Einleitung
In diesem Dokument werden die Schritte zur Fehlerbehebung bei Speicherfehlern auf UCS-Servern beschrieben.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen.
- Grundlegende Informationen zum UCS
- Grundlegendes Verständnis der Speicherarchitektur
Verwendete Komponenten
Die Informationen in diesem Dokument basierend auf folgenden Software- und Hardware-Versionen:
- Server der UCS-Produktfamilie M5, M6, M7 und höher
- UCS-Manager
- Cisco Integrated Management Controller (CIMC)
- Cisco Intersight Managed Mode (IMM)
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Speicherfehler
Speicherfehler treten auf, wenn versucht wird, einen Speicherort zu lesen. Der aus dem Speicher gelesene Wert stimmt nicht mit dem Wert überein, der dort sein soll. Diese Fehler werden in zwei Arten unterteilt:
1. Weiche Fehler
Weiche Fehler sind vorübergehend und werden nicht wiederholt. Diese sind temporär und können häufig korrigiert werden, indem der Lese- oder Schreibvorgang am Speicherort wiederholt wird.
2. Harte Fehler
Permanente physikalische Defekte verursachen diese. Das Umschreiben des Speicherorts und das Wiederholen des Lesezugriffs eliminiert einen schwerwiegenden Fehler nicht. Dieser Speicherfehler kann daher nicht korrigiert werden, und der Speicher muss ausgetauscht werden, wenn sich der Fehler wiederholt.
Korrigierbare Fehler
Werden Fehler erkannt und korrigiert, gelten sie als korrigierbar. Dies kann durch Wiederholung des Leseversuchs oder durch Berechnung des korrekten Speicherinhalts mithilfe von ECC-Daten (Error Correction Code) und Rückschreiben der korrekten Daten in den Speicher erfolgen. Wenn ein Fehler erkannt und behoben wurde, protokolliert der Cisco Integrated Management Controller (IMC) das Ereignis im Systemereignisprotokoll.
In der Regel sind korrigierbare Fehler das Ergebnis von weichen Fehlern. Wenn korrigierbare Fehler über einen längeren Zeitraum am gleichen Speicherort bestehen, kann dies auf einen möglichen schwerwiegenden Fehler hinweisen.
ADDC (Adaptive Double Device Data Correction)
ADDDC Sparing kann zwei aufeinander folgende DRAM-Fehler korrigieren, wenn sie sich in derselben Region befinden. ADDDC verschiebt Daten dynamisch aus fehlerhaften Bits in den Reservespeicher und verhindert, dass korrigierbare Fehler unkorrigierbar werden. Zur Auslösung des Mechanismus ist ein Schwellenwert für korrigierbare ECC-Fehler erforderlich.
ADDDC hilft in einigen Szenarien, in denen korrigierbare ECC-Fehler nicht korrigierbaren ECC-Fehlern vorangehen.
Reparatur nach der Verpackung (PPR)
Nach der Paketreparatur (Post Package Repair, PPR) können defekte Speicherbereiche innerhalb eines DIMMs dauerhaft repariert werden, indem redundante DRAM-Zeilen genutzt werden. Diese permanente Vor-Ort-Reparatur ermöglicht eine schnelle Wiederherstellung nach schwerwiegenden Fehlern, ohne das DIMM austauschen zu müssen. Um eine Reparatur durchführen zu können, muss das System ein ADDC-Ereignis erkennen und mindestens einen Neustart durchlaufen. Diese Reparaturaktivität hat keine Auswirkungen auf die Leistung oder den gesamten für das Betriebssystem verfügbaren Arbeitsspeicher.
PPR und ADDDC sind standardmäßig aktiviert, können jedoch konfiguriert werden. Für PPR muss auch der ADDDC-RAS-Ersatzmodus aktiviert sein. Wenn die RAS-Einstellung nicht auf ADDDC Sparing (ADDC-Ersatz) oder Platform Default (Plattformstandard) festgelegt ist, ist PPR nicht betriebsbereit. Der einzig unterstützte PPR-Modus ist Hard PPR, was bedeutet, dass Reparaturen permanent sind.
