Konfiguration von Link Fragmentation and Interleaving (LFI) mit Campus ATM-Switches
Download-Optionen
-
ePub (151.6 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
Dieses Dokument bietet einen technischen Überblick über Link Fragmentation and Interleaving (LFI) über eine Frame Relay to ATM Interworking (IWF)-Verbindung (gemäß Definition im Frame Relay Forum oder gemäß FRF.8-Vertrag) sowie eine Beispielkonfiguration für die Verwendung des LS1010 oder Catalyst 8500 als IWF-Gerät in der WAN-Cloud. LFI nutzt die integrierten Fragmentierungsfunktionen der Multilink Point-to-Point Protocol (MLPPP)-Kapselung über ATM und Frame Relay, um eine End-to-End-Fragmentierungs- und Interleaving-Lösung für langsame Verbindungen mit Bandbreiten von bis zu 768 Kbit/s bereitzustellen.
Voraussetzungen
Anforderungen
Für dieses Dokument müssen folgende Punkte verstanden werden:
-
Typische FRF.8-Umgebung und FRF.8-transparente und Übersetzungsmodi - Siehe Verständnis von transparenten und Übersetzungsmodi mit FRF.8.
-
Kenntnis der Konfigurationsbefehle für LS1010 und Catalyst 8500 und der Art, wie der Channelized E1 Frame Relay Port Adapter oder der Channelized DS3 Frame Relay Port Adapter das Interworking zwischen einem Frame Relay-Endpunkt und einem ATM-Endpunkt durchführt
-
Serialisierungsverzögerung und Jitter Siehe VoIP over PPP-Verbindungen mit Quality of Service (LLQ/IP RTP Priority, LFI, cRTP) und VoIP over Frame Relay mit Quality of Service (Fragmentierung, Traffic Shaping, IP RTP-Priorität).
Verwendete Komponenten
Dieses Dokument ist nicht auf bestimmte Software- und Hardware-Versionen beschränkt.
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie unter Cisco Technical Tips Conventions (Technische Tipps von Cisco zu Konventionen).
Warum MLPP über ATM und Frame Relay?
Die Fragmentierung ist eine Schlüsseltechnik zur Steuerung von Serialisierungsverzögerungen und Verzögerungsschwankungen bei langsamen Verbindungen, die sowohl Echtzeit- als auch Nicht-Echtzeit-Datenverkehr übertragen. Die Serialisierungsverzögerung ist die feste Verzögerung, die zum Takten eines Sprach- oder Daten-Frames an der Netzwerkschnittstelle erforderlich ist und sich direkt auf die Taktrate des Trunks bezieht. Ein zusätzliches Flag ist erforderlich, um die Frames für niedrige Taktraten und kleine Frame-Größen zu trennen.
LFI nutzt die integrierten Fragmentierungsfunktionen von MLPPP, um Verzögerungen und Jitter (Schwankungen der Verzögerung) zu verhindern, die durch große Pakete variabler Größe verursacht werden, die zwischen relativ kleinen Sprachpaketen in die Warteschlange gestellt werden. Bei LFI werden Pakete, die größer als eine konfigurierte Fragmentgröße sind, in einen MLPPP-Header gekapselt. RFC 1990 definiert den MLPPP-Header sowie Folgendes:
-
(B)Das Ausgangsfragmentbit ist ein Ein-Bit-Feld, das auf dem ersten von einem PPP-Paket abgeleiteten Fragment auf 1 und auf 0 für alle anderen Fragmente desselben PPP-Pakets festgelegt ist.
-
(E)nding fragment bit ist ein Ein-Bit-Feld, das auf dem letzten Fragment auf 1 und für alle anderen Fragmente auf 0 gesetzt wird.
-
Das Sequenzfeld ist eine 24-Bit- oder 12-Bit-Zahl, die für jedes übertragene Fragment inkrementiert wird. Das Sequenzfeld ist standardmäßig 24 Bit lang, kann jedoch mit der nachfolgend beschriebenen LCP-Konfigurationsoption auf nur 12 Bit festgelegt werden.
Neben der Fragmentierung müssen verzögerungsempfindliche Pakete mit angemessener Priorität zwischen Fragmenten eines großen Pakets geplant werden. Durch die Fragmentierung wird Weighted Fair Queueing (WFQ) "bewusst", ob ein Paket Teil eines Fragments oder nicht fragmentiert ist. WFQ weist jedem eingehenden Paket eine Sequenznummer zu und plant anschließend die Pakete basierend auf dieser Nummer.
Die Layer-2-Fragmentierung bietet eine bessere Lösung als alle anderen Ansätze zur Lösung des "Big-Packet-Problems". In der folgenden Tabelle sind die Vor- und Nachteile anderer möglicher Lösungen aufgeführt.
| Potenzielle Lösung | Vorteile | Nachteile |
|---|---|---|
| Die Übertragung des großen Pakets wird abgebrochen und hinter dem verzögerungsempfindlichen Datenverkehr wieder in die Warteschlange gestellt. |
|
|
| Fragmentieren Sie große Pakete mithilfe von Fragmentierungstechniken auf Netzwerkebene. |
|
|
| Fragmentieren Sie das Paket mithilfe von Link-Layer-Techniken. |
|
|
Die ideale Fragmentgröße für Multilink Point-to-Point Protocol over ATM (MLPPPoATM) sollte es ermöglichen, dass die Fragmente in ein exaktes Vielfaches von ATM-Zellen passen. Eine Anleitung zur Auswahl von Fragmentierungswerten finden Sie unter Link Fragmentation and Interleaving for Frame Relay and ATM Virtual Circuit.
