簡介
本文檔介紹如何驗證Tetration Analytics群集的運行狀況。
必要條件
需求
思科建議您瞭解以下主題:
採用元件
本文中的資訊係根據以下軟體和硬體版本:
- 版本2.2.1.x
- 39RU Tetration分析群集
本文中的資訊是根據特定實驗室環境內的裝置所建立。文中使用到的所有裝置皆從已清除(預設)的組態來啟動。如果您的網路正在作用,請確保您已瞭解任何指令可能造成的影響。
背景資訊
Tetration群集由多個UCS C220-M4伺服器上的多個虛擬機器[虛擬機器]上運行的數百個進程(程式)組成。提供了多種服務和功能來幫助監視群集的操作,並在群集可能無法完全正常工作時提醒管理員。
本文檔提供了驗證群集運行狀況時要檢查的內容的檢視。雖然本文的範圍包括驗證運行狀況,但是如果需要操作來幫助解決似乎無法正常運行的問題,請收集快照並與Cisco Tetration解決方案支援TAC團隊建立案例。
用於驗證群集運行狀況的兩個常用工具是Cluster Status和Service Status頁,本文檔中介紹了這兩個工具以及幾個其他系統工具。儘管Bosun critical電子郵件警報通常是向管理員指示群集中可能發生了某種情況的第一個指示之一,但通常最好通過「Cluster Status」和「Service Status」頁來驗證群集的運行狀況。
儘管玻色子警報提供類似於系統日誌的功能,但在某些Tetration版本中,一些關鍵的Bosun警報是在正常運行的群集中觸發的。 使用metric關鍵字通過cisco.com 錯誤搜尋工具搜尋Tetration產品將協助識別特定指標的可能問題。
何時檢查集群的運行狀況:
通常,群集的管理員不必檢查群集的功能。 然而,有時可能需要它。下面列出了幾個示例:
- 當使用者發現使用者介面(UI)中的意外行為時。 這部分基於使用者關於群集應如何運行的知識和經驗,但一些示例在本節操作顯示引數中顯示。
- 當預期可以看到某些資料但無法在UI中顯示時。例如,在檢視資料應顯示的正確範圍和時間範圍時,流資料來自軟體或硬體代理(感測器)。
- 群集的任何計畫的服務、升級或主要操作之前和之後。最佳作法是在進行任何維護之前收集快照,然後在維護之後收集另一個快照,以便在開啟TAC案例時可以使用。這麼做可協助TAC尋找維護期間所做的變更以隔離問題。
附註:在群集上進行系統維護之後的一段時間內某些服務中斷是正常的。在伺服器更換示例中,在該伺服器上運行資料陽極VM時,該時間段可能長達24小時。群集中的正常系統冗餘通常可以緩解單個伺服器更換的負面影響。
驗證Tetration群集操作狀態的不同方法
操作顯示引數
具有群集操作知識和經驗的管理員能夠識別群集在其環境中的正常操作。以下是驗證群集是否正常運行時要查詢的一些示例。
範例 1:可用的最新流時間在當前時間的10分鐘內

範例 2:最新「應用程式工作區」時間在當前時間的10小時內:

範例 3:儀表板內容已填充。

群集狀態
Tetration Analytics群集包括6個(8RU)或36個(39RU)伺服器,具體取決於群集型別。「群集狀態」頁提供伺服器的狀態以及其他裸機伺服器資訊。
Cluster Status頁面位於Maintenance選單(Settings下拉選單)(Settings > Maintenance;左列中的群集狀態。)
附註:在按一下左側列之前,只有圖示可見。
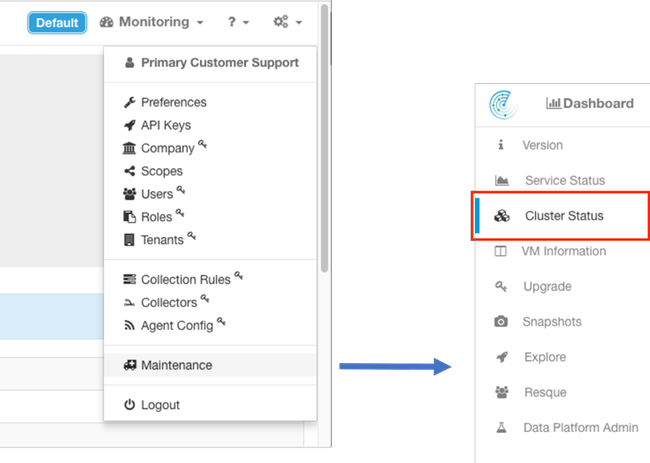
集群上的「集群狀態」頁顯示集群中所有伺服器的清單。 正常工作的伺服器應顯示
State和
Status,如下所示。
附註:映像被截斷到36台伺服器(39RU群集)中的前6台。
如果狀態顯示非活動,這通常指向未通電或可能存在電纜或連線問題的伺服器。
按一下清單中的伺服器時,將顯示有關該特定伺服器的其它資訊,其中包括:
- 在裸機伺服器上運行的例項(虛擬機器)。
- 群集內的專用IP地址。
- 集群內的CIMC IP地址。
- 伺服器上運行的韌體版本(BIOS、CIMC、RAID控制器)。
服務狀態
其 服務狀態 頁面顯示全部 服務在Cisco Tetration Analytics集群中使用的及其依賴性和運行狀況 狀態.
Service Status頁面位於Settings下拉選單中的Maintenance選單。(設定>維護;左列中的服務狀態。)
附註:在按一下左側列之前,只有圖示可見。

