網站,而不是您的網路。考慮到使用的服務,就時間而言,定期的電子郵件和網上衝浪效率非常低。如果使用影片流,則此類服務需要更多的時隙。
您可以使用代理伺服器將某些經常下載的站點快取到您區域網中的電腦,以幫助緩解整個Internet上的流量。
雖然「保留和授予」是DOCSIS資料機的首選方案,但對每個資料機的速度有限制。與輪詢或純CSMA/CD相比,此方案對於住宅使用效率更高。
提高訪問速度
許多系統正在將每節點家庭數比率從1000到500到250降低到無源光網路(PON)或光纖到戶(FTTH)。如果設計正確,PON可以在每個節點上最多傳遞60個人,且不會附加任何主動元件。FTTH正在一些地區接受測試,但對大多數使用者而言,它仍然非常昂貴。實際上,如果減少每個節點的家庭數量,但仍合併頭端接收器的話,情況可能會更糟。兩個光纖接收器不如一個接收器,但每根光纖的家庭數量越少,您遇到來自入口的鐳射切割的可能性就越小。
最明顯的分割方法是增加更多的光纖裝置。一些新的設計將每個節點的家庭數量減少到50至150個HHP。不管怎樣,如果在頭端(HE)再次合併每個節點,減少主目錄數也沒有好處。如果在HE中合併兩個每節點500個家庭的光鏈路並共用同一個CMTS US埠,這實際上可能比使用每節點1000個家庭的光鏈路更糟糕。
很多時候,即使有大量的主動鏈路回流,光鏈路仍是限制噪音的來源。您必須對服務進行分段,而不僅僅是每個節點的家庭數量。減少每個CMTS埠或服務的家庭數量需要更多資金,但尤其會緩解這種瓶頸。每個節點家庭數量減少的好處在於噪音和入口更少,從而能夠導致鐳射剪輯,而且以後更容易分段到更少的美國埠。
DOCSIS為DS和US指定了兩種調制方案,並在使用者路徑中使用五種不同的頻寬。不同的碼元速率是0.16、0.32、0.64、1.28和2.56 Msymbols/s,使用不同的調制方案,例如QPSK或16-QAM。這允許靈活地選擇所需的吞吐量與使用的返回系統所需的穩定性。DOCSIS 2.0增加了更大的靈活性,本文檔稍後將對此進行擴展。
還有跳頻的可能性,它允許「非通訊者」切換到不同的頻率。這裡的折衷方案是,必須分配更多的頻寬冗餘,並且希望「其他」頻率在跳建立之前是乾淨的。有些製造商設定數據機「先看再跳」。
隨著技術的進步,人們會找到方法來更有效地壓縮,或用更高級的協定(要麼更可靠,要麼頻寬要求較低)來傳送資訊。這可能會引發DOCSIS 1.1 QoS布建、負載標頭抑制(PHS)或DOCSIS 2.0功能的使用。
健壯性和吞吐量之間總是存在取捨關係。您離開網路的速度通常與使用的頻寬、分配的資源、抗干擾的魯棒性或成本有關。
通道寬度和調制
由於前面解釋的DOCSIS延遲,美國的吞吐量似乎限製為大約3 Mbps。此外,將美國頻寬增加到3.2 MHz或調制增加到16-QAM(理論吞吐量為10.24 Mbps)似乎也無關緊要。增加通道BW和調制不會顯著增加每個資料機的傳輸速率,但允許更多資料機在通道上傳輸。請記住,US是基於TDMA的時隙爭用介質,其中CMTS授予時隙。更多通道BW意味著更多US bps,這意味著可以支援更多數據機。因此,增加美國通道頻寬確實很重要。此外,請記住,1518位元組的封包在美國僅佔用1.2毫秒的線路時間,有助於RTT延遲。
您也可以將DS調制更改為256-QAM,這樣會使DS上的總吞吐量增加40%,並降低對美國效能的交織延遲。但是,請記住,在進行此更改時,您將暫時斷開系統上的所有數據機。
 注意:在更改DS調制之前,應特別小心。您應該對DS頻譜進行徹底的分析,以驗證您的系統是否支援256-QAM訊號。否則可能會嚴重降低電纜網路效能。
注意:在更改DS調制之前,應特別小心。您應該對DS頻譜進行徹底的分析,以驗證您的系統是否支援256-QAM訊號。否則可能會嚴重降低電纜網路效能。
注意:發出cable downstream modulation {64qam | 256qam} 命令將DS調制更改為256-QAM:
VXR(config)# interface cable 3/0 VXR(config-if)# cable downstream modulation 256qam
有關美國調制配置檔案和返迴路徑最佳化的詳細資訊,請參閱如何提高返迴路徑可用性和吞吐量。另請參閱在Cisco CMTS上配置電纜調制配置檔案。在預設混合配置檔案中將「Short and Long Interval Usage Codes(IUC)」的uw8更改為uw16。
注意:在增加通道寬度或更改美國調制之前,應特別小心。您應該使用頻譜分析器對美國頻譜進行徹底分析,以找到具有足夠的載波雜訊比(CNR)以支援16-QAM的足夠寬的頻帶。如果未能如此,可能會嚴重降低電纜網路效能或導致整個美國網路中斷。
注意:發出cable upstream channel-width命令以增加US通道寬度:
VXR(config-if)# cable upstream 0 channel-width 3200000
請參閱進階頻譜管理。
交織效果
放大器電源和DS路徑上電源供電的突發電雜訊會導致塊錯誤。這可能會導致比由熱雜訊傳播的錯誤更嚴重的吞吐量品質問題。為了儘量減小突發錯誤的影響,使用了稱為交織的技術,該技術隨時間傳播資料。由於傳送端上的符號是混合的,然後在接收端重組,因此錯誤會分散出現。FEC對分散的錯誤非常有效。使用交織時,相對較長的干擾突發導致的錯誤仍然可以通過FEC進行糾正。由於大多數錯誤都發生在突發中,因此這是提高錯誤率的有效方法。
注意:如果增加FEC交織值,則會在網路中增加延遲。
DOCSIS指定了五個不同的交織級別(EuroDOCSIS只有一個級別)。128:1是最高交織量,8:16是最低交織量。128:1表示由128個符號組成的128個碼字將以1對1基進行混合。8:16表示每個碼字將16個符號保留在一行中,並且與7個其它碼字中的16個符號互混合。
下游交織器延遲的可能值如下(以微秒(µs或秒)為單位:
| I(分接頭數) | J(增量) | 64-QAM | 256-QAM |
|---|---|---|---|
| 8 | 16 | 220 | 150 |
| 16 | 8 | 480 | 330 |
| 32 | 4 | 980 | 680 |
| 64 | 2 | 2000 | 1400 |
| 128 | 1 | 4000 | 2800 |
交織不會像FEC那樣增加開銷位;但它確實會增加延遲,這可能會影響語音和即時影片。它還會增加請求和授權RTT,這可能會導致您從其他每個MAP機會轉到每第三個或第四個MAP。這是次要效果,且是可能導致峰值使用者資料吞吐量降低的效果。因此,當值設定為低於典型預設值32時,您可以稍微增加美國吞吐量(以每個數據機的PPS方式)。
作為脈衝雜訊問題的解決方法,交織值可以增加到64或128。但是,當您增加此值時,效能(吞吐量)可能會下降,但DS中的雜訊穩定性會提高。換句話說,要麼該工廠必須維護完好;或者在DS中看到更多無法糾正的錯誤(丟失的資料包),以至於數據機開始連線鬆動,並且存在更多的重新傳輸。
當您增加交織深度以補償有雜訊的DS路徑時,您必須將峰值的CM US吞吐量減少考慮在內。在多數住宅案例中,這不是一個問題,但最好理解兩者之間的取捨。如果您在4毫秒處達到最大交織器深度128:1,這將對美國吞吐量產生顯著的負面影響。
註:64-QAM與256-QAM的延遲不同。
您可以發出cable downstream interleave-depth {8 | 16 | 32 | 64 | 128} 指令。以下範例將交錯深度降低到8:
VXR(config-if)# cable downstream interleave-depth 8
注意:實施此命令後,將斷開系統中所有數據機的連線。
為了使用者對雜訊的穩健性,DOCSIS資料機允許可變或無FEC。當您關閉US FEC時,您將能夠消除一些開銷並允許更多資料包通過,但代價是對雜訊的魯棒性。與突發型別相關具有不同量的FEC也是有利的。突發量是用於實際資料還是用於站點維護?資料包是否由64位元組或1518位元組組成?您可能希望對較大的資料包進行更多保護。還有一點是收益遞減;例如,從7%更改為14%的FEC可能只會增加0.5 dB的魯棒性。
目前在美國沒有交錯,因為傳輸是以猝發方式進行的,並且突發內的延遲不足以支援交錯。一些晶片製造商為DOCSIS 2.0支援新增此功能,如果您考慮來自家電的所有脈衝噪音,該功能可能會產生巨大影響。美國的交織將使FEC更有效地工作。
動態對映升級
Dynamic Map Advance在MAP中使用動態前瞻時間,可顯著改善每個數據機的使用者吞吐量。Dynamic Map Advance是一種根據與特定美國埠關聯的最遠的CM自動調整MAP中前瞻時間的演算法。
請參閱電纜對映升級(動態還是靜態?),獲取有關對映升級的詳細說明。
若要確認Map Advance是否為Dynamic,請發出show controllers cable slot/port upstream port 命令:
Ninetail# show controllers cable 3/0 upstream 1 Cable3/0 Upstream 1 is up Frequency 25.008 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps Spectrum Group is overridden BroadCom SNR_estimate for good packets - 28.6280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2809 Ranging Backoff automatic (Start 0, End 3) Ranging Insertion Interval automatic (60 ms) Tx Backoff Start 0, Tx Backoff End 4 Modulation Profile Group 1 Concatenation is enabled Fragmentation is enabled part_id=0x3137, rev_id=0x03, rev2_id=0xFF nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 8 Minislot Size in Symbols = 64 Bandwidth Requests = 0xE224 Piggyback Requests = 0x2A65 Invalid BW Requests= 0x6D Minislots Requested= 0x15735B Minislots Granted = 0x15735F Minislot Size in Bytes = 16 Map Advance (Dynamic) : 2454 usecs UCD Count = 568189 DES Ctrl Reg#0 = C000C043, Reg#1 = 17
如果您到達前面提到的8的交織深度,則您可以進一步減少對映推進,因為它具有更少的DS延遲。
合併和分段效果
DOCSIS 1.1和某些當前的1.0裝置支援稱為串聯的新功能。DOCSIS 1.1也支援分段。串連允許將多個較小的DOCSIS幀合併到一個較大的DOCSIS幀中,並與一個請求一起傳送。
由於請求的位元組數最多為255個最小位元組,而通常每個最小位元組有8或16個位元組,因此在一個美國傳輸間隔中可傳輸的最大位元組數大約為2040或4080位元組。此數量包括所有FEC和物理層開銷。因此,乙太網成幀的實際最大突發量接近其90%,並且與分段授權無關。如果在2-tick minislot時使用3.2 MHz的16-QAM,minislot將為16位元組。這使限製為16 × 255 = 4080位元組 — 10%物理層開銷= ~3672位元組。要進一步連線,可以將最小批次更改為4或8個刻度,並將「最大集中突發」設定為8160或16,320。
一個警告是,傳送的最小突發量將為32或64個位元組,而此較粗的粒度在資料包被切割為小批次時,將產生更多舍入錯誤。
除非使用分段,否則VXR機箱中的MC28C或MC16x卡的最大使用者突發量應設定為小於4000位元組。此外,如果執行VoIP,請將DOCSIS 1.0數據機的最大突發量設定為小於2000位元組。這是因為1.0資料機無法進行分段,且2000位元組太長,UGS流無法正確傳輸,因此您可能會收到語音抖動。
因此,雖然串連對於大資料包可能不太有用,但它對於所有那些短TCP確認來說是一種極好的工具。如果每個傳輸機會允許多個資料包,則連線將基本PPS值增加該倍數。
連線資料包時,較大的資料包的序列化時間會更長,從而影響RTT和PPS。因此,如果您通常得到250個PPS來傳輸1518位元組的資料包,在連線時它將不可避免地丟失;但現在,每個級聯資料包的總位元組數更多。如果可以串接四個1518位元組的封包,則使用3.2 MHz的16-QAM傳送至少需要3.9毫秒。DS交織和處理的延遲會增加,並且DS MAP可能只是每8毫秒左右一次。PPS將降低到114,但現在您有4個連線,使PPS顯示為456;這樣吞吐量為456 × 8 × 1518 = 5.5 Mbps。考慮一個「博弈」示例,串接可以允許只傳送一個請求就傳送多個美國資料包,這將使DS TCP傳輸更快。假設此CM的DOCSIS配置檔案的Max US Burst設定為2000位元組,並假設數據機支援串聯:cm理論上可以連線31個64位元組的ack。由於這個巨大的總封包將花一些時間從CM傳輸到CMTS,因此PPS將會相應地下降。與使用小資料包的234個PPS相比,使用大資料包的PPS更接近92個PPS。92 PPS × 31個埠= 2852 PPS(有可能)。這相當於大約512位元組DS封包× 8位元組× 2封包每包× 2852位元組每秒= 23.3 Mbps。然而,大多數淨現值比率將比這低得多。
在美國,CM理論上有512位元組× 8位/位元組× 110 PPS × 3個資料包串聯= 1.35 Mbps。這些數字比不合併獲得的原始數字要好得多。不過,碎片化時小批次舍入的效果更差,因為每個碎片都有舍入點。
注意:Broadcom存在較舊的問題,它不會連線兩個資料包,但可以連線三個資料包。