Partielles Cache-Line-Sparing (PCLS)
In der Speichersteuerung ist ein Fehlervermeidungsmechanismus vorhanden. Es funktioniert, indem es fehlerhafte kleine Teile von Daten im Speicher identifiziert. Diese fehlerhaften Standorte werden zusammen mit Backup-Daten, die sie ersetzen können, in einem speziellen Verzeichnis gespeichert. Wenn beim Zugriff auf den Speicher ein Fehler an diesen fehlerhaften Stellen auftritt, verwendet der Controller die Backup-Daten aus dem Verzeichnis, um einen reibungslosen Ablauf zu gewährleisten.
Hinweis: Die Funktionen sind je nach CPU-Architektur und Firmware-Version auf dem Server verfügbar. Stellen Sie sicher, dass Sie sich in der letzten empfohlenen Version befinden, um die Speicherfehler besser zu behandeln.
Fehlerbehebung bei RAS-Fehlern
UCS-Manager
Im Allgemeinen werden diese Fehler im UCS Manager als RAS-Ereignis angezeigt.
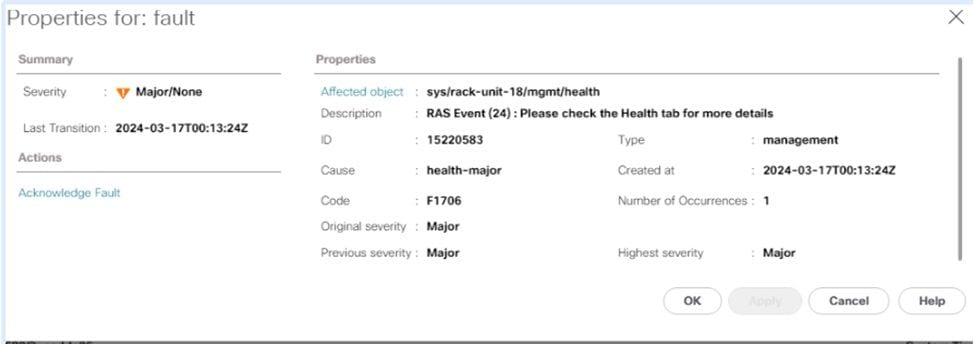
In der Statuszusammenfassung finden Sie weitere Informationen zum Fehler, ob PCLS oder PPR ausgelöst wurde.
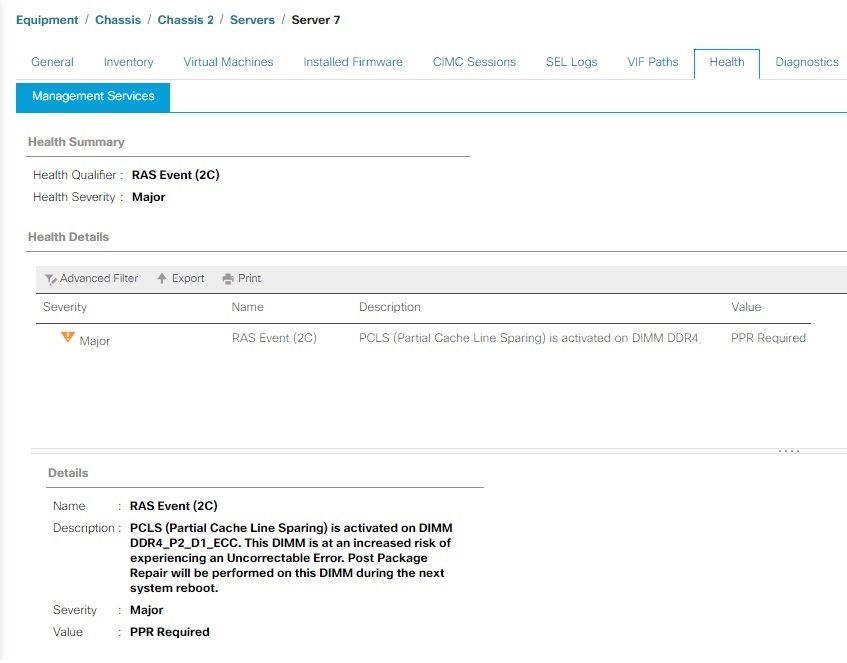
Beispiel für PCLS
Auf M6-Servern und neueren Versionen haben Sie die Möglichkeit, PCLS (Patrial cache line sparing) als BIOS-Option zu aktivieren, die einen Mechanismus zur Fehlervermeidung darstellt. Der Server muss so schnell wie möglich neu gestartet werden, damit PPR eingreifen und das DIMM reparieren kann. Nach dem Neustart des Servers können Sie auf zusätzliche UCS Manager-Fehler für dasselbe DIMM-Modul achten.
