Monitor System and Application Health
The Crosswork Platform is built on an architecture consisting of microservices. Due to the nature of these microservices, there are dependencies across various services within the Crosswork system. The system and applications are considered Healthy if all services are up and running. If one or more services are down, then the health is considered Degraded. If all services are down, then the health status is Down.
From the main menu, choose Crosswork Manager to access the Crosswork Summary and Crosswork Health windows. Each window provides various views to monitor system and application health. It also supplies tools and information that, with support and guidance from your Cisco Customer Experience account team, you can use to identify, diagnose, and fix issues with the Cisco Crosswork cluster, Platform Infrastructure, and installed applications.
While both windows can give you access to the same type of information, the purpose of each summary and view is different.
Monitor Cluster Health
At a glance, the Crosswork Summary window () shows a summary of the overall system health. The main purpose of the Crosswork Summary window is to view Crosswork Cluster health in terms of hardware resources and VMs. For example, prior to installing or upgrading applications, you may want to check if the hardware resources are healthy and the VMs are running well. After clicking the Crosswork Cluster tile, you can visually see resource utilization and drill down on VMs to perform some VM or cluster-related activities. In another case, you may see degrading services or over utilization of hardware resources. At this point, from a hardware point of view, you might find that the number of VMs in the system is insufficient prompting you to add more VMs to scale the system further out. For more information, see Check Cluster Health.
In addition to accessing Crosswork Cluster health, you can click on the Cisco Crosswork Platform Infrastructure and application tiles to view more details such as microservices and alarms.
Monitor Platform Infrastructure and Application Health
The Crosswork Health window ( tab) provides health summaries for the Cisco Crosswork Platform Infrastructure and installed applications with the addition of microservice status details.

Within this window, expand an application row to view Microservice and Alarm information.
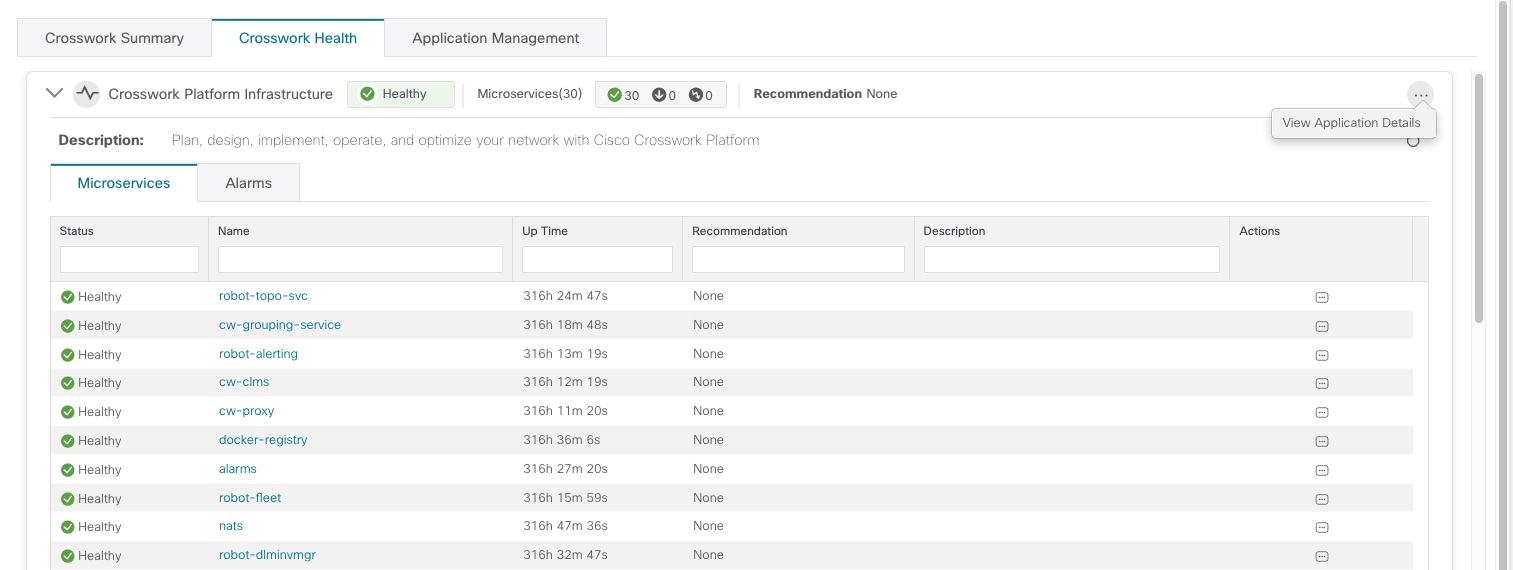
From the Microservices tab:
-
View the list of microservices and, if applicable, associated microservices by clicking on the microservice name.