若要利用串連的優勢,您需要執行Cisco IOS軟體版本12.1(1)T或12.1(1)EC或更新版本。如果可能,請嘗試將數據機與基於Broadcom 3300的設計結合使用。要確保CM支援串聯,請在CMTS上發出show cable modem detail、show cable modem mac或show cable modem verbose 命令。
VXR# show cable modem detail Interface SID MAC address Max CPE Concatenation Rx SNR Cable6/1/U0 2 0002.fdfa.0a63 1 yes 33.26
要開啟或關閉串聯,請發出[no] cable upstream n concatenation 命令,其中n指定美國埠號。對於電纜介面線卡上的第一個美國埠,有效值以0開頭。
註:有關DOCSIS 1.0與1.1以及最大突發大小設定的串聯問題的詳細資訊,請參閱最大上游突發引數歷史記錄。另請記住,要使更改生效,必須重新啟動數據機。
單數據機速度
如果目標是連線大幀並實現每個數據機的最佳速度,您可以將最小位元組更改為32位元組,以允許最大突發量為8160。此方法的缺點在於它意味著傳送過的最小資料包將為32位元組。這對於長度只有16位元組的較小的US資料包(例如Requests)來說不是非常有效。由於請求處於爭用區域,如果請求變得更大,則發生衝突的可能性更高。當將資料包分割成最小塊時,也會增加更多的最小塊舍入錯誤。
此數據機的DOCSIS配置檔案需要具有大約6100的最大流量突發和最大集中突發設定。這將允許連線四個1518位元組的幀。數據機還需要支援分段,以便將其分解成更易於管理的片段。由於下一個請求通常是被動備份的,並且會位於第一個片段中,因此數據機可能會獲得比預期更高的PPS速率。與CM嘗試傳送一個長串連資料包相比,每個片段的序列化時間更短。
必須說明一些可能影響每個數據機速度的設定。最大流量突發用於1.0 CM,應設定為1522。有些CM需要大於1600,因為它們包含其他不應包含的開銷。最大集中突發影響同樣可以分段的1.1數據機,因此它們可以將多個幀與一個請求串聯,但仍會分段為2000位元組的資料包以考慮VoIP。您可能需要將Max Traffic Burst和Max Concat Burst設定為彼此相等,否則某些CM將不會聯機。
CMTS中可能會產生影響的一個命令是cable upstream n rate-limit token-bucket shaping 命令。此命令可幫助管制不會按照配置檔案設定中的指示進行自我管制的CM。管制可能會延遲資料包,因此如果您懷疑它正在限制吞吐量,請關閉此功能。這可能與將最大流量突發設定為與最大流量突發相同有關,因此可能需要進行更多測試。
Toshiba沒有串接或分段,因為它沒有在CM中使用Broadcom晶片集。它使用Libit並且現在使用TI,在CM中高於PCX2200。Toshiba還在授權前傳送下一個請求,以實現更高的PPS。這工作正常,但請求未被動備份,並且處於爭用狀態;當多個CM位於同一個美國時,可以丟棄。
cable default-phy-burst 命令允許將CMTS從DOCSIS 1.0 IOS軟體升級為1.1代碼,而無需CM註冊失敗。通常,DOCSIS配置檔案的預設最大流量突發值為0或為空,這將導致數據機在註冊時失敗,並顯示reject(c)。這是拒絕的CoS,因為0表示無限最大突發,1.1代碼不允許此情況(因為VoIP服務和最大延遲、延遲和抖動)。 cable default-phy-burst命令會覆蓋DOCSIS配置檔案設定0,並且這兩個數字中較小的值優先。預設設定為2000,現在最大值為8000,這將允許連線五個1518位元組的幀。可以將其設定為0將其關閉:
cable default-phy-burst 0
每個數據機速度測試的一些建議
-
在6.4 MHz通道下,使用美國的64-QAM高級分時多重進接(A-TDMA)。
-
使用最小批大小2。DOCSIS限製為每突發量255最小批次,因此255 × 48位元組/最小批次= 12240最大突發量× 90% = ~11,000位元組。
-
使用可分段和串聯且具有全雙工FastEthernet連線的CM。
-
將DOCSIS配置檔案設定為不最小值,但上下最大值為20 MB。
-
關閉US速率限制令牌桶調節。
-
發出cable upstream n data-backoff 3 5 命令。
-
將Max Traffic Burst和Max Concat Burst設定為11000位元組。
-
在DS上使用256-QAM和16交錯(另試用8)。 這樣可以減少MAP的延遲。
-