MLPPPoA- und MLPPPoFR-Header
Eine typische Konfiguration von FRF.8 besteht aus den folgenden Komponenten:
-
Ein Frame-Relay-Endpunkt
-
Ein ATM-Endpunkt
-
Ein Interworking (IWF)-Gerät
Jeder Endpunkt kapselt Daten- und Sprachpakete in einem Layer-2-Kapselungsheader, der das gekapselte und in dem Frame oder der Zelle transportierte Protokoll übermittelt. Sowohl Frame Relay als auch ATM unterstützen NLPID-Kapselungsheader (Network Layer Protocol ID). Das Dokument der ISO/International Electrotechnical Commission (IEC) TR 9577 definiert bekannte NLPID-Werte für eine ausgewählte Anzahl von Protokollen. PPP wird der Wert 0xCF zugewiesen.
RFC 1973 definiert PPP in Frame Relay und im MLPPPoFR-Header, während RFC 2364 PPP über AAL5 und den MLPPPoA-Header definiert. Beide Header verwenden den NLPID-Wert 0xCF, um PPP als gekapseltes Protokoll zu identifizieren.
Jede dieser Kopfzeilen ist in Abbildung 1 unten dargestellt.
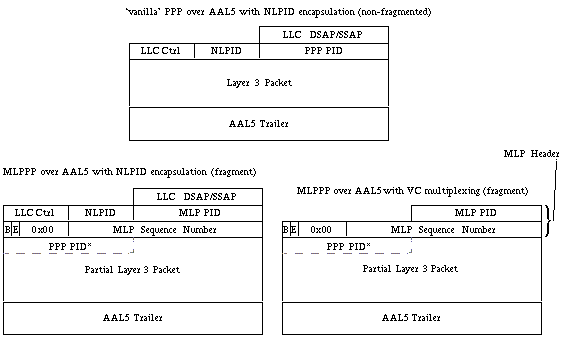
Abbildung 1. PPP over AAL5-Header, MLPPPoA-Header mit NLPID-Kapselung und MLPPPoA-Header mit VC-Multiplexing
Hinweis: Der MLPPPoFR-Header enthält auch das Ein-Byte-Flag-Feld 0x7e, das in Abbildung 1 nicht dargestellt ist. Nach den Headern startet das Byte Nummer 5 die PPP- oder MLPPP-Protokollfelder.
Tabelle 1 - FRF.8 Transparent vs. FRF.8 Translational

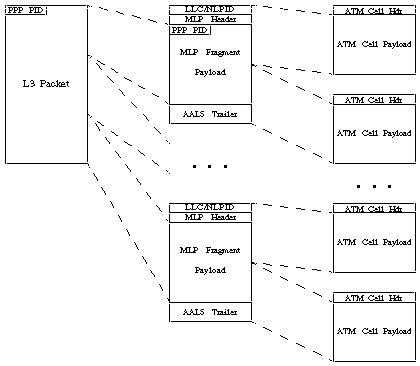
Abbildung 2. Fragmentierung des MLPPPoATM-Pakets mithilfe von NLPID

Abbildung 3: Fragmentierung des MLPPoATM-Pakets mithilfe von VC Multiplexing
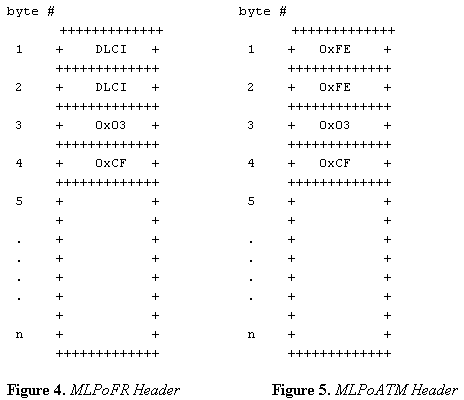
Die Bedeutung der Bytewerte wird im Folgenden dargestellt:
-
0xFEFE - Identifiziert die Ziel- und Quell-Service-Access Points (SAPs) im LLC-Header (Logical Link Control). Der Wert 0xFEFE gibt an, dass als Nächstes ein NLPID-Header in Kurzform folgt, der mit Protokollen mit einem definierten NLPID-Wert verwendet wird.
-
0x03 - Kontrollfeld, das mit vielen Kapselungen verwendet wird, einschließlich High Level Data Link Control (HDLC). Zeigt außerdem an, dass der Paketinhalt aus nicht nummerierten Informationen besteht.
-
0xCF - Bekannter NLPID-Wert für PPP.
FRF.8 Transparent und Übersetzungsmodi
Die FRF.8-Vereinbarung definiert zwei Betriebsmodi für das IWF-Gerät:
-
Transparent - Das IWF-Gerät leitet die Kapselungskopfzeilen unverändert weiter. Es führt keine Protokoll-Header-Zuordnung, Fragmentierung oder Reassemblierung durch.
-
Übersetzung - Das IWF-Gerät führt eine Protokoll-Header-Zuordnung zwischen den beiden Kapselungsheadern durch, um kleine Unterschiede zwischen den Kapselungstypen zu berücksichtigen.
