常見資料層(CDL)故障排除
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
1.導言
本文將介紹在SMF環境中對通用資料層(CDL)進行故障排除的基礎知識。您可以在此連結上找到的文檔。
2.概覽
思科通用資料層(CDL)是用於所有雲本地應用的高效能下一代KV(Key-value)資料儲存層。
CDL當前用作具有HA(高可用性)和Geo HA功能的狀態管理元件。
CDL提供了:
- 跨不同網路功能(NF)的通用資料儲存層。
- 低延遲讀寫(在記憶體會話儲存中)
- 當報告對同一會話的DoS(拒絕服務)攻擊時,通知NF阻止使用者。
- 高可用性 — 至少包含2個副本的本地冗餘。
- 帶有2個站點的Geo冗餘。
- 沒有主要/次要概念所有插槽均可用於寫操作。由於不進行主選擇,因此縮短了故障切換時間。
3.構成部分
- 終結點:(cdl-ep-session-c1-d0-7c79c87d65-xpm5v)
- CDL終端為Kubernetes(K8s)POD。它被部署用於向NF客戶端公開gRPC over HTTP2介面,用於處理資料庫服務請求並充當北向應用程式的入口點。
- 插槽:(cdl-slot-session-c1-m1-0)
- CDL終端支援多個插槽微服務。這些微服務是K8s POD部署的,用於向思科資料儲存公開內部gRPC介面
- 每個插槽POD都擁有有限數量的會話。這些會話是位元組陣列格式的實際會話資料
- 索引:(cdl-index-session-c1-m1-0)
- Index microservice儲存與索引相關的資料
- 然後,此索引資料用於從插槽microservices中檢索實際會話資料
- ETCD:(etcd-smf-etcd-cluster-0)
- CDL使用ETCD(一個開源鍵值儲存)作為資料庫服務發現。當Cisco Data Store EP啟動、關閉或關閉時,會導致發佈狀態新增事件。因此,會向訂用這些事件的每個POD傳送通知。此外,當新增或刪除一個關鍵事件時,它會刷新本地對映。
- 卡夫卡:(kafka-0)
- Kafka POD在本地副本之間和跨站點複製資料以編制索引。對於跨站點複製,Kafak使用MirrorMaker。
- Mirror Maker:(mirror-maker-0)
- Mirror Maker POD將索引資料異地複製到遠端CDL站點。它從遠端站點獲取資料,並將其發佈到本地Kafka站點,以便獲取相應的索引例項。
範例:
master-1:~$ kubectl get pods -n smf-smf -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cdl-ep-session-c1-d0-7889db4d87-5mln5 1/1 Running 0 80d 192.168.16.247 smf-data-worker-5 <none> <none> cdl-ep-session-c1-d0-7889db4d87-8q7hg 1/1 Running 0 80d 192.168.18.108 smf-data-worker-1 <none> <none> cdl-ep-session-c1-d0-7889db4d87-fj2nf 1/1 Running 0 80d 192.168.24.206 smf-data-worker-3 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z6c2z 1/1 Running 0 34d 192.168.4.164 smf-data-worker-2 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z7c89 1/1 Running 0 80d 192.168.7.161 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-0 1/1 Running 0 80d 192.168.7.172 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-1 1/1 Running 0 80d 192.168.24.241 smf-data-worker-3 <none> <none> cdl-index-session-c1-m2-0 1/1 Running 0 49d 192.168.18.116 smf-data-worker-1 <none> <none> cdl-index-session-c1-m2-1 1/1 Running 0 80d 192.168.7.173 smf-data-worker-4 <none> <none> cdl-index-session-c1-m3-0 1/1 Running 0 80d 192.168.24.197 smf-data-worker-3 <none> <none> cdl-index-session-c1-m3-1 1/1 Running 0 80d 192.168.18.107 smf-data-worker-1 <none> <none> cdl-index-session-c1-m4-0 