Wie in der Warnung erwähnt, wird empfohlen, den Server so schnell wie möglich neu zu starten, da das Risiko eines nicht behebbaren Fehlers und damit unerwarteter Serverausfallzeiten besteht.
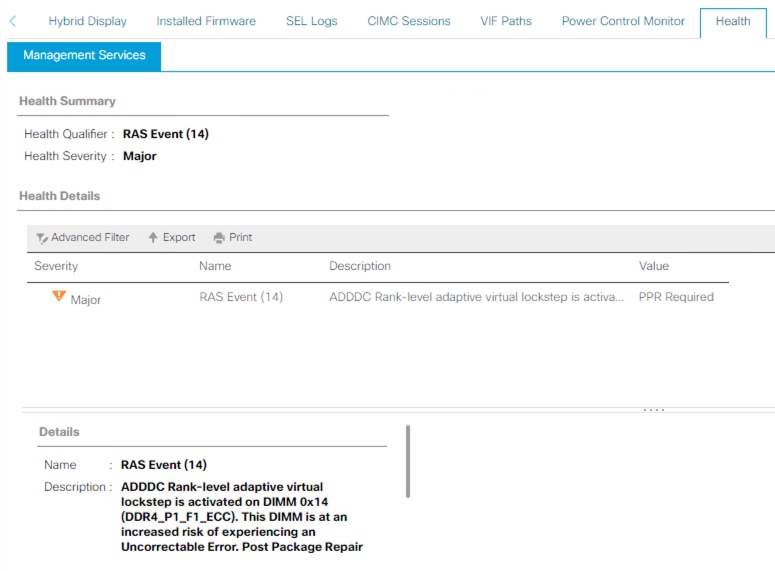
PPR-Beispiel
Auf dem Server sind ADDC und PPR aktiviert, und es ist ein RAS-Ereignis aufgetreten. Der Fehler deutet auf einen Neustart hin, damit PPR den DIMM reparieren kann. Der Server muss so schnell wie möglich neu gestartet werden, damit PPR den DIMM reparieren kann.
Nach dem Neustart des Servers können Sie auf zusätzliche UCS Manager-Fehler für dasselbe DIMM-Modul achten.
Wie in der Warnung erwähnt, wird empfohlen, den Server so schnell wie möglich neu zu starten, da das Risiko eines nicht behebbaren Fehlers und damit unerwarteter Serverausfallzeiten besteht.
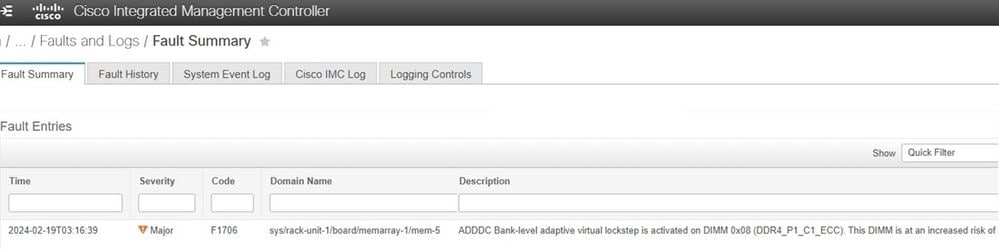
Intersight-Managed-Modus
Auf dem Server ist ADDDC aktiviert, und es ist ein BANK VLS-Ereignis aufgetreten, wodurch der angezeigte Fehler verursacht wurde. In diesem Szenario besteht der nächste Schritt darin, so bald wie möglich einen Server-Neustart durchzuführen, um die Ausführung von PPR zu ermöglichen.