Der auf dem IWF-Gerät konfigurierte Modus, bei dem es sich um einen Cisco ATM-Campus-Switch oder einen Router der Serie 7200 mit einem PA-A3-ATM-Port-Adapter handeln kann, ändert die Anzahl der Layer-2-Header-Bytes auf den ATM- und Frame-Relay-Segmenten der Interworking-Verbindung. Sehen wir uns diese Gemeinkosten einmal genauer an.
Die folgenden beiden Tabellen enthalten die Overhead-Bytes für Datenpakete und VoIP-Pakete (Voice over IP).
Tabelle 2 - Datenverbindungs-Overhead in Byte für ein Datenpaket über eine FRF.8-Verbindung.
| FRF.8-Modus | Transparent | Übersetzung | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Richtung des Datenverkehrs | Frame-Relay an ATM | ATM-Frame-Relay | Frame-Relay an ATM | ATM-Frame-Relay | |||||||||
| Rahmenrelais oder ATM-Schenkel aus PVC | Frame Relay | Geldautomat | Geldautomat | Frame Relay | Frame Relay | Geldautomat | Geldautomat | Frame Relay | |||||
| Frame-Markierung (0x7e) | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | |||||
| Frame Relay-Header | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | |||||
| LLC DSAP/SSAP (0xfefe) | 0 | 0 | 2 | 2 | 0 | 2 | 2 | 0 | |||||
| LLC Control (0x03) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| NLPID (0xcf für PPP) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| MLP-Protokoll-ID (0x003d) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |||||
| MLP-Sequenznummer | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | |||||
| PPP-Protokoll-ID (nur 1. Frag) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |||||
| Nutzlast (Layer 3+) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| ATM-Anpassungsschicht (AAL)5 | 0 | 8 | 8 | 0 | 0 | 8 | 8 | 0 | |||||
| Frame Check Sequence (FCS) | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | |||||
| Gesamter Overhead (Byte) | 15 | 18 | 20 | 17 | 15 | 20 | 20 | 15 | |||||
Tabelle 3 - Datenverbindungsüberhang in Byte für ein VoIP-Paket über eine FRF.8-Verbindung.
| FRF.8-Modus | Transparent | Übersetzung | Frame-Relay zu Frame-Relay | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Richtung des Datenverkehrs | Frame-Relay an ATM | ATM-Frame-Relay | Frame-Relay an ATM | ATM-Frame-Relay | |||||
| Rahmenrelais oder ATM-Schenkel aus PVC | Frame Relay | Geldautomat | Geldautomat | Frame Relay | Frame Relay | Geldautomat | Geldautomat | Frame Relay | |
| Frame-Markierung (0x7e) | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
| Frame-Relay-Header | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | 2 |
| LLC DSAP/SSAP (0xfefe) | 0 | 0 | 2 | 2 | 0 | 2 | 2 | 0 | 0 |
| LLC Control (0x03) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NLPID (0xcf für PPP) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| PPP-ID | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 |
| Nutzlast (IP + User Datagram Protocol (UDP) + RTP + Sprache) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AAL5 | 0 | 8 | 8 | 0 | 0 | 8 | 8 | 0 | 0 |
| FCS | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | 2 |
| Gesamter Overhead (Byte) | 9 | 12 | 14 | 11 | 9 | 14 | 14 | 9 | 7 |
Beachten Sie beim Überprüfen der obigen Tabellen Folgendes:
-
Pakete, die kleiner als die angegebene Fragmentierungsgröße sind, werden nur in einen PPP-Header und nicht in einen MLPPP-Header gekapselt. Ebenso werden Pakete, die größer als die angegebene Fragmentierungsgröße sind, in einen PPP-Header und einen MLPPP-Header gekapselt. So haben VoIP-Pakete bis zu acht Byte weniger Overhead.
-
Nur das erste Multilink PPP (MLP)-Fragment enthält ein PPP-Protokoll-ID-Feld. Das erste Fragment hat also zwei zusätzliche Bytes Overhead.
-
Im transparenten Modus werden die Kapselungsheader unverändert durch das IWF-Gerät geleitet. Der Overhead variiert also in jeder Richtung und auf jedem Segment. Ein MLPPPoA-Header beginnt mit einem NLPID-Header in Kurzform von 0xFEFE. Im transparenten Modus wird dieser Header vom IWF-Gerät unverändert vom ATM-Segment an das Frame-Relay-Segment übergeben. In Richtung Frame-Relay zu ATM ist ein solcher Header jedoch in keinem Segment im transparenten Modus vorhanden.
-
Im Übersetzungsmodus ändert das IWF-Gerät die Kapselungskopfzeilen. Der Overhead ist also in beiden Richtungen auf jedem Segment gleich. Insbesondere kapselt der ATM-Endpunkt das Paket in Richtung ATM-Frame-Relay in einen MLPPPoA-Header. Das IWF-Gerät entfernt den NLPID-Header, bevor der verbleibende Frame an das Frame-Relay-Segment übergeben wird. In Richtung Frame Relay to ATM (Frame-Relay zu ATM) verändert das IWF-Gerät den Frame erneut und stellt einen NLPID-Header vor, bevor der segmentierte Frame an den ATM-Endpunkt übergeben wird.