使用正確分段的IOS軟體版本15(BC2)映像,然後發出cable upstream n fragment-force 2000 5 命令。
-
將UDP流量推入CM並遞增,直到找到最大值。
-
如果要推送TCP流量,請使用多台PC通過一個CM。
結果
-
Terayon TJ735提供15.7 Mbps。由於每個級聯幀的位元組更少,CPU效能更好,因此這種速度可能很快。它似乎第一個幀有一個13位元組的串連報頭,後面有一個6位元組的報頭,有16位元組的片段報頭和內部8200位元組的最大突發量。
-
Motorola SB5100提供了18 Mbps。在DS上,1418位元組封包和8個交織器也獲得了19.7 Mbps。
-
Toshiba PCX2500提供了8 Mbps,因為它似乎具有4000位元組的內部最大突發限制。
-
Ambit的業績與摩托羅拉相同:18 Mbps。
-
當與其他CM流量競爭時,其中一些速率可能會下降。
-
確保1.0 CM(不能分段)的最大突發小於2000。
-
Motorola和Ambit CM實現了27.2 Mbps,98%的美國利用率。
新建片段命令
cable upstream n fragment-force fragment-threshold number-of-fragments
| 引數 | 說明 |
|---|---|
| 否 | 指定上游埠號。對於電纜介面線卡上的第一個上游埠,有效值以0開頭。 |
| fragment-threshold | 將觸發分段的位元組數。有效範圍為0到4000,預設值為2000位元組。 |
| 片段數量 | 每個分段幀被拆分到的大小相等的片段數。有效範圍為1到10,預設值為3個片段。 |
DOCSIS 2.0優勢
DOCSIS 2.0未對DS新增任何更改,但為美國增加了許多更改。DOCSIS 2.0中的高級物理層規範具有以下新增功能:
-
8-QAM、32-QAM和64-QAM調制方案
-
6.4 MHz通道寬度
-
最高16 T位元組的FEC
它還允許在數據機中使用預均衡的24個分接頭和美國的交錯。這增加了反射、通道內傾斜、組延遲和美國突發雜訊的魯棒性。此外,CMTS中的24分路均衡功能有助於較舊的DOCSIS 1.0數據機。除了A-TDMA之外,DOCSIS 2.0還增加了S-CDMA的使用。
64-QAM更高的頻譜效率可以更好地利用現有通道,提高容量。這樣可在美國方向提供更高的吞吐量,並且每個數據機的速度稍好一些,PPS也更佳。使用6.4 MHz的64-QAM有助於將大資料包傳送到CMTS比正常速度快得多,因此序列化時間將很短,並將建立更好的PPS。更寬的通道能夠產生更好的統計多路複用。
使用A-TDMA可以獲得的理論峰值US速率大約為27 Mbps(聚合)。 這取決於開銷、資料包大小等。請記住,對更高總吞吐量的更改允許更多人共用,但不必增加每個數據機的速度。
如果在美國運行A-TDMA,則這些資料包的速度會快得多。6.4 MHz的64-QAM將允許在美國更快地串列化級聯的資料包,並實現更好的PPS。如果將2滴答最小位元與A-TDMA一起使用,則每個最小位元將得到48位元組,其中48 × 255 = 12240是每個請求的最大突發量。64-QAM、6.4 MHz、2-tick minislot、10,000 Max Concat Burst和300 Dynamic map advance safety可提供約15 Mbps。
所有當前的DOCSIS 2.0矽實施都採用入口取消,儘管它不是DOCSIS 2.0的一部分。這樣可以使服務針對最壞情況下的裝置損壞而保持強健性,開啟頻譜的未使用部分,並為生命線服務新增一種保險。
其他因素
還有其他一些因素可能會直接影響電纜網路的效能:QoS配置檔案、雜訊、速率限制、節點組合、過度使用等。疑難排解纜線資料機網路中的效能緩慢中,會詳細討論其中的大多數問題。
此外還有可能並不明顯的電纜數據機限制。纜線資料機可能具有CPU限制或與PC的半雙工乙太網路連線。根據資料包大小和雙向通訊流,這可能是一個不考慮的瓶頸。
檢驗吞吐量
對數據機所在的介面發出show cable modem命令。
ubr7246-2# show cable modem cable 6/0
MAC Address IP Address I/F MAC Prim RxPwr Timing Num BPI
State Sid (db) Offset CPE Enb
00e0.6f1e.3246 10.200.100.132 C6/0/U0 online 8 -0.50 267 0 N
0002.8a8c.6462 10.200.100.96 C6/0/U0 online 9 0.00 2064 0 N
000b.06a0.7116 10.200.100.158 C6/0/U0 online 10 0.00 2065 0 N