Cisco Integrated Management Controller (CIMC)
Der Fehler wird angezeigt, wenn Sie den Cisco Integrated Management Controller verwenden. Wenn auf dem Server ein ADDC-Ereignis und ein VLS-Ereignis aufgetreten sind, funktioniert dies so, dass nicht korrigierbare Fehler vermieden werden.
Schritte zur Fehlerbehebung
- Stellen Sie sicher, dass keine anderen DIMM-Fehler vorhanden sind, z. B. "Uncorrect Error" (Nicht korrigierbarer Fehler).
- Planen Sie ein Wartungsfenster.
- Setzen Sie einen Host in den Wartungsmodus, und starten Sie den Server neu, um eine dauerhafte Reparatur des DIMMs mithilfe von PPR (Post Package Repair) zu versuchen.
UCSM-Neustartschritte
Hinweis: Sie können den Server auch vom Betriebssystem aus neu starten. In diesem Beispiel wird die Option reboot der Server-Benutzeroberfläche verwendet.
Navigieren Sie zu Ihrer UCS Manager-Webschnittstelle.
Blade Server
Navigieren Sie zu Equipment > Chassis > Server X.
Integrierter Server
Navigieren Sie zu Equipment > Rack-Mounts > Server X.
Klicken Sie auf KVM-Konsole.
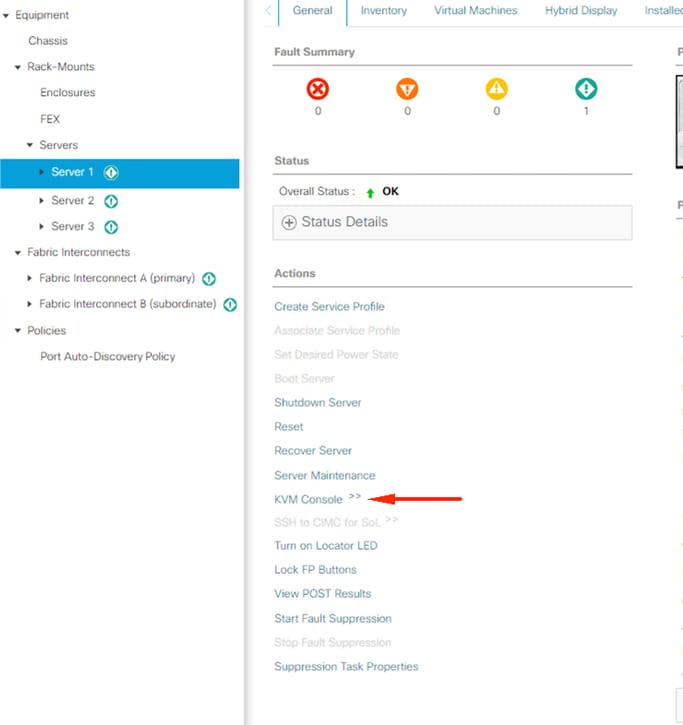
Klicken Sie in den KVM-Fenstern auf Serveraktionen, wählen Sie Zurücksetzen aus, und klicken Sie auf OK.
Überwachen Sie den Neustart im KVM-System, und stellen Sie sicher, dass das Betriebssystem korrekt gestartet wird.
IMM-Neustartschritte
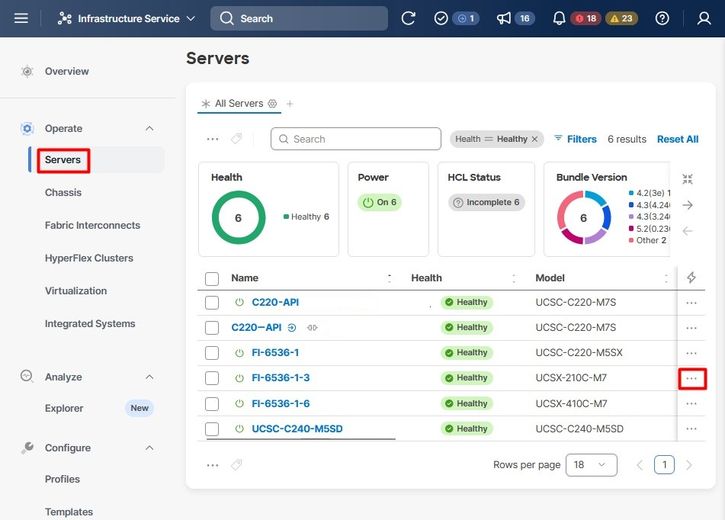
Navigieren Sie zur Registerkarte Server, identifizieren Sie den Server, und klicken Sie auf das Menü Aktion (drei Punkte).