-
Achten Sie beim Entwerfen von FRF-Verbindungen mit MLP darauf, die richtige Anzahl von Overhead-Bytes für die Datenverbindung zu berücksichtigen. Dieser Overhead beeinflusst die Menge an Bandbreite, die von jedem VoIP-Anruf beansprucht wird. Es spielt auch eine Rolle bei der Bestimmung der optimalen MLP-Fragmentgröße. Die Optimierung der Fragmentgröße zur Anpassung an eine ganzzahlige Anzahl von ATM-Zellen ist von entscheidender Bedeutung, insbesondere bei PVCs mit langsamer Geschwindigkeit, bei denen eine erhebliche Menge an Bandbreite verschwendet werden kann, wenn die letzte Zelle auf ein gerades Vielfaches von 48 Byte aufgefüllt wird.
Der Übersichtlichkeit halber gehen wir nun durch die Schritte des Paketkapselungsprozesses, wenn ein Paket mit dem transparenten Modus in Frame-Relay an ATM-Richtung übermittelt wird:
-
Der Frame-Relay-Endpunkt kapselt das Paket in einen MLPPPoFR-Header.
-
Das IWF-Gerät entfernt den zwei Byte großen Frame-Relay-Header mit dem Data Link Connection Identifier (DLCI). Anschließend leitet er das verbleibende Paket an die ATM-Schnittstelle des IWF weiter, die das Paket in Zellen segmentiert und über das ATM-Segment weiterleitet.
-
Der ATM-Endpunkt überprüft den Header des empfangenen Pakets. Wenn die ersten beiden Bytes des empfangenen Pakets 0x03CF sind, betrachtet der ATM-Endpunkt das Paket als gültiges MLPPPoA-Paket.
-
Die MLPPP-Funktionen am ATM-Endpunkt führen die weitere Verarbeitung durch.
Sehen Sie sich den Paketkapselungsprozess an, wenn ein Paket im ATM in die Frame-Relay-Richtung im transparenten Modus übertragen wird:
-
Der ATM-Endpunkt kapselt das Paket in einen MLPPPoA-Header. Anschließend werden die Pakete in Zellen segmentiert und aus dem ATM-Segment weitergeleitet.
-
Das IWF empfängt das Paket, leitet es an seine Frame-Relay-Schnittstelle weiter und stellt einen Frame-Relay-Header mit zwei Byte voran.
-
Der Frame-Relay-Endpunkt überprüft den Header des empfangenen Pakets. Wenn die ersten vier Bytes nach dem Zwei-Byte-Frame-Relay-Header 0xfefe03cf sind, behandelt IWF das Paket als legales MLPPPoFR-Paket.
-
Die MLPPP-Funktionen am Frame-Relay-Endpunkt führen die weitere Verarbeitung durch.
Die folgenden Abbildungen zeigen das Format von MLPPPoA- und MLPPPoFR-Paketen.

Abbildung 6: MLPPPoA-Overhead. Nur das erste Fragment trägt einen PPP-Header.

Abbildung 7: MLPPPoFR-Overhead. Nur das erste Fragment trägt einen PPP-Header.
VoIP-Bandbreitenanforderungen
Bei der Bereitstellung von Bandbreite für VoIP muss der Overhead der Datenverbindung in die Bandbreitenberechnungen einbezogen werden. Tabelle 4 zeigt die Bandbreitenanforderungen für VoIP pro Anruf in Abhängigkeit vom Codec und der Verwendung des komprimierten Real-time Transport Protocol (RTP). Bei den Berechnungen in Tabelle 4 wird von einem Best-Case-Szenario für die RTP-Header-Komprimierung (cRTP) ausgegangen, d. h. es werden keine UDP-Prüfsumme oder Übertragungsfehler ermittelt. Header werden dann konsistent von 40 Byte auf zwei Byte komprimiert.
Tabelle 4: Bandbreitenanforderungen pro VoIP-Anruf (Kbit/s).
| FRF.8-Modus | Transparent | Übersetzung | Frame-Relay zu Frame-Relay | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Richtung des Datenverkehrs | Frame-Relay an ATM | ATM-Frame-Relay | Frame-Relay an ATM | ATM-Frame-Relay | |||||
| Rahmenrelais oder ATM-Schenkel aus PVC | Frame Relay | Geldautomat | Geldautomat | Frame Relay | Frame Relay | Geldautomat | Geldautomat | Frame Relay | |
| G729 - 20 ms Samples - kein cRTP | 27.6 | 42.4 | 42.4 | 28.4 | 27.6 | 42.4 | 42.4 | 27.6 | 26.8 |
| G729 - 20 ms Beispiele - cRTP | 12.4 | 21.2 | 21.2 | 13.2 | 12.4 | 21.2 | 21.2 | 12.4 | 11.6 |
| G729 - 30 ms Samples - kein cRTP | 20.9 | 28.0 | 28.0 | 21.4 | 20.9 | 28.0 | 28.0 | 20.9 | 20.3 |
| G729 - 30 ms Beispiele - cRTP | 10.8 | 14.0 | 14.0 | 11.4 | 10.8 | 14.0 | 14.0 | 10.8 | 10.3 |
| G711 - 20 ms Samples - kein cRTP | 83.6 | 106.0 | 106.0 | 84.4 | 83.6 | 106.0 | 106.0 | 83.6 | 82.8 |
| G711 - 20 ms Beispiele - cRTP | 68.4 | 84.8 | 84.8 | 69.2 | 68.4 | 84.8 | 84.8 | 68.4 | 67.6 |
| G711 - 30 ms Samples - kein cRTP | 76.3 | 97.9 | 97.9 | 76.8 | 76.3 | 97.9 | 97.9 | 76.3 | 75.8 |
| G711 - 30 ms-Beispiele - cRTP | 66.3 | 84.0 | 84.0 | 66.8 | 66.3 | 84.0 | 84.0 | 66.3 | 65.7 |
Da der Overhead auf jedem Abschnitt des PVC unterschiedlich hoch ist, empfehlen wir die Planung für den schlimmsten Fall. Nehmen wir als Beispiel einen G.279-Anruf mit 20 ms Sampling und cRTP über eine transparente PVC. Auf der Frame-Relay-Strecke wird eine Bandbreite von 12,4 Kbit/s in die eine Richtung und 13,2 Kbit/s in die andere Richtung benötigt. Aus diesem Grund empfehlen wir eine Bereitstellung mit 3,2 Kbit/s pro Anruf.