發出show cable modem mac 命令以檢視資料機的功能。這顯示數據機可以做什麼,但不一定是它正在做什麼。
ubr7246-2# show cable modem mac | inc 7116
MAC Address MAC Prim Ver QoS Frag Concat PHS Priv DS US
State Sid Prov Saids Sids
000b.06a0.7116 online 10 DOC2.0 DOC1.1 yes yes yes BPI+ 0 4
發出show cable modem phy命令以檢視資料機的實體層屬性。只有在CMTS上配置了remote-query時,才會顯示其中一些資訊。
ubr7246-2# show cable modem phy
MAC Address I/F Sid USPwr USSNR Timing MicroReflec DSPwr DSSNR Mode
(dBmV)(dBmV) Offset (dBc) (dBmV)(dBmV)
000b.06a0.7116 C6/0/U0 10 49.07 36.12 2065 46 0.08 41.01 atdma
發出show controllers cable slot/port upstream 命令以檢視資料機的目前使用者設定。
ubr7246-2# show controllers cable 6/0 upstream 0 Cable6/0 Upstream 0 is up Frequency 33.000 MHz, Channel Width 6.400 MHz, 64-QAM Sym Rate 5.120 Msps This upstream is mapped to physical port 0 Spectrum Group is overridden US phy SNR_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2066 Ranging Backoff Start 2, Ranging Backoff End 6 Ranging Insertion Interval automatic (312 ms) Tx Backoff Start 3, Tx Backoff End 5 Modulation Profile Group 243 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x02, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 2 Minislot Size in Symbols = 64 Bandwidth Requests = 0x7D52A Piggyback Requests = 0x11B568AF Invalid BW Requests= 0xB5D Minislots Requested= 0xAD46CE03 Minislots Granted = 0x30DE2BAA Minislot Size in Bytes = 48 Map Advance (Dynamic) : 1031 usecs UCD Count = 729621 ATDMA mode enabled
發出show interface cable slot/port service-flow 命令以檢視資料機的服務流。
ubr7246-2# show interface cable 6/0 service-flow
Sfid Sid Mac Address QoS Param Index Type Dir Curr Active
Prov Adm Act State Time
18 N/A 00e0.6f1e.3246 4 4 4 prim DS act 12d20h
17 8 00e0.6f1e.3246 3 3 3 prim US act 12d20h
20 N/A 0002.8a8c.6462 4 4 4 prim DS act 12d20h
19 9 0002.8a8c.6462 3 3 3 prim US act 12d20h
22 N/A 000b.06a0.7116 4 4 4 prim DS act 12d20h
21 10 000b.06a0.7116 3 3 3 prim US act 12d20h
發出show interface cable slot/port service-flow sfid verbose命令,以檢視該特定資料機的特定服務流。這將顯示US或DS流的當前吞吐量以及數據機的配置檔案設定。