1/1 Running 0 80d 192.168.7.158 smf-data-worker-4 <none> <none> cdl-index-session-c1-m4-1 1/1 Running 0 49d 192.168.16.251 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m1-0 1/1 Running 0 80d 192.168.18.117 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m1-1 1/1 Running 0 80d 192.168.24.201 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m2-0 1/1 Running 0 80d 192.168.16.245 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m2-1 1/1 Running 0 80d 192.168.18.123 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m3-0 1/1 Running 0 34d 192.168.4.156 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m3-1 1/1 Running 0 80d 192.168.18.78 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m4-0 1/1 Running 0 34d 192.168.4.170 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m4-1 1/1 Running 0 80d 192.168.7.177 smf-data-worker-4 <none> <none> cdl-slot-session-c1-m5-0 1/1 Running 0 80d 192.168.24.246 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m5-1 1/1 Running 0 34d 192.168.4.163 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m6-0 1/1 Running 0 80d 192.168.18.119 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m6-1 1/1 Running 0 80d 192.168.16.228 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-0 1/1 Running 0 80d 192.168.16.215 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-1 1/1 Running 0 49d 192.168.4.167 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m8-0 1/1 Running 0 49d 192.168.24.213 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m8-1 1/1 Running 0 80d 192.168.16.253 smf-data-worker-5 <none> <none> etcd-smf-smf-etcd-cluster-0 2/2 Running 0 80d 192.168.11.176 smf-data-master-1 <none> <none> etcd-smf-smf-etcd-cluster-1 2/2 Running 0 48d 192.168.7.59 smf-data-master-2 <none> <none> etcd-smf-smf-etcd-cluster-2 2/2 Running 1 34d 192.168.11.66 smf-data-master-3 <none> <none> georeplication-pod-0 1/1 Running 0 80d 10.10.1.22 smf-data-master-1 <none> <none> georeplication-pod-1 1/1 Running 0 48d 10.10.1.23 smf-data-master-2 <none> <none> grafana-dashboard-cdl-smf-smf-77bd69cff7-qbvmv 1/1 Running 0 34d 192.168.7.41 smf-data-master-2 <none> <none> kafka-0 2/2 Running 0 80d 192.168.24.245 smf-data-worker-3 <none> <none> kafka-1 2/2 Running 0 49d 192.168.16.200 smf-data-worker-5 <none> <none> mirror-maker-0 1/1 Running 1 80d 192.168.18.74 smf-data-worker-1 <none> <none> zookeeper-0 1/1 Running 0 34d 192.168.11.73 smf-data-master-3 <none> <none> zookeeper-1 1/1 Running 0 48d 192.168.7.47 smf-data-master-2 <none> <none> zookeeper-2