Zu Vergleichszwecken zeigt die Tabelle auch die VoIP-Bandbreitenanforderungen für ein End-to-End-Frame-Relay-PVC, das mit FRF.12-Fragmentierung konfiguriert ist. Wie in der Tabelle angegeben, benötigt PPP zwischen 0,5 Kbit/s und 0,8 Kbit/s zusätzliche Bandbreite pro Anruf, um die zusätzlichen Bytes des Kapselungsheaders zu unterstützen. Daher empfehlen wir die Verwendung von FRF.12 mit End-to-End-Frame-Relay-VCs.
Für komprimiertes RTP (cRTP) über ATM ist die Cisco IOS® Software, Version 12.2(2)T, erforderlich. Wenn cRTP mit MLPoFR und MLPoATM aktiviert ist, wird die TCP/IP-Header-Komprimierung automatisch aktiviert und kann nicht deaktiviert werden. Diese Einschränkung ergibt sich aus RFC 2509, der keine PPP-Aushandlung der RTP-Header-Komprimierung zulässt, ohne auch die TCP-Header-Komprimierung auszuhandeln.
Übersetzung und transparente Unterstützung auf Cisco Geräten
Ursprünglich erforderte LFI, dass IWF-Geräte den transparenten Modus verwenden. In letzter Zeit hat das Frame Relay Forum FRF.8.1 eingeführt, um den Übersetzungsmodus zu unterstützen. Cisco hat die Unterstützung für FRF.8.1 und den Übersetzungsmodus in den folgenden Versionen der Cisco IOS Software eingeführt:
-
12.0(18)W5(23) für die Serie LS1010 und Catalyst 8500 mit 4CE1 FR-PAM (CSCdt39211)
-
12.2(3)T und 12.2(2) auf Cisco IOS-Routern mit ATM-Schnittstellen, z. B. PA-A3 (CSCdt70724)
Einige Service Provider unterstützen noch keine PPP-Übersetzung auf ihren FRF.8-Geräten. In jedem Fall muss der Anbieter seine PVCs für den transparenten Modus konfigurieren.
Hardware und Software
Für diese Konfiguration wird folgende Hardware und Software verwendet:
-
ATM-Endgerät - PA-A3-OC3 auf einem Router der Serie 7200 mit Cisco IOS Software, Version 12.2(8)T. (Hinweis: LFI wird nur auf PA-A3-OC3 und PA-A3-T3 unterstützt.) Es wird von den IMA- und ATM OC-12-Port-Adaptern nicht unterstützt.)
-
IWF-Gerät - LS1010 mit kanalisiertem T3-Port-Adaptermodul und Cisco IOS Software, Version 12.1(8)EY.
-
Frame-Relay-Endpunkt - PA-MC-T3 in einem Router der Serie 7200 mit Cisco IOS Software, Version 12.2(8)T.
Topologiediagramm
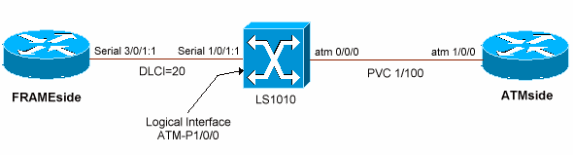
Konfigurationen
Dieser Abschnitt zeigt, wie die LFI-Funktion über eine FRF.8-Verbindung im transparenten Modus konfiguriert wird. Es wird eine virtuelle Vorlage auf den beiden Router-Endpunkten verwendet, von der die virtuelle Zugriffsschnittstelle des MLP-Pakets geklont wird. LFI unterstützt Dialer-Schnittstellen und virtuelle Vorlagen zur Angabe der Protokollschichtparameter von MLPPP. Mit Version 12.2(8)T der Cisco IOS Software kann die Anzahl der eindeutigen virtuellen Vorlagen, die pro Router konfiguriert werden können, auf 200 erhöht werden. Frühere Versionen unterstützten nur bis zu 25 virtuelle Vorlagen pro Router. Diese Einschränkung kann bei einem ATM-Distribution-Router ein Skalierungsproblem darstellen, wenn jeder PVC über eine eindeutige IP-Adresse verfügen muss. Verwenden Sie IP als Umgehungslösung ohne Nummerierung, oder ersetzen Sie virtuelle Vorlagen durch Dialer-Schnittstellen auf nummerierten Links.
