Problembehandlung bei der CUCM-Datenbankreplikation
Download-Optionen
-
ePub (423.1 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
Dieses Dokument beschreibt die Diagnose von Datenbankreplikationsproblemen und enthält die erforderlichen Schritte zur Erkennung und Behebung dieser Probleme.
Schritte zur Diagnose der Datenbankreplikation
In diesem Abschnitt werden Szenarien beschrieben, in denen die Datenbankreplikation unterbrochen wird, und es wird die Fehlerbehebungsmethode beschrieben, um das Problem zu diagnostizieren und zu isolieren.
Schritt 1: Überprüfung der Datenbankreplikation als abgebrochen
Um festzustellen, ob Ihre Datenbankreplikation fehlerhaft ist, müssen Sie die verschiedenen Status des Real Time Monitoring Tools (RTMT) für die Replikation kennen.
| Wert | Bedeutung | Beschreibung |
|---|---|---|
| 0 |
Initialisierungsstatus |
Die Replikation wird gerade eingerichtet. Ein Setup-Fehler kann auftreten, wenn sich die Replikation länger als eine Stunde in diesem Zustand befindet. |
| 1 |
Die Anzahl der Replikate ist falsch |
Die Einrichtung ist noch nicht abgeschlossen. Dieser Status tritt in den Versionen 6.x und 7.x selten auf. In Version 5.x bedeutet dies, dass die Einrichtung noch läuft. |
| 2 |
Die Replikation ist in Ordnung |
Logische Verbindungen wurden hergestellt und die Tabellen werden mit den anderen Servern im Cluster abgeglichen. |
| 3 |
Nicht übereinstimmende Tabellen |
Es werden logische Verbindungen hergestellt, es besteht jedoch Unsicherheit, ob die Tabellen übereinstimmen. In den Versionen 6.x und 7.x kann es sein, dass alle Server den Status 3 anzeigen, selbst wenn ein Server im Cluster ausgefallen ist. Dieses Problem kann auftreten, weil die anderen Server nicht sicher sind, ob ein Update der User Facing Feature (UFF) vorliegt, das nicht vom Abonnenten an das andere Gerät im Cluster weitergeleitet wurde. |
| 4 |
Einrichtung fehlgeschlagen/verworfen |
Der Server hat keine aktive logische Verbindung mehr, um Datenbanktabellen über das Netzwerk zu empfangen. In diesem Status findet keine Replikation statt. |
Führen Sie zum Überprüfen der Datenbankreplikation den Befehl utils dbreplication runtimestate über die CLI des Publisherknotens aus, wie in diesem Bild dargestellt.
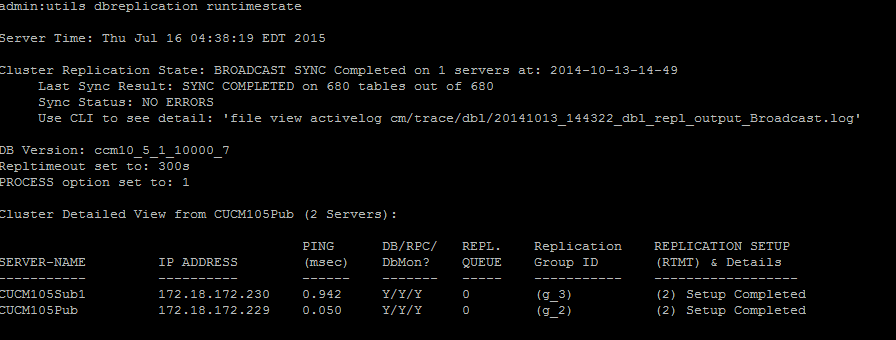
Stellen Sie sicher, dass der Clusterreplikationsstatus in der Ausgabe nicht die alten Synchronisierungsinformationen enthält. Überprüfen Sie den Wert, und verwenden Sie den Zeitstempel.
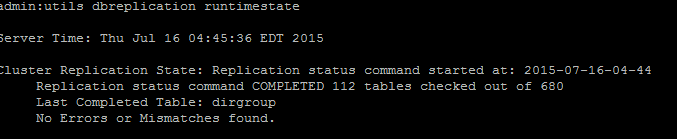
Wenn die Broadcast-Synchronisierung nicht mit einem aktuellen Datum aktualisiert wird, führen Sie den Befehl utils dbreplication status aus, um alle Tabellen und die Replikation zu überprüfen. Wenn Fehler/Nichtübereinstimmungen erkannt werden, werden diese in der Ausgabe angezeigt, und der RTMT-Status ändert sich entsprechend (siehe Abbildung).
o
Nachdem Sie den Befehl ausgeführt haben, werden alle Tabellen auf Konsistenz geprüft und ein genauer Replikationsstatus angezeigt.
Anmerkung: Lassen Sie alle Tabellen überprüfen, und fahren Sie dann mit der Fehlerbehebung fort.

Sobald ein genauer Replikationsstatus angezeigt wird, überprüfen Sie die Replikations-Einrichtung (RTMT) und die Details, wie in der ersten Ausgabe dargestellt. Sie müssen den Status für jeden Knoten überprüfen. Wenn ein Knoten einen anderen Status als 2 hat, fahren Sie mit der Fehlerbehebung fort.
Schritt 2: Erfassen des CM-Datenbankstatus auf der Seite "Cisco Unified Reporting" in CUCM
- Wenn Sie Schritt 1 abgeschlossen haben, wählen Sie die Cisco Unified Reporting-Option aus der Dropdown-Liste Navigation im CUCM-Publisher (Cisco Unified Communications Manager) aus, wie in diesem Bild dargestellt.
2. Navigieren Sie zu Systemberichte, und klicken Sie auf Unified CM Database Status (Unified CM-Datenbankstatus), wie in dieser Abbildung dargestellt.
3. Erstellen Sie einen neuen Bericht, klicken Sie auf das Symbol Neuen Bericht erstellen, wie in diesem Bild dargestellt.

4. Warten Sie, bis der neue Bericht erfolgreich erstellt wurde.

5. Klicken Sie nach der Erstellung auf das Symbol, um den Bericht herunterzuladen und zu speichern, damit er einem TAC-Techniker bereitgestellt werden kann, falls ein Serviceticket (SR) geöffnet werden muss.

Schritt 3: Überprüfen Sie den Unified CM-Datenbankbericht aller Komponenten, die als Fehler gekennzeichnet sind.
Wenn die Komponenten Fehler enthalten, sind diese mit einem roten X gekennzeichnet, wie in dieser Abbildung gezeigt.
-
Stellen Sie sicher, dass auf lokale Datenbanken und Publisher-Datenbanken zugegriffen werden kann.
- Überprüfen Sie im Fall eines Fehlers die Netzwerkverbindungen zwischen den Knoten. Überprüfen Sie, ob der Cisco DB-Dienst A über die CLI des Knotens ausgeführt wird und den Befehl utils service list verwendet.
- Wenn der Cisco DB-Dienst nicht aktiv ist, führen Sie