ubr7246-2# show interface cable 6/0 service-flow 21 verbose Sfid : 21 Mac Address : 000b.06a0.7116 Type : Primary Direction : Upstream Current State : Active Current QoS Indexes [Prov, Adm, Act] : [3, 3, 3] Active Time : 12d20h Sid : 10 Traffic Priority : 0 Maximum Sustained rate : 21000000 bits/sec Maximum Burst : 11000 bytes Minimum Reserved Rate : 0 bits/sec Admitted QoS Timeout : 200 seconds Active QoS Timeout : 0 seconds Packets : 1212466072 Bytes : 1262539004 Rate Limit Delayed Grants : 0 Rate Limit Dropped Grants : 0 Current Throughput : 12296000 bits/sec, 1084 packets/sec Classifiers : NONE
確保不存在延遲或丟棄的資料包。
發出show cable hop 命令,確認沒有不可糾正的FEC錯誤。
ubr7246-2# show cable hop cable 6/0
Upstream Port Poll Missed Min Missed Hop Hop Corr Uncorr
Port Status Rate Poll Poll Poll Thres Period FEC FEC
(ms) Count Sample Pcnt Pcnt (sec) Errors Errors
Cable6/0/U0 33.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U1 admindown 1000 * * * frequency not set * * * 0 0
Cable6/0/U2 10.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U3 admindown 1000 * * * frequency not set * * * 0 0
如果數據機正在丟棄資料包,則物理裝置會影響吞吐量,必須修復。
摘要
本文檔的前幾節重點介紹在不瞭解對其他功能的影響的情況下脫離上下文獲取效能數字的缺點。雖然您可以微調系統以實現特定的效能度量或克服網路問題,但代價是另一個變數。改變MAPs/s和interleave值可能會得到更好的美國利率,但會犧牲掉直接稅率和穩健性。在真實網路中,減少MAP間隔不會產生太大影響,只會增加CMTS和CM上的CPU和頻寬開銷。採用更多美國FEC會增加美國的開銷。吞吐量、複雜性、穩健性和成本之間總是存在折衷和折衷關係。
如果在美國使用准入控制,這會導致總分配用完後一些數據機沒有註冊。例如,如果美國總使用速度為2.56 Mbps,並且最低保證設定為128k,那麼在准入控制設定為100%的情況下,只有20個數據機能夠在該美國註冊。
結論
您必須知道預期吞吐量,以確定使用者的資料速度和效能。一旦您確定理論上的可能性,就可以設計和管理網路,以滿足電纜系統動態變化的要求。然後,您必須監控實際流量負載,以確定正在傳輸的內容以及何時需要額外的容量來緩解瓶頸。
如果網路部署和管理得當,服務和對可用性的感知可能是有線行業的關鍵差異化機遇。隨著有線公司向多種服務過渡,使用者對服務完整性的期望越來越接近傳統語音服務建立的模型。隨著這種變化,有線電視公司需要採用新的方法和戰略,確保網路符合這種新的模式。現在,我們是一個電信行業,而不僅僅是娛樂提供商,因而有了更高的期望和要求。
雖然DOCSIS 1.1包含可確保高級服務(如VoIP)品質水準的規格,但部署符合此規格的服務的能力將十分困難。因此,有線電視運營商必須徹底瞭解這些問題。必須設計選擇系統元件和網路策略的綜合方法,以確保成功部署真正的服務完整性。
目標是讓更多訂閱者註冊,但不會危及當前訂閱者的服務。如果提供保證每個使用者最小吞吐量的服務級別協定(SLA),則必須提供支援此保證的基礎架構。該行業還希望為商業客戶服務和增加語音服務。隨著這些新市場的面貌和網路的建立,我們需要新的方法:擁有更多埠的CMTS更加密集,分散式CMTS更遠離現場,或介於兩者之間(如為您的房屋增加10baseF)。
無論未來如何發展,網路都會變得更加複雜,技術挑戰也會增加。只有採用及時提供最高級別服務完整性的架構和支援計畫,有線電視業才能應對這些挑戰。
 意見
意見