Mit der Cisco IOS-Version 12.1(5)T wurde die Unterstützung von LFI über nur einen Mitgliedslink pro MLPPP-Paket eingeführt. Bei dieser Konfiguration wird daher an jedem Endpunkt nur eine VC verwendet. Für eine bevorstehende Version von Cisco IOS ist die Unterstützung mehrerer VCs pro Paket geplant.
| Frame-Relay-Endpunkt |
|---|
|
| LS1010-Konfiguration |
|---|
|
| ATM-Endpunkt |
|---|
|
Befehle anzeigen und debuggen
ATM-Endpunkt
Verwenden Sie die folgenden Befehle am ATM-Endpunkt, um sicherzustellen, dass LFI richtig funktioniert. Bevor Sie Debug-Befehle ausgeben, lesen Sie bitte Wichtige Informationen zu Debug-Befehlen.
-
show ppp multilink - LFI verwendet zwei Virtual-Access-Schnittstellen - eine für PPP und eine für das MLP-Paket. Verwenden Sie den Befehl show ppp multilink, um zwischen den beiden Verbindungen zu unterscheiden.
ATMside#show ppp multilink Virtual-Access2, bundle name is FRAMEside !--- The bundle interface is assigned to VA 2. Bundle up for 01:11:55 Bundle is Distributed 0 lost fragments, 0 reordered, 0 unassigned 0 discarded, 0 lost received, 1/255 load 0x1E received sequence, 0xA sent sequence Member links: 1 (max not set, min not set) Virtual-Access1, since 01:11:55, last rcvd seq 00001D 187 weight !--- The PPP interface is assigned to VA 1. -
show interface virtual-access 1: Bestätigen Sie, dass die Schnittstelle für virtuellen Zugriff aktiv/aktiv ist, und erhöhen Sie die Zähler für das Eingangs- und das Ausgangspaket.
ATMside#show int virtual-access 1 Virtual-Access1 is up, line protocol is up Hardware is Virtual Access interface Internet address is 1.1.1.1/24 MTU 1500 bytes, BW 150 Kbit, DLY 100000 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation PPP, loopback not set DTR is pulsed for 5 seconds on reset LCP Open, multilink Open Bound to ATM1/0/0.1 VCD: 1, VPI: 1, VCI: 100 Cloned from virtual-template: 1 Last input 01:11:30, output never, output hang never Last clearing of "show interface" counters 2w1d Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0 Queueing strategy: fifo Output queue :0/40 (size/max) 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec 878 packets input, 13094 bytes, 0 no buffer Received 0 broadcasts, 0 runts, 0 giants, 0 throttles 0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort 255073 packets output, 6624300 bytes, 0 underruns 0 output errors, 0 collisions, 0 interface resets 0 output buffer failures, 0 output buffers swapped out 0 carrier transitions -
show policy-map int virtual-access 2 - Vergewissern Sie sich, dass die QoS-Servicerichtlinie an die MLPP-Paketschnittstelle gebunden ist.
ATMside#show policy-map int virtual-access 2 Virtual-Access2 Service-policy output: example queue stats for all priority classes: queue size 0, queue limit 27 packets output 0, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 Class-map: call-control (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: access-group 103 queue size 0, queue limit 3 packets output 0, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 Bandwidth: 10%, kbps 15 Class-map: voice (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: ip rtp 16384 16383 Priority: kbps 110, burst bytes 4470, b/w exceed drops: 0 Class-map: class-default (match-any) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: any queue size 0, queue limit 5 packets output 0, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 Fair-queue: per-flow queue limit 2 -
debug ppp packet and debug atm packet - Verwenden Sie diese Befehle, wenn alle Schnittstellen aktiv/aktiv sind, Sie jedoch nicht in der Lage sind, einen End-to-End-Ping zu senden. Darüber hinaus können Sie diese Befehle verwenden, um PPP-Keepalives zu erfassen, wie unten dargestellt.
2w1d: Vi1 LCP-FS: I ECHOREQ [Open] id 31 len 12 magic 0x52FE6F51 2w1d: ATM1/0/0.1(O): VCD:0x1 VPI:0x1 VCI:0x64 DM:0x0 SAP:FEFE CTL:03 Length:0x16 2w1d: CFC0 210A 1F00 0CB1 2342 E300 0532 953F 2w1d: 2w1d: Vi1 LCP-FS: O ECHOREP [Open] id 31 len 12 magic 0xB12342E3 !--- This side received an Echo Request and responded with an outbound Echo Reply. 2w1d: Vi1 LCP: O ECHOREQ [Open] id 32 len 12 magic 0xB12342E3 2w1d: ATM1/0/0.1(O): VCD:0x1 VPI:0x1 VCI:0x64 DM:0x0 SAP:FEFE CTL:03 Length:0x16 2w1d: CFC0 2109 2000 0CB1 2342 E300 049A A915 2w1d: Vi1 LCP-FS: I ECHOREP [Open] id 32 len 12 magic 0x52FE6F51 2w1d: Vi1 LCP-FS: Received id 32, sent id 32, line up !--- This side transmitted an Echo Request and received an inbound Echo Reply.