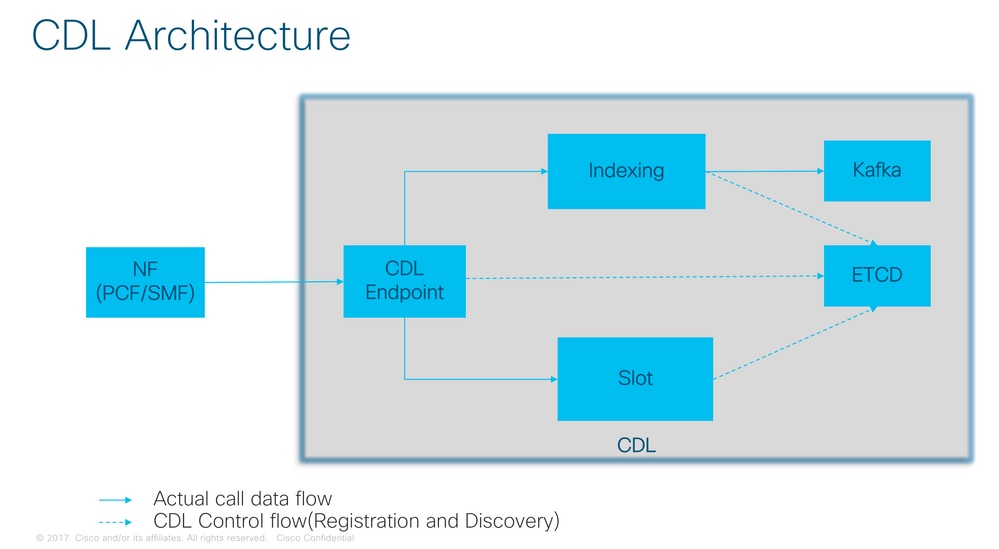 CDL體系結構
CDL體系結構
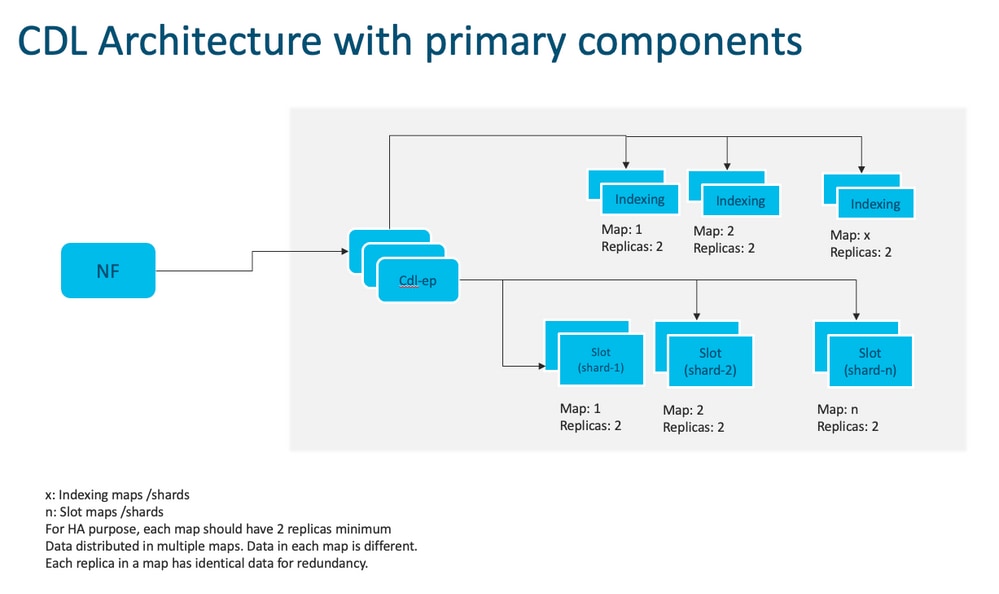
附註:沒有主要/次要概念所有插槽均可用於寫操作。由於不進行主選擇,因此縮短了故障切換時間。
附註:預設情況下,CDL部署為db-ep 2個複製副本、1個插槽對映(每個對映2個複製副本)和1個索引對映(每個對映2個複製副本)。
4.配置演練
smf# show running-config cdl cdl system-id 1 /// unique across the site, system-id 1 is the primary site ID for sliceNames SMF1 SMF2 in HA GR CDL deploy cdl node-type db-data /// node label to configure the node affinity cdl enable-geo-replication true /// CDL GR Deployment with 2 RACKS cdl remote-site 2 db-endpoint host x.x.x.x /// Remote site cdl-ep configuration on site-1 db-endpoint port 8882 kafka-server x.x.x.x 10061 /// Remote site kafka configuration on site-1 exit kafka-server x.x.x.x 10061 exit exit cdl label-config session /// Configures the list of label for CDL pods endpoint key smi.cisco.com/node-type-3 endpoint value session slot map 1 key smi.cisco.com/node-type-3 value session exit slot map 2 key smi.cisco.com/node-type-3 value session exit slot map 3 key smi.cisco.com/node-type-3 value session exit slot map 4 key smi.cisco.com/node-type-3 value session exit slot map 5 key smi.cisco.com/node-type-3 value session exit slot map 6 key smi.cisco.com/node-type-3 value session exit slot map 7 key smi.cisco.com/node-type-3 value session exit slot map 8 key smi.cisco.com/node-type-3 value session exit index map 1 key smi.cisco.com/node-type-3 value session exit index map 2 key smi.cisco.com/node-type-3 value session exit index map 3 key smi.cisco.com/node-type-3 value session exit index map 4 key smi.cisco.com/node-type-3 value session exit exit cdl datastore session /// unique with in the site label-config session geo-remote-site [ 2 ] slice-names [ SMF1 SMF2 ] endpoint cpu-request 2000 endpoint go-max-procs 16 endpoint replica 5 /// number of cdl-ep pods endpoint external-ip x.x.x.x endpoint external-port 8882 index cpu-request 2000 index go-max-procs 8 index replica 2 /// number of replicas per mop for cdl-index, can not be changed after CDL deployement.