-
Click
 to restart or obtain Showtech data and logs per microservice.
to restart or obtain Showtech data and logs per microservice.
From the Alarms tab:
-
Click the alarm description to drill down on alarm details.
-
Acknowledge, change status, and add notes to alarms.
You can also download all of a Cisco Crosswork application or Cisco Crosswork Platform Showtech service logs and perform installation-related operations
from the Application Details window. Click ![]() to open the Application Details window.
to open the Application Details window.
Visually Monitor System Functions in Real Time
You can monitor the health of Cisco Crosswork and any of its functions in real time, using a set of monitoring dashboards you can access from the Crosswork Manager window.
Cisco Crosswork uses Grafana to create these dashboards. They give you a graphical view of the product's infrastructure, using metrics collected in its database. You can use these dashboards to diagnose problems you may encounter with individual Cisco Crosswork applications or their underlying services.
There are multiple monitor dashboards, categorized by the type of functionality they monitor and the metrics they provide. The following table lists some categories that may be available depending on whichCisco Crosswork applications are installed.
|
This dashboard category... |
Monitors... |
|---|---|
|
Change Automation |
Playbook functions. Metrics include the number of MOP jobs executed, response latency, API calls, database activity, and so on. |
|
Optima |
Feature pack, traffic, and SR-PCE dispatcher functions. |
|
Collection - Manager |
Device-data collection functions. Metrics include telemetry collection latencies, total collection operations, memory and database activity related to telemetry, delayed collections, and so on. |
|
Health Insights |
Key Performance Indicator functions. Metrics include the number of KPI alerts, API calls, and so on. |
|
Infra |
System infrastructure messaging and database activity. |
|
Inventory |
Inventory manager functions. These metrics include total numbers of inventory change activities. |
|
Platform |
System hardware and communications usage and performance. Metrics include disk and CPU usage, database size, network and disk operations, and client/server communications. |
| ZTP |
Zero Touch Provisioning functions. |
To conserve disk space, Cisco Crosswork maintains a maximum of 24 hours of collected metric data.
Grafana is an open-source visualization tool. The following provides general information about how to use the Cisco Crosswork implementation of Grafana. For more information about Grafana itself, see https://grafana.com and http://docs.grafana.org
Procedure
| Step 1 |
From the main menu, choose . |
||||||||||||||||
| Step 2 |
At the top right, click View more visualizations. The Grafana user interface appears. |
||||||||||||||||
| Step 3 |
In the Grafana user interface, click Home. Grafana displays the list of monitoring dashboards and their categories, as shown in the following example.  |
||||||||||||||||
| Step 4 |
Click the the dashboard you want to view. For example: Clicking on Platform - Summary dashboard displays a view like the one shown in the following figure.  |
||||||||||||||||
| Step 5 |
Scroll the dashboard as needed to display all of the metrics it provides, or select any of the functions described in the following table.
|
View System and Network Alarms
You can view alarms by navigating to one of the following:
-
From the main Crosswork window, click
 .
.
-
From the main menu, choose .
-
For application specific alarms, choose tab. Expand one of the applications and select the Alarms tab.
From the Alarms window:
-
Click the alarm description to drill down on alarm details.
-
Acknowledge, change status, and add notes to alarms.
System Events
To help an operator troubleshoot issues, Crosswork Infrastructure has a Syslog feature which forwards system related events to an external server (see Configure a Syslog Server). All the events related to the Crosswork platform are classified broadly into three categories: Day 0, Day 1, and Day 2. The following table lists the event categories and sample events or actions within that category.
|
Event Classification |
Sample Events and Actions |
|---|---|
|
Day 0 – Events related only to Crosswork Infrastructure installation. |
|
|
Day 1 – Events related to Crosswork application installation. |
|
|
Day 2 – Events related to system operations and maintenance. |
|
Sample Day 0, Day 1, and Day 2 Events
The following tables list related information to various Day 0, Day 1, and Day 2 events in a functional system.
Day 0 Events
These checks can help determine whether the system is healthy.
