簡介
本文說明如何在執行維護視窗之前和之後檢查Cisco Prime Access Registrar(CPAR)的運行狀況。
此過程適用於使用NEWTON版本的Openstack環境,其中ESC不管理CPAR,並且直接安裝在Openstack上部署的VM上。
背景資訊
Ultra-M是經過預先打包和驗證的虛擬化移動資料包核心解決方案,旨在簡化VNF的部署。 OpenStack是適用於Ultra-M的Virtualized Infrastructure Manager(VIM),包含以下節點型別:
- 計算
- 對象儲存磁碟 — 計算(OSD — 計算)
- 控制器
- OpenStack平台 — 導向器(OSPD)
Ultra-M的高級架構和涉及的元件如下圖所示:
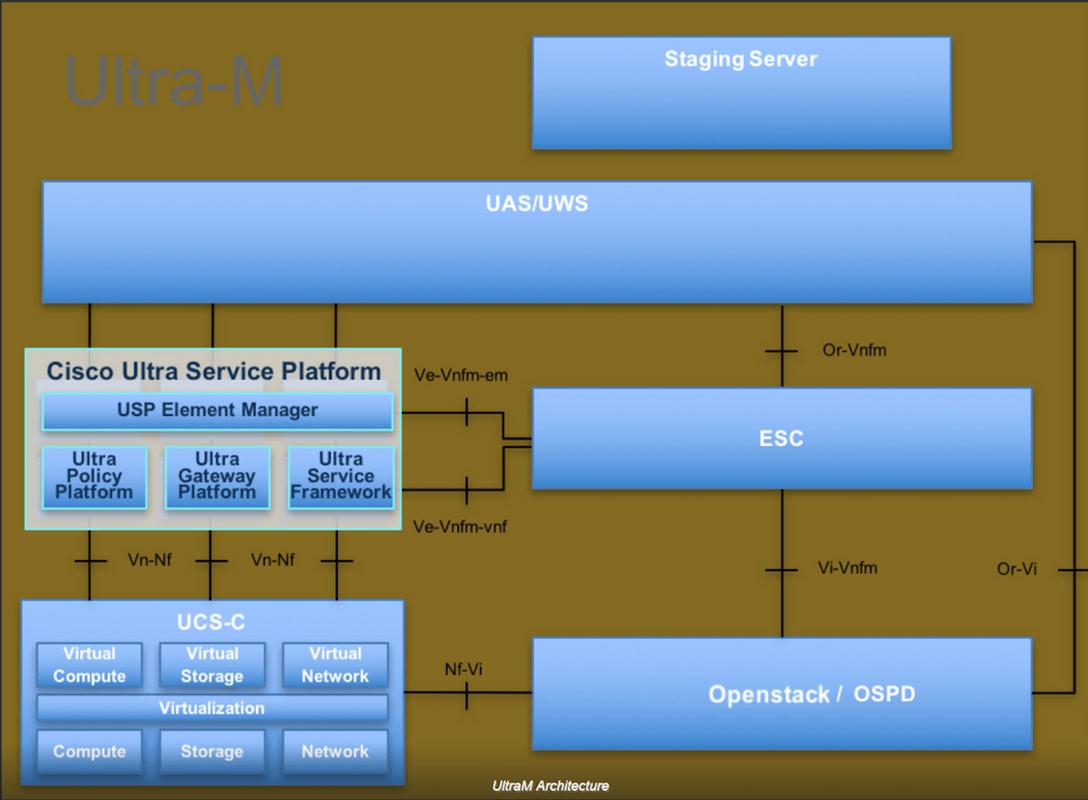
本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細說明了在OpenStack和Redhat作業系統上執行的步驟。
註:為定義本文檔中的過程,需要考慮Ultra M 5.1.x版本。
網路影響
網路或CPAR服務沒有中斷或干擾。
警報
此過程不會觸發任何警報。
運行狀況檢查
通過安全殼層(SSH)連線到伺服器。
在活動之前和之後運行所有這些步驟。
步驟 1.在作業系統級別執行命令/opt/CSCOar/bin/arstatus。
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus
Cisco Prime AR RADIUS server running (pid: 24834)
Cisco Prime AR Server Agent running (pid: 24821)
Cisco Prime AR MCD lock manager running (pid: 24824)
Cisco Prime AR MCD server running (pid: 24833)
Cisco Prime AR GUI running (pid: 24836)
SNMP Master Agent running (pid: 24835)
[root@wscaaa04 ~]#
步驟 2.在作業系統級別執行命令/opt/CSCOar/bin/aregcmd,然後輸入管理員憑據。驗證CPAr Health為10/10,並退出CPAR CLI。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
步驟 3.執行命令netstat | grep diameter並驗證所有DRA連線均已建立。
下面提到的輸出適用於預期存在Diameter連結的環境。如果顯示的連結較少,則表示與需要分析的DRA斷開連線。
[root@aa02 logs]# netstat | grep diameter
tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED
tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED
tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED
tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED
tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
步驟 4.檢查TPS日誌是否顯示CPAR正在處理的請求。以粗體突出顯示的值代表了TPS,這些值是我們需要注意的。
TPS的值不應超過1500。
[root@aaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv
11-21-2017,23:57:35,263,0
11-21-2017,23:57:50,237,0
11-21-2017,23:58:05,237,0
11-21-2017,23:58:20,257,0
11-21-2017,23:58:35,254,0
11-21-2017,23:58:50,248,0
11-21-2017,23:59:05,272,0
11-21-2017,23:59:20,243,0
11-21-2017,23:59:35,244,0
11-21-2017,23:59:50,233,0
步驟 5.在name_radius_1_log中查詢任何錯誤或警報消息。
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
步驟 6.這是用於驗證CPAR進程使用的記憶體量的命令。
top | grep radius
[root@aaa02 ~]# top | grep radius
27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
此突出顯示的值應小於:7Gb,這是應用級別允許的最大值。
步驟 7.以下是用於驗證磁碟利用率的命令:
df -h
[root@aaa02 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_arucsvm51-lv_root 26G 21G 4.1G 84% /
tmpfs 1.9G 268K 1.9G 1% /dev/shm
/dev/sda1 485M 37M 424M 8% /boot
/dev/mapper/vg_arucsvm51-lv_home 23G 4.3G 17G 21% /home
此總值應低於:如果超過80%,則應該低於80%,識別不必要的檔案並對其進行清理。
步驟 8.驗證是否未生成core檔案。
當CPAR無法處理異常時,會在應用程式崩潰時生成核心檔案,並在這兩個位置生成核心檔案。
[root@aaa02 ~]# cd /cisco-ar/
[root@aaa02 ~]# cd /cisco-ar/bin
如果發現上述兩個位置,則不應有任何核心檔案。如果找到,請引發Cisco TAC案例,以識別此類異常的根本原因,並附加核心檔案以進行調試。
 意見
意見