NOTE: If you need to change number of index replica, set the system mode to shutdown from respective ops-center CLI, change the replica and set the system mode to running index map 4 /// number of mops for cdl-index index write-factor 1 /// number of copies to be written before a successful response slot cpu-request 2000 slot go-max-procs 8 slot replica 2 /// number of replicas per mop for cdl-slot slot map 8 /// number of mops for cdl-slot slot write-factor 1 slot metrics report-idle-session-type true features instance-aware-notification enable true /// This enables GR failover notification features instance-aware-notification system-id 1 slice-names [ SMF1 ] exit features instance-aware-notification system-id 2 slice-names [ SMF2 ] exit exit cdl kafka replica 2 cdl kafka label-config key smi.cisco.com/node-type-3 cdl kafka label-config value session cdl kafka external-ip x.x.x.x 10061 exit cdl kafka external-ip x.x.x.x 10061 exit
5.故障排除
5.1 Pod故障
CDL的運行方式簡單明瞭:Key > Value db。
- 所有請求都進入cdl-endpoint pod。
- 在cdl-index pods中,我們儲存金鑰,循環配置資源。
- 在cdl-slot中,我們將儲存值(會話資訊),循環配置資源。
- 我們為每個Pod對映(型別)定義備份(複製副本數)。
- Kafka pod被用作交通巴士。
- 映象生成器用作到不同機架的傳輸匯流排(Geo冗餘)。
可以將每個的故障都轉換為,即在此型別/對映的所有埠同時關閉時:
- cdl-endpoint — 與CDL通訊時出錯
- cdl-index — 丟失會話資料的金鑰
- cdl-slot — 丟失會話資料
- Kafka — 在Pod型別對映之間丟失同步選項
- 映象生成器 — 與其他地理還原和節點失去同步
我們始終可以從相關pod中收集日誌,因為cdl pod日誌的滾動更新速度不夠快,因此收集這些日誌具有額外的價值。
Remamber tac-debug在註銷時及時收集快照,並列印出所有資料,因為資料是儲存的。
描述Pod
kubectl describe pod cdl-ep-session-c1-d0-7889db4d87-5mln5 -n smf-rcdn
收集Pod日誌
kubectl logs cdl-ep-session-c1-d0-7c79c87d65-xpm5v -n smf-rcdn
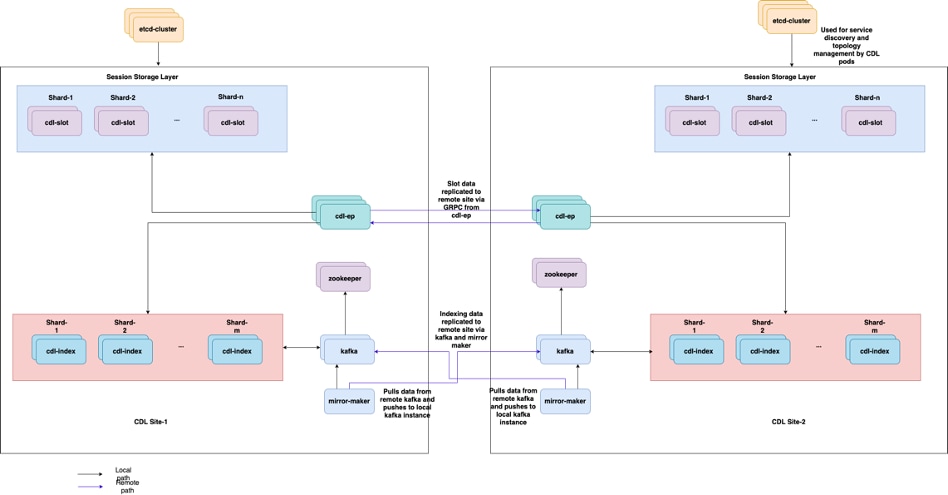
5.2 CDL如何從會話金鑰獲取會話資訊
在CDL內部,每個會話都有一個名為unique-keys的欄位,用於標識此會話。
如果比較show subscriber supi和cdl show sessions summary slice-name slice1 db-name session filter的會話列印輸出
- 與supi組合的ipv4會話地址= "1#/#imsi-123969789012404:10.0.0.3"
- ddn + ip4地址= "1#/#lab:10.0.0.3"
- 與supi組合的ipv6會話地址= "1#/#imsi-123969789012404:2001:db0:0:2:"
- ddn + ipv6來自會話的地址= "1#/#lab:2001:db0:0:2::"
- smfTeid也是N4會話金鑰= "1#/#293601283"在對UPF上的錯誤進行故障排除時,這非常有用,您可以搜尋會話日誌並查詢與會話相關的資訊。
- supi + ebi = "1#/#imsi-123969789012404:ebi-5"
- supi + ddn= "1#/#imsi-123969789012404:lab"
[smf/data] smf# cdl show sessions summary slice-name slice1 db-name session filter { condition match key 1#/#293601283 }
Sun Mar 19 20:17:41.914 UTC+00:00