Wählen Sie anschließend das Menü Ein-/Ausschalten und anschließend die Option Ein-/Ausschalten.
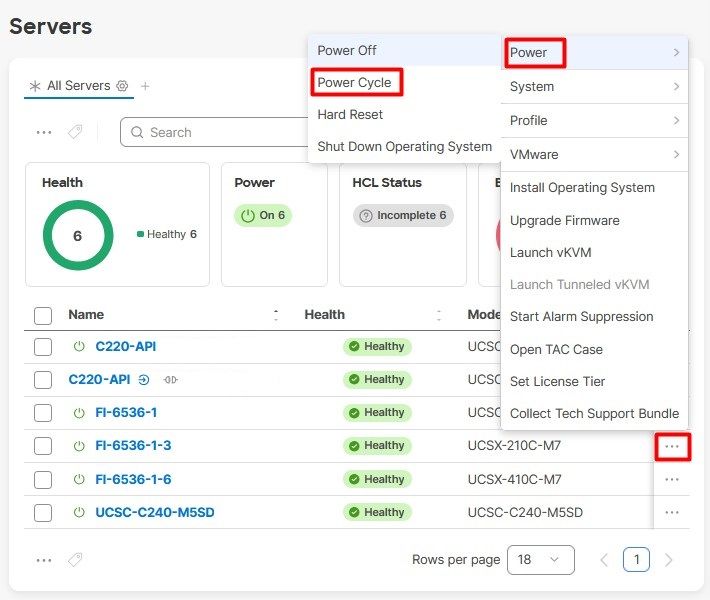
Klicken Sie auf die Schaltfläche Ein-/Ausschalten, um die Aktion zu bestätigen.
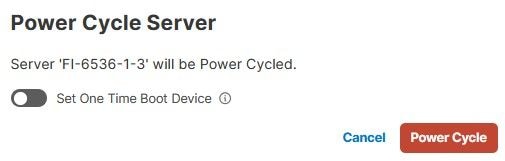
Überprüfen Sie den Fortschritt im Menü Anforderungen.
CIMC-Neustartschritte
Navigieren Sie zur Option Host Power (Host-Stromversorgung), und wählen Sie Power Cycle (Aus- und Wiedereinschalten).
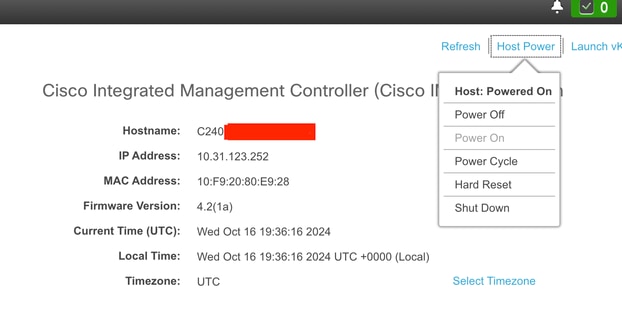
Starten Sie den KVM, um den Neustart zu überwachen, und stellen Sie sicher, dass das Betriebssystem korrekt gestartet wird.
Auf neue Fehler überwachen
Wenn nach dem Neustart keine Fehler auftreten, sodass kein anderes RAS-Ereignis oder kein anderer Fehler im Zusammenhang mit dem DIMM auftritt, war der PPR-Test erfolgreich, und der Server kann wieder verwendet werden.
Wenn neue ADDDC-Ereignisse auftreten, wiederholen Sie den in den vorherigen Schritten beschriebenen Neustartvorgang, um weitere dauerhafte Reparaturen mit PPR durchzuführen.
Wenn nach dem Neustart ein nicht behebbarer Fehler oder ein nicht betriebsfähiger Fehler auftritt, weist der Fehler darauf hin, dass ein Speicher ausgetauscht werden muss.