|
Severity |
Major |
|
Description |
A VM node has been added. This event occurs when the K8 cluster detects a node. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
|
|
Recommendation |
Monitor and confirm that the VM node appears in the UI with a healthy status. |
|
Severity |
Critical |
|
Description |
This event occurs when the Infrastructure Capp untar takes more than 1.5 minutes or if the Docker push takes more than 2 minutes to complete. This message can be found in the firstboot.log file. |
|
Sample Alarm |
Not applicable |
|
Sample Syslog Message |
Not applicable |
|
Recommendation |
This issue must be addressed before further operations can be made on the system. Do the following:
|
Day 1 Events
|
Severity |
Major |
|
Description |
This event occurs when a VM node is erased. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
|
|
Recommendation |
Monitor and confirm that the VM node is no longer seen in the UI. If the erase operation fails, attempt to erase the node again. |
|
Severity |
Information |
|
Description |
This event occurs when an application is added successfully. |
|
Alarm |
 |
|
Syslog Message |
|
|
Recommendation |
None |
|
Severity |
Information |
|
Description |
This event occurs when an application cannot be added. |
|
Sample Alarm |
  |
|
Sample Syslog Message |
None |
|
Recommendation |
After fixing the error, try adding the application again. |
|
Severity |
Information |
|
Description |
This event occurs after an application is activated successfully. |
|
Sample Alarm |
None |
|
Syslog Message |
|
|
Recommendation |
Activate the application and license. |
|
Severity |
Critical |
|
Description |
This event occurs if an application cannot be activated. The activation may fail because microservices or pods do not come up in time. |
|
Sample Alarm |
None |
|
Syslog Message |
None |
|
Recommendation |
Do the following:
|
|
Severity |
Major |
|
Description |
This event occurs if the application was activated successfully but the components remain unhealthy after 3 minutes after application activation. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
None |
|
Recommendation |
You can wait longer and if it becomes healthy, clear the alarm. Contact Cisco TAC if it still appears unhealthy after some time. |
Day 2 Events
|
Severity |
Information |
|
Description |
A node drain occurs if you erase a VM node or if the node has been unresponsive for more than 5 minutes. During the drain operation, pods running on the node are moved (clustered pods may move or go pending, single instance pods will move to another node). |
|
Sample Alarms |
|
|
Syslog Message |
|
|
Recommendation |
Monitor the operation. If the drain is a result of eviction, erase the respective node and insert a new one. |
|
Severity |
Major |
|
Description |
A node drain occurs if you erase a VM node or if the node has been unresponsive for more than 5 minutes. This event occurs if the node drain operation fails. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
|
|
Recommendation |
Try erasing the node again. |
|
Severity |
Critical |
|
Description |
In this scenario we assume that one of the hybrid nodes fails. This event occurs if the node has been down for more than 5 minutes and it is automatically taken out of service. This event can be triggered if someone stopped or deleted a VM without using Cisco Crosswork or if there is a network outage to that node. K8s automatically start evicting pods on that node (drain eviction operation). The VM node will be marked down during a successful cleanup. |
|
Sample Alarm |
|
|
Syslog Message |
None |
|
Recommendation |
Erase the faulty node and insert a new VM. |
|
Severity |
Critical |
|
Description |
This event occurs when the drain eviction fails. The node has been down for more than 5 minutes and K8s automatically start evicting pods on that node. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
None |
|
Recommendation |
Erase the node and attempt another cleanup operation. |
|
Severity |
Critical |
|
Description |
This event occurs when cluster node resources are being highly utilized and there is a lack of a resource footprint. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
None |
|
Recommendation |
Add a new worker node. |
|
Severity |
Minor |
|
Description |
This event occurs when an application is deactivated. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
|
|
Recommendation |
None |
|
Severity |
Critical |
|
Description |
This event occurs when an application cannot be deactivated. This can occu if microservices or pods are still running. |
|
Sample Alarm |
None |
|
Syslog Message |
None |
|
Recommendation |
Do the following:
|
|
Severity |
Critical |
|
Description |
This event occurs when the Infrastructure Capp untar takes more than 1.5 minutes or if the Docker push takes more than 2 minutes to complete. This message can be found in the firstboot.log file. |
|
Sample Alarm |
Not applicable |
|
Sample Syslog Message |
Not applicable |
|
Recommendation |
This issue must be addressed before further operations can be made on the system. Do the following:
|
|
Severity |
Information |
|
Description |
This event occurs if someone erases a VM node and the ETCD clean membership cleanup operation begins. |
|
Sample Alarms |
If ETCD cleanup fails:
|
|
Syslog Message |
None |
|
Recommendation |
Monitor operation. |
|
Severity |
Major |
|
Description |
This event occurs if the ETCD cleanup operation fails. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
None |
|
Recommendation |
Try erasing the node again. |
|
Severity |
Warning |
|
Description |
This event occurs when someone restarts a microservice or pod and the operation fails. |
|
Sample Alarm |
None |
|
Sample Syslog Message |
None |
|
Recommendation |
Restart the microservices or pods. You may have to do this a few times to see if it recovers. |
Check System Health Example
In this example, we navigate through the various windows and what areas should be checked for a healthy Crosswork system.
Procedure
| Step 1 |
Check overall system health.
|
| Step 2 |
Check and view detailed information about the microservices that are running as part of the Crosswork Platform Infrastructure.
|
| Step 3 |
Check and view alarms related to the microservices.
|
| Step 4 |
View which Crosswork applications are installed. |
| Step 5 |
View the status of jobs.
|





 Feedback
Feedback