Frame-Relay-Endpunkt
Verwenden Sie die folgenden Befehle am Frame-Relay-Endpunkt, um die ordnungsgemäße Funktion von LFI zu überprüfen. Bevor Sie Debug-Befehle ausgeben, lesen Sie bitte Wichtige Informationen zu Debug-Befehlen.
-
show ppp multilink - LFI verwendet zwei Virtual-Access-Schnittstellen - eine für PPP und eine für das MLP-Paket. Verwenden Sie den Befehl show ppp multilink, um zwischen den beiden Verbindungen zu unterscheiden.
FRAMEside#show ppp multilink Virtual-Access2, bundle name is ATMside Bundle up for 01:15:16 0 lost fragments, 0 reordered, 0 unassigned 0 discarded, 0 lost received, 1/255 load 0x19 received sequence, 0x4B sent sequence Member links: 1 (max not set, min not set) Virtual-Access1, since 01:15:16, last rcvd seq 000018 59464 weight -
show policy-map interface virtual-access: Überprüfen Sie, ob die QoS-Servicerichtlinie an die Schnittstelle des MLPP-Pakets gebunden ist.
FRAMEside#show policy-map int virtual-access 2 Virtual-Access2 Service-policy output: example Class-map: voice (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: ip rtp 16384 16383 Weighted Fair Queueing Strict Priority Output Queue: Conversation 264 Bandwidth 110 (kbps) Burst 2750 (Bytes) (pkts matched/bytes matched) 0/0 (total drops/bytes drops) 0/0 Class-map: class-default (match-any) 27 packets, 2578 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: any Weighted Fair Queueing Flow Based Fair Queueing Maximum Number of Hashed Queues 256 (total queued/total drops/no-buffer drops) 0/0/0 -
debug frame packet and debug ppp packet: Verwenden Sie diese Befehle, wenn alle Schnittstellen aktiv/aktiv sind, Sie jedoch keinen Ping-Befehl von Ende zu Ende senden können.
FRAMEside#debug frame packet Frame Relay packet debugging is on FRAMEside# FRAMEside#ping 1.1.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 36/36/40 ms FRAMEside# 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 28 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 28 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 28 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52
Warteschleifen und LFI
MLPPPoA und MLPPPoFR klonen zwei Virtual-Access-Schnittstellen von der Dialer-Schnittstelle oder virtuellen Vorlage. Eine dieser Schnittstellen stellt die PPP-Verbindung dar, die andere die Schnittstelle des MLP-Pakets. Verwenden Sie den Befehl show ppp multilink, um die spezifische Schnittstelle für die einzelnen Funktionen zu ermitteln. Zum Zeitpunkt dieses Schreibens wird nur eine VC pro Bündel unterstützt. Daher sollte in der Bündelteilliste in der Ausgabe von show ppp multilink nur eine Virtual-Access-Schnittstelle erscheinen.
Zusätzlich zu den beiden Schnittstellen für den virtuellen Zugriff ist jeder PVC einer Hauptschnittstelle und einer Subschnittstelle zugeordnet. Jede dieser Schnittstellen stellt Warteschlangen bereit. Allerdings unterstützt nur die Virtual-Access-Schnittstelle, die die Paket-Schnittstelle darstellt, Fancy Queueing über eine angewendete QoS-Servicerichtlinie. Die anderen drei Schnittstellen müssen über FIFO-Warteschlangen verfügen. Wenn eine Dienstrichtlinie auf eine virtuelle Vorlage angewendet wird, zeigt der Router die folgende Meldung an:
cr7200(config)#interface virtual-template 1 cr7200(config)#service-policy output Gromit Class Base Weighted Fair Queueing not supported on interface Virtual-Access1
Hinweis: Class Based Weighted Fair Queueing wird nur an der MLPPP-Paketschnittstelle unterstützt.
Diese Meldungen sind normal. In der ersten Meldung wird darauf hingewiesen, dass eine Dienstrichtlinie auf der PPP Virtual-Access-Schnittstelle nicht unterstützt wird. Die zweite Meldung bestätigt, dass die Service-Richtlinie auf die Schnittstelle des MLP-Pakets für den virtuellen Zugriff angewendet wird. Um den Warteschlangenmechanismus auf der MLP-Paketschnittstelle zu bestätigen, verwenden Sie die Befehle show interface virtual-access, show queue virtual-access und show policy-map interface virtual-access.
Für MLPPPoFR muss Frame Relay Traffic Shaping (FRTS) auf der physischen Schnittstelle aktiviert sein. FRTS aktiviert VC-basierte Warteschlangen. Auf Plattformen wie der 7200-, 3600- und 2600-Serie wird FRTS mit den folgenden beiden Befehlen konfiguriert:
-
Frame-Relay Traffic-Shaping an der Hauptschnittstelle
-
map-class mit beliebigen Shaping-Befehlen.
Bei aktuellen Versionen von Cisco IOS wird die folgende Warnmeldung ausgegeben, wenn MLPPoFR ohne FRTS angewendet wird.
"MLPoFR not configured properly on Link x Bundle y"
Wenn diese Warnmeldung angezeigt wird, stellen Sie sicher, dass FRTS für die physische Schnittstelle konfiguriert wurde und dass die QoS-Servicerichtlinie der virtuellen Vorlage beigefügt wurde. Verwenden Sie zum Überprüfen der Konfiguration die serielle Schnittstelle show running-config und die Befehle show running-config virtual-template. Wenn MLPPPoFR konfiguriert ist, ändert sich der Warteschlangenmechanismus für die Schnittstelle in einen dualen FIFO, wie unten dargestellt. Die Warteschlange mit hoher Priorität verarbeitet Sprachpakete und Steuerungspakete wie Local Management Interface (LMI), während die Warteschlange mit niedriger Priorität fragmentierte Pakete, vermutlich Daten- oder Nicht-Sprachpakete, verarbeitet.
Router#show int serial 6/0:0
Serial6/0:0 is up, line protocol is down
Hardware is Multichannel T1
MTU 1500 bytes, BW 64 Kbit, DLY 20000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation FRAME-RELAY, crc 16, Data non-inverted
Keepalive set (10 sec)
LMI enq sent 236, LMI stat recvd 0, LMI upd recvd 0, DTE LMI down
LMI enq recvd 353, LMI stat sent 0, LMI upd sent 0
LMI DLCI 1023 LMI type is CISCO frame relay DTE
Broadcast queue 0/64, broadcasts sent/dropped 0/0, interface broadcasts 0
Last input 00:00:02, output 00:00:02, output hang never
Last clearing of "show interface" counters 00:39:22
Queueing strategy: dual fifo
Output queue: high size/max/dropped 0/256/0
!--- high-priority queue
Output queue 0/128, 0 drops; input queue 0/75, 0 drops
!--- low-priority queue
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
353 packets input, 4628 bytes, 0 no buffer
Received 0 broadcasts, 0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort
353 packets output, 4628 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 output buffer failures, 0 output buffers swapped out
0 carrier transitions
no alarm present
Timeslot(s) Used:12, subrate: 64Kb/s, transmit delay is 0 flags
LFI verwendet zwei Warteschlangenebenen: MLPP-Bündelebene, die Fancy Queueing unterstützt, und PVC-Ebene, die nur FIFO-Warteschlangen unterstützt. Die Paketschnittstelle unterhält eine eigene Warteschlange. Alle MLP-Pakete durchlaufen vor dem Frame-Relay oder der ATM-Ebene zunächst das MLP-Paket und die virtuellen Access-Layer. LFI überwacht die Größe der Hardwarewarteschlangen der Mitglieds-Links und löscht Pakete aus den Hardwarewarteschlangen, wenn sie unter einen Schwellenwert fallen, der ursprünglich ein Wert von zwei war. Andernfalls werden die Pakete in der MLP-Paketwarteschlange in die Warteschlange gestellt.
Fehlerbehebung und bekannte Probleme
In der folgenden Tabelle werden bekannte Probleme mit LFI über FRF-Verbindungen aufgelistet und die Schritte zur Fehlerbehebung erläutert, die Sie durchführen müssen, um Ihre Symptome auf einen behobenen Fehler zu beschränken.
| Symptom | Schritte zur Fehlerbehebung | Behebte Fehler |
|---|---|---|
| Reduzierter Durchsatz für ATM- oder Frame Relay-Leg |
|
CSCdt59038 - Bei 1500-Byte-Paketen und einer Fragmentierung von 100 Byte gibt es 15 fragmentierte Pakete. Die Verzögerung wurde durch mehrere Warteschlangenebenen verursacht. CSCdu1834 - Mit FRTS werden Pakete langsamer aus der Warteschlange entfernt als erwartet. Die MLPP-Bundle-Dequeue-Funktion überprüft die Warteschlangengröße der Traffic Shaper-Warteschlange. FRTS hat diese Warteschlange zu langsam geleert. |
| Nicht in Ordnung befindliche Pakete |
|
CSCdv89201 - Wenn die physische ATM-Schnittstelle überlastet ist, werden MLP-Fragmente am Remote-Ende verworfen oder außer Betrieb genommen. Dieses Problem betrifft nur die ATM-Netzwerkmodule der Serien 2600 und 3600. Dies ist darauf zurückzuführen, dass der Schnittstellentreiber Pakete im Fast Path falsch vertauscht hat (z. B. mit Fast Switching oder Cisco Express Forwarding). Das zweite Fragment des aktuellen Pakets wurde nach dem ersten Fragment des nächsten Pakets gesendet. |
| Ausfall der End-to-End-Verbindung bei IWF-Betrieb im transparenten Modus der Serie 3600 |
|
CSCdw11409 - Stellt sicher, dass CEF an der richtigen Byte-Position sucht, um mit der Verarbeitung der Kapselungsheader von MLPP-Paketen zu beginnen |
Zugehörige Informationen
- Konfiguration der Link-Fragmentierung und des Interleaving für Frame-Relay- und ATM-Virtual Circuits
- Design und Bereitstellung von Multilink PPP over Frame Relay und ATM
- RFC 2364, PPP over AAL5, Juli 1998
- RFC 1973, PPP in Frame Relay, Juni 1996
- RFC1717, The PPP Multilink Protocol (MP), November 1994
- Frame Relay/ATM PVC Service Interworking Implementation Agreement FRF.8
- Weitere ATM-Informationen
- Tools und Ressourcen - Cisco Systems
- Technischer Support und Dokumentation für Cisco Systeme
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
28-May-2002 |
Erstveröffentlichung |
 Feedback
Feedback