message params: {session-summary cli session {0 100 1#/#293601283 0 [{0 1#/#293601283}] [] 0 0 false 4096 [] [] 0} slice1}
session {
primary-key 1#/#imsi-123969789012404:1
unique-keys [ "1#/#imsi-123969789012404:10.0.0.3" "1#/#lab:10.0.0.3" "1#/#imsi-123969789012404:2001:db0:0:2::" "1#/#lab:2001:db0:0:2::" "1#/#293601283" "1#/#imsi-123969789012404:ebi-5" "1#/#imsi-123969789012404:lab" ]
non-unique-keys [ "1#/#roaming-status:visitor-lbo" "1#/#ue-type:nr-capable" "1#/#supi:imsi-123969789012404" "1#/#gpsi:msisdn-22331010101010" "1#/#pei:imei-123456789012381" "1#/#psid:1" "1#/#snssai:001000003" "1#/#dnn:lab" "1#/#emergency:false" "1#/#rat:nr" "1#/#access:3gpp" access "1#/#connectivity:5g" "1#/#udm-uecm:10.10.10.215" "1#/#udm-sdm:10.10.10.215" "1#/#auth-status:unauthenticated" "1#/#pcfGroupId:PCF-dnn=lab;" "1#/#policy:2" "1#/#pcf:10.10.10.216" "1#/#upf:10.10.10.150" "1#/#upfEpKey:10.10.10.150:10.10.10.202" "1#/#ipv4-addr:pool1/10.0.0.3" "1#/#ipv4-pool:pool1" "1#/#ipv4-range:pool1/10.0.0.1" "1#/#ipv4-startrange:pool1/10.0.0.1" "1#/#ipv6-pfx:pool1/2001:db0:0:2::" "1#/#ipv6-pool:pool1" "1#/#ipv6-range:pool1/2001:db0::" "1#/#ipv6-startrange:pool1/2001:db0::" "1#/#id-index:1:0:32768" "1#/#id-value:2/3" "1#/#chfGroupId:CHF-dnn=lab;" "1#/#chf:10.10.10.218" "1#/#amf:10.10.10.217" "1#/#peerGtpuEpKey:10.10.10.150:20.0.0.1" "1#/#namespace:smf" ]
flags [ flag3:peerGtpuEpKey:10.10.10.150:20.0.0.1 session-state-flag:smf_active ]
map-id 2
instance-id 1
app-instance-id 1
version 1
create-time 2023-03-19 20:14:14.381940117 +0000 UTC
last-updated-time 2023-03-19 20:14:14.943366502 +0000 UTC
purge-on-eval false
next-eval-time 2023-03-26 20:14:14 +0000 UTC
session-types [ rat_type:NR wps:non_wps emergency_call:false pdu_type:ipv4v6 dnn:lab qos_5qi_1_rat_type:NR ssc_mode:ssc_mode_1 always_on:disable fourg_only_ue:false up_state:active qos_5qi_5_rat_type:NR dcnr:disable smf_roaming_status:visitor-lbo dnn:lab:rat_type:NR ]
data-size 2866
}
[smf/data] smf#
如果將其與SMF的列印輸出進行比較:
[smf/data] smf# show subscriber supi imsi-123969789012404 gr-instance 1 namespace smf
Sun Mar 19 20:25:47.816 UTC+00:00
subscriber-details
{
"subResponses": [
[
"roaming-status:visitor-lbo",
"ue-type:nr-capable",
"supi:imsi-123969789012404",
"gpsi:msisdn-22331010101010",
"pei:imei-123456789012381",
"psid:1",
"snssai:001000003",
"dnn:lab",
"emergency:false",
"rat:nr",
"access:3gpp access",
"connectivity:5g",
"udm-uecm:10.10.10.215",
