簡介
本文檔描述BFD Hello資料包與應用感知路由隧道統計資訊之間的關係。
必要條件
需求
思科建議您瞭解以下主題:
- Cisco Catalyst軟體定義廣域網路(SD-WAN)。
- 應用感知路由。
- BFD。
採用元件
本文中的資訊是根據特定實驗室環境內的裝置所建立。文中使用到的所有裝置皆從已清除(預設)的組態來啟動。如果您的網路運作中,請確保您瞭解任何指令可能造成的影響。
- Cisco Catalyst SD-WAN管理器。
- Cisco IOS® XE Catalyst SD-WAN邊緣。
背景資訊
雙向轉發檢測(BFD)協定在Cisco IOS-XE Catalyst SD-WAN裝置之間的所有資料平面隧道上運行。此通訊協定用於監控通道的活動性和路徑特徵,例如報告為損失、抖動和延遲的通道效能。
邊緣裝置使用BFD Hello探測器測量隧道上的資料包丟失、抖動和延遲。為每個BFD Hello探測器計算這些統計資訊,並在稱為輪詢間隔的滑動時間視窗內獲取這些統計資訊。
應用感知路由使用這些丟失、延遲和抖動統計資訊,根據策略中設定的要求傳輸流量(稱為SLA類),在該策略中,它確定在選擇傳輸資料的隧道中允許的最大丟失、抖動和延遲。
因此,瞭解度量值的計算方式以及BFD值的變化如何影響隧道效能計算主要是平均損失是非常重要的。BFD引數包括:
| 引數 |
預設值 |
範圍 |
使用 |
| BFD呼叫間隔
|
1秒 |
1到65535秒 |
用於檢測隧道連線的活動性和檢測隧道上的故障的資料包。 |
| 輪詢間隔 |
10分鐘 (60萬毫秒) |
1 - 4,294,967毫秒 |
計算時段度量以提供統計資訊的頻率。 |
| 乘數 |
6 |
1 - 6 |
乘以輪詢間隔以指定計算平均丟失、平均延遲和平均抖動的時間。
此值確定儲存桶的數量。 |
通道效能統計資訊計算
對於設定為預設設定的BFD引數,統計資訊的計算如下:
輪詢間隔/ BFD呼叫間隔= 600,000 ms / 1000 ms = 600 BFD幫助間隔/儲存桶。
由於乘數設定為6,這意味著使用6個儲存段來計算平均延遲、抖動和丟失。預設值等於1小時。此總時間也稱為app-route間隔。
應用路由間隔=輪詢間隔*乘數= 600,000毫秒x 6 = 3,600,000毫秒,等於1小時。
應用感知路由使用應用路由統計資訊的計算來確定資料平面中的更改。為使邊緣裝置能夠利用應用路由統計資訊,必須在設定了最大可接受資料包抖動、丟失和延遲的AAR策略中指定SLA類。這些SLA類在AAR策略中用於根據SLA路由指定應用的流量。
在邊緣裝置中配置後,AAR統計資訊將用於與用所有儲存桶(在整個應用路由間隔內)計算的統計資訊提供的平均丟失、平均延遲和平均抖動進行比較。還必須注意,預設情況下,SLA會在每個輪詢間隔之後每十分鐘更新一次。
要獲得平均損失、平均抖動和平均延遲,使用的方程式為:
平均損失=(所有儲存段上的總損失x 100)/資料包總數。
平均延遲=(所有儲存桶中的總損失)/儲存桶數量。
平均抖動=(所有儲存桶上的總抖動)/儲存桶數量。
可以使用以下命令在CLI中檢視這些值與每個桶的平均值的計算:
vEdge#show app-route stats
cEdge#show sdwan app-route stats
在GUI中,平均丟失、平均延遲和平均抖動只能在Monitor > Overview > Application-Aware Routing部分中檢視。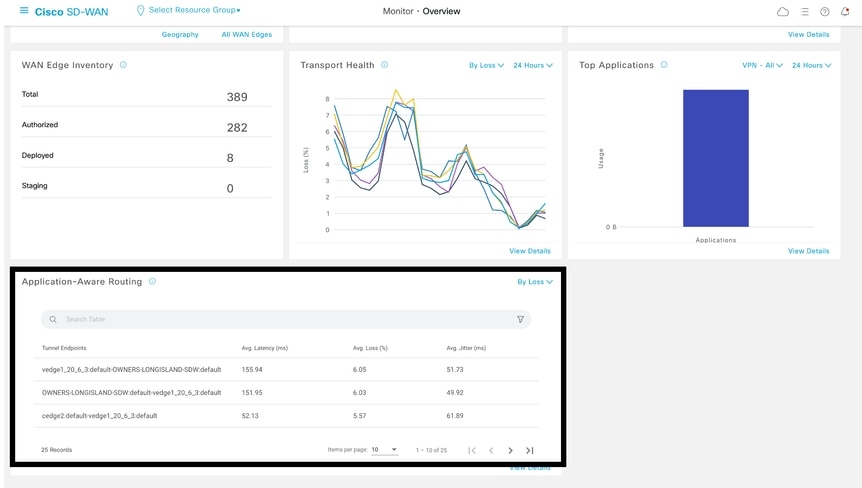
也可以在Monitor > Devices > Select Device > WAN > Tunnel 部分中檢視它。
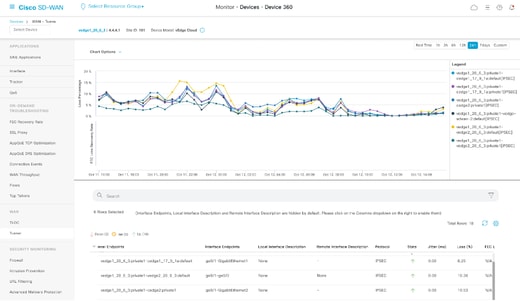
BFD值與損失的關係示例
由於BFD Hello是可配置的值,因此可以根據需求對其進行修改;然而,在仔細考慮後對其進行修改非常重要,否則可能會收到傾斜計算或誤報統計資訊,因為平均損失計算的準確性取決於BFD值。例如,預設值為:
| 引數 |
預設 |
| BFD hello資料包 |
1秒 |
| 輪詢間隔 |
(60萬毫秒) 10分鐘 |
| 乘數 |
6 |
vEdge1# show app-route stats
app-route statistics 10.100.100.2 10.200.200.4 ipsec 12366 12346
remote-system-ip 10.1.1.1
local-color private1
remote-color private1
mean-loss 1
mean-latency 110
mean-jitter 51
sla-class-index 0,2
IPV6 TX IPV6 RX
TOTAL AVERAGE AVERAGE TX DATA RX DATA DATA DATA
INDEX PACKETS LOSS LATENCY JITTER PKTS PKTS PKTS PKTS
----------------------------------------------------------------------------