預設情況下,「服務狀態」(Service Status)頁面以圖形檢視顯示集群功能和依賴性。如果圖示全部為綠色,則不會檢測到任何錯誤。

如果某個服務顯示為紅色或橙色,則樹檢視將顯示服務清單,並允許您深入檢視該服務的依存關係以及服務狀態功能檢測到的其他詳細資訊。使用TAC開啟案例時,此依賴項錯誤資訊尤為重要須予附註和擷取。
例如,下面是當群集中的某個HDFS DataNode虛擬機器關閉時顯示的清單外觀
附註:由於設計到Tetration群集中的冗餘,對群集可能沒有明顯影響。
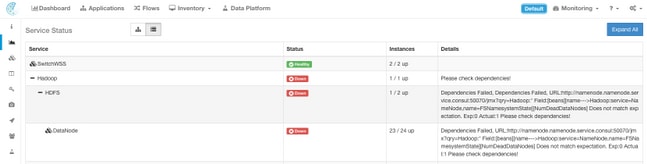
附註:某些服務在執行維護後返回工作狀態可能會有某些延遲。 例如,其上正在運行DataNode虛擬機器例項且已解除授權並重新啟用以進行RMA維護的伺服器可能需要最多24小時才能清除檢測到的問題。
儘管「服務狀態」中的詳細資訊指示在檢測到某些問題時可能會發生的情況,但是如果有任何有關含義和/或可能採取的補救措施的問題,建議開啟TAC案例。
Bosun警報
Bosun是一個開源監控和警報系統,用於Tetration Analytics集群中,以監控集群中運行的服務(啟動時啟動的程式)的各種度量。當服務正常運行時,它會在openTSDB中填充其度量。Bosun程式檢視openTSDB中服務的度量,並應用bosun規則來確定是否對當前度量進行警報。在Monitoring > Sentinel [Alerts]下的群集UI上,可以在本地看到Bosun警報。
當超過該度量的閾值時,Bosun使用電子郵件(傳送到群集站點配置site_bosun_email)來警告群集管理員存在潛在的嚴重情況。Bosun生成三種型別的電子郵件:
關鍵:當Bosun警報規則的度量超過配置的閾值時
正常:一旦度量低於閾值,便會收到「關鍵」電子郵件
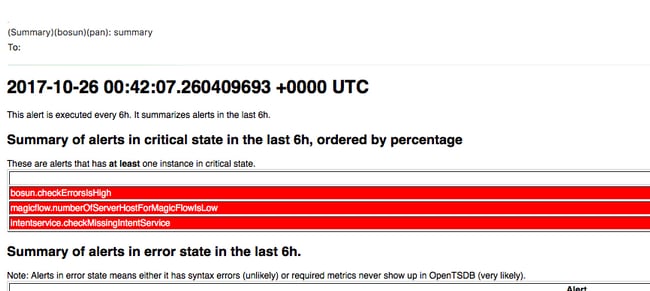
摘要:通常每6小時傳送一次,並在6小時時段內顯示警報摘要
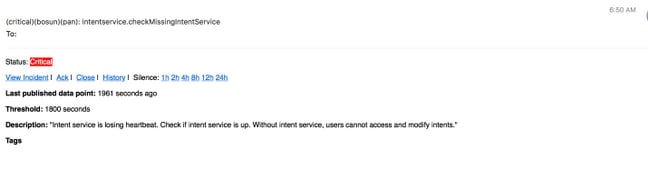
電子郵件警報示例:
嚴重(對於intentservice.checkMissingIntentService度量)
:
正常:
摘要:
嚴重警報包含有關哪些度量、時間、閾值、測量資料點和問題描述的資訊。 例如,當服務出現故障並且不再向openTSDB提供其度量時,可能會生成警報。Bosun嚴重警報的含義和潛在影響可能需要開啟TAC案例以更好地瞭解上下文和解釋警報的含義。
收集快照並開啟TAC案例
Cisco Tetration解決方案團隊專門為Tetration Analytics客戶提供支援。最能幫助TAC工程師進行故障排除的常見專案之一是群集日誌的快照集合。有時,只有快照日誌檔案中包含的資訊才足以瞭解問題。如果沒有,在許多情況下,快照都會提供故障排除過程的起點。
Tetration群集中的快照類似於其他思科產品中的技術支援。 它是來自所有伺服器和虛擬機器的壓縮tarball檔案或日誌檔案,包括:
- 記錄檔
- Hadoop/YARN應用和日誌的狀態
- 警報歷史記錄
- 許多TSDB統計資訊
快照頁面位於「設定」下拉選單中的「維護」選單中。(設定>維護;左列中的快照。)
附註:在按一下左側列之前,只有圖示可見。

快照頁面提供各種選項供您選擇,但除TAC工程師另有指示外,預設值可用於收集快照。
需要修改的一個重要領域是註釋。如果從集群收集了多個快照,並且在Cisco TAC分析期間快照中還提供了新增的註釋,則註釋應提供資訊以指明收集快照的原因。

按一下Create按鈕時,快照進程開始。一次只能建立一個快照,該過程需要幾分鐘才能完成。快照集合的進度條顯示在快照頁面的頂部。
按一下快照頁面上的相應下載連結後,即可將快照下載到使用者的本地系統,如下圖所示:

附註:快照檔案的大小可能高達數百百萬位元組。然後,此檔案可上傳到開放的TAC案例。
相關資訊



 意見
意見