"udm-sdm:10.10.10.215",
"auth-status:unauthenticated",
"pcfGroupId:PCF-dnn=lab;",
"policy:2",
"pcf:10.10.10.216",
"upf:10.10.10.150",
"upfEpKey:10.10.10.150:10.10.10.202",
"ipv4-addr:pool1/10.0.0.3",
"ipv4-pool:pool1",
"ipv4-range:pool1/10.0.0.1",
"ipv4-startrange:pool1/10.0.0.1",
"ipv6-pfx:pool1/2001:db0:0:2::",
"ipv6-pool:pool1",
"ipv6-range:pool1/2001:db0::",
"ipv6-startrange:pool1/2001:db0::",
"id-index:1:0:32768",
"id-value:2/3",
"chfGroupId:CHF-dnn=lab;",
"chf:10.10.10.218",
"amf:10.10.10.217",
"peerGtpuEpKey:10.10.10.150:20.0.0.1",
"namespace:smf",
"nf-service:smf"
]
]
}
檢查SMF上的CDL狀態:
cdl show status
cdl show sessions summary slice-name <slice name> | more
5.3 CDL Pod未啟動
如何識別
檢查describe pods輸出(容器/成員/狀態/原因、事件)。
kubectl describe pods -n <namespace> <failed pod name>
如何修復
- Pod處於掛起狀態檢查標籤值等於cdl/node-type副本數的任何k8s節點是否小於或等於標籤值等於cdl/node-type值的k8s節點數
kubectl get nodes -l smi.cisco.com/node-type=<value of cdl/node-type, default value is 'session' in multi node setup)
- Pods處於CrashLoopBackOff故障狀態檢查etcd pods狀態。如果etcd pod未運行,請修復etcd問題。
kubectl describe pods -n <namespace> <etcd pod name>
- Pod處於ImagePullBack故障狀態檢查是否可以訪問helm儲存庫和映像登錄檔。檢查是否配置了所需的代理伺服器和dns伺服器。
5.4 Mirror Maker面板處於初始化狀態
檢查describe pods輸出和pod日誌
kubectl describe pods -n <namespace> <failed pod name> kubectl logs -n <namespace> <failed pod name> [-c <container name>]
如何修復
- 檢查為Kafka配置的外部IP是否正確
- 通過外部IP檢查遠端站點kafka的可用性
5.5 CDL索引複製不正確
如何識別
從一個站點新增的資料不能從其他站點訪問。
如何修復
- 檢查本地系統id配置和遠端站點配置。
- 檢查CDL端點和kafka在每個站點之間的可達性。
- 檢查每個站點上的對映、索引副本和插槽。它可以在所有站點上完全相同。
5.6 CDL操作失敗,但連線成功
如何修復
- 檢查所有Pod是否處於就緒和運行狀態。
- 僅當與對等副本(本地或遠端,如果可用)的同步完成時,索引Pod才處於就緒狀態
- 僅當與對等副本(本地或遠端,如果可用)的同步完成時,插槽Pod才會處於就緒狀態
- 如果至少一個插槽和一個索引盒不可用,則終結點處於NOT ready(未就緒)狀態。即使尚未就緒,也會從客戶端接受grpc連線。
5.7 CDL提前或推遲了清除記錄的通知
如何修復
- 在k8s集群中,所有節點都可以進行時間同步
- 檢查所有k8s節點上的NTP同步狀態。如果有任何問題,請修復此問題。
chronyc tracking chronyc sources -v chronyc sourcestats -v
6.警報
| 警報 |
嚴重性 |
摘要 |
|---|---|---|
| cdlLocalRequestFailure |
關鍵 |
如果5分鐘以上的本地請求成功率低於90%,將觸發警報 |
| cdlRemoteConnectionFailure |
關鍵 |
如果從終端Pod到遠端站點的活動連線時間超過5分鐘,則發出警報(僅適用於啟用GR的系統) |
| cdlRemoteRequestFailure |
關鍵 |
如果傳入遠端請求成功率在5分鐘以上低於90%,則觸發警報(僅適用於啟用了GR的系統) |
| cdlReplicationError |
關鍵 |
如果cdl-global名稱空間中的傳出複製請求與本地請求的比率在超過5分鐘的時間內低於90%。(僅適用於啟用了GR的系統)。 升級活動期間會出現這些警報,因此您可以忽略它們。 |
| cdlKafkaRemoteReplicationDelay |
關鍵 |
如果到遠端站點的kafka複製延遲,超過10秒的時間超過5分鐘,則發出警報(僅適用於啟用了GR的系統) |
| cdlOverloaded — 主要 |
主要 |
如果CDL系統達到其容量的配置百分比(預設值為80%),則系統觸發警報(僅當啟用過載保護功能時) |
| cdlOverloaded — 嚴重 |
關鍵 |
如果CDL系統達到配置的容量百分比(預設值為90%),則系統將觸發警報(僅當啟用過載保護功能時) |
| cdlKafkaConnectionFailure |
關鍵 |
如果CDL索引艙與kafka斷開連線超過5分鐘 |
7.最常見的問題
7.1 cdlReplicationError
此警報通常在啟動運行中心或系統升級時出現,請嘗試為其找到CR,嘗試檢查CEE中出現的警報以及是否已清除。
7.2 cdlRemoteConnectionFailure & GRPC_Connections_Remote_Site
該說明適用於所有「cdlRemoteConnectionFailure」和「GRPC_Connections_Remote_Site」警報。
對於cdlRemoteConnectionFailure警報:
在CDL終端日誌中,我們看到從CDL終端Pod到遠端主機的連線已丟失:
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
我們可以看到CDL終端Pod嘗試連線到遠端伺服器,但被遠端主機拒絕:
2022/01/20 01:37:08.730 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.732 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.752 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.754 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
由於遠端主機在5分鐘內仍無法訪問,因此觸發警報的情況如下:
alerts history detail cdlRemoteConnectionFailure f5237c750de6
severity critical
type "Processing Error Alarm"
startsAt 2025-01-21T01:41:26.857Z
endsAt 2025-01-21T02:10:46.857Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes"
labels [ "alertname: cdlRemoteConnectionFailure" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" ]
annotations [ "summary: CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes" "type: Processing Error Alarm" ]
成功在02:10:32連線到遠端主機:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
CDL遠端站點的SMF中存在配置:
cdl remote-site 2
db-endpoint host 10.10.10.141
db-endpoint port 8882
kafka-server 10.10.19.139 10061
exit
kafka-server 10.10.10.140 10061
exit
exit
對於警報GRPC_Connections_Remote_Site:
同樣的解釋同樣適用於「GRPC_Connections_Remote_Site」,因為它也來自同一個CDL終端Pod。
alerts history detail GRPC_Connections_Remote_Site f083cb9d9b8d
severity critical
type "Communications Alarm"
startsAt 2025-01-21T01:37:35.160Z
endsAt 2025-01-21T02:11:35.160Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "GRPC connections to remote site are not equal to 4"
labels [ "alertname: GRPC_Connections_Remote_Site" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" "systemId: 2" ]
在CDL終端Pod日誌中,當拒絕與遠端主機的連線時啟動警報:
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
成功連線到遠端站點時,警報被清除:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
8.格拉法納
CDL控制面板是每個SMF部署的一部分。
修訂記錄
| 修訂 | 發佈日期 | 意見 |
|---|---|---|
1.0 |
04-Oct-2023 |
初始版本 |
由思科工程師貢獻
- Nebojsa KosanovicTechnical Leader
 意見
意見