0 596 7 110 50 0 0 0 0
1 596 5 111 50 0 1 0 0
2 597 13 111 53 0 0 0 0
3 594 4 111 53 0 0 0 0
4 596 5 110 50 0 0 0 0
5 594 12 111 50 0 2 0 0
平均損失=((7+5+13+4+5+12)100)/(596+596+597+594+596+594)
= 4600/3573
= 1.28 ~ 1%
平均延遲=(110+111+111+111+110+111)/6
= 110.66 ~ 110毫秒
平均抖動=(50+50+53+53+50+50)/ 6
= 3 /6 = 51毫秒
註:對於每個計算,只顯示整數值。即使小數是精確結果,整數值也會四捨五入到最接近的較小整數。
通常,最好修改這些值以使計算更頻繁,但可能會產生顯著影響;例如,如果輪詢間隔不是預設值,則會被修改為:
| 引數 |
預設 |
| BFD hello資料包 |
1秒 |
| 輪詢間隔 |
(60,000毫秒) 1分鐘 |
| 乘數 |
6 |
此更改意味著它使用1 x 60 = 60個資料包/儲存桶,而不是預設使用600個資料包。平均損失的結果是:
vEdge1# show app-route stats
app-route statistics 10.100.100.2 10.200.200.4 ipsec 12366 12346
remote-system-ip 10.1.1.1
local-color private1
remote-color private1
mean-loss 3
mean-latency 112
mean-jitter 51
sla-class-index 0,2
IPV6 TX IPV6 RX
TOTAL AVERAGE AVERAGE TX DATA RX DATA DATA DATA
INDEX PACKETS LOSS LATENCY JITTER PKTS PKTS PKTS PKTS
----------------------------------------------------------------------------
0 59 1 113 53 0 0 0 0
1 60 3 111 52 0 1 0 0
2 59 1 111 51 0 1 0 0
3 60 3 111 50 0 1 0 0
4 60 2 115 50 0 0 0 0
5 59 1 111 50 0 2 0 0
平均損耗=((1+3+1+3+2+1)*100)/(59+60+59+60+60+59)
=(1100)/ 357
= 3.08 ~ 3%
此時,如果將SLA類設定為最大損失3,則隧道將受違反SLA的限制。但是,如果將輪詢間隔修改為:
| 引數 |
預設 |
| BFD hello資料包 |
1秒 |
| 輪詢間隔 |
(6,000毫秒) 1秒 |
| 乘數 |
6 |
此更改意味著它使用1 x 6 = 6資料包/儲存桶,而不是使用600作為預設值。平均損失的結果是:
vEdge1# show app-route stats
app-route statistics 10.100.100.2 10.200.200.4 ipsec 12366 12346
remote-system-ip 10.1.1.1
local-color private1
remote-color private1
mean-loss 17
mean-latency 110
mean-jitter 0
sla-class-index None
IPV6 TX IPV6 RX
TOTAL AVERAGE AVERAGE TX DATA RX DATA DATA DATA
INDEX PACKETS LOSS LATENCY JITTER PKTS PKTS PKTS PKTS
----------------------------------------------------------------------------
0 5 1 113 2 0 0 0 0
1 6 1 110 1 0 1 0 0
2 6 1 111 2 0 0 0 0
3 6 0 111 0 0 0 0 0
4 6 1 111 0 0 0 0 0
5 6 1 111 0 0 2 0 0
平均損失=((5)100)/(5+6+6+6+6+6)
=(500)/29
= 17.24 ~ 17%
如果在未正確驗證用於測量的資料包數的情況下減小輪詢間隔,則它可能會影響平均丟失;如果bfd hello-interval增加但沒有增加池間隔,則同樣可能會發生這種情況。
在最後一個示例中,由於使用的資料包很少,並且只有一個資料包丟失,因此平均丟失可能會受到顯著影響。 這些計算的結果是應用感知策略行為,具有多次非常頻繁的故障轉移。
此解釋的目的不是要避免對這些值進行修改,相反,在許多情況下需要修改這些探測器。這完全取決於網路要求,但審查可以減少多少hello資料包非常重要。
全域性修改輪詢間隔的配置命令為:
vEdge(config)# bfd app-route poll-interval 600000
 意見
意見