Hinweis: Falls Sie einen dieser Fehler feststellen, erstellen Sie bitte ein Ticket beim Cisco TAC, um das DIMM zu ersetzen.
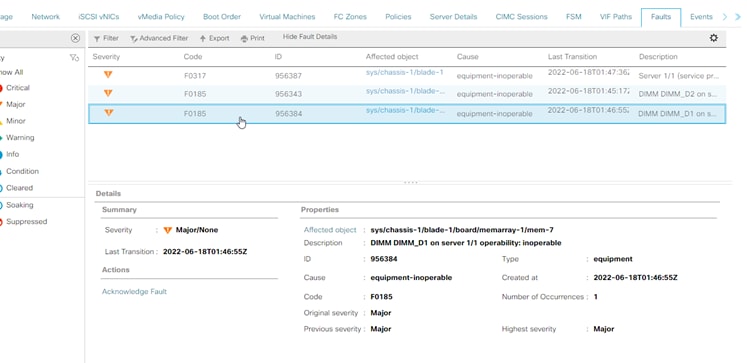
Nicht korrigierbarer Speicherfehler in UCS Manager
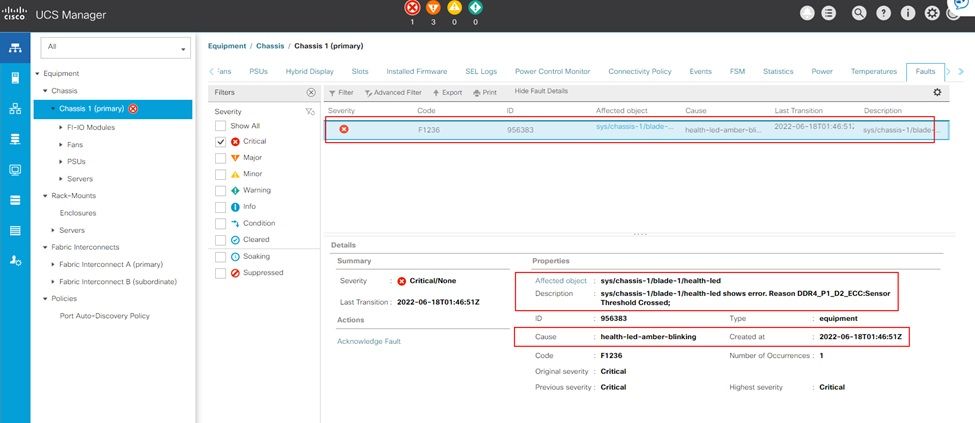
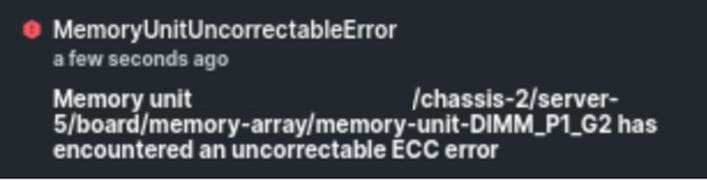
Nicht korrigierbarer IMM-Speicherfehler
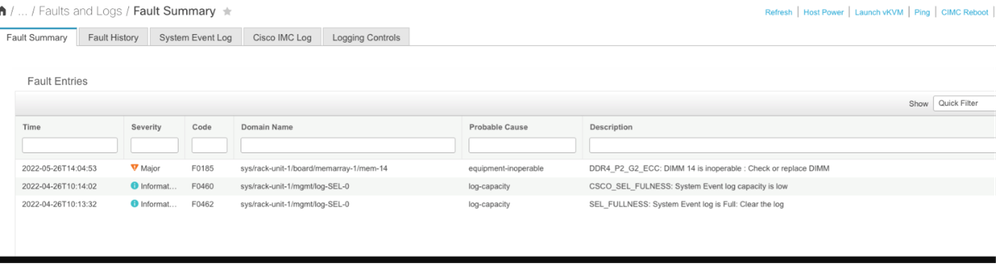
Nicht korrigierbarer Fehler. Der Fehler zeigt an, dass das DIMM einen nicht behebbaren Fehler aufweist und ausgetauscht werden muss.
Nicht korrigierbarer CIMC-Speicherfehler
Zugehörige Informationen
 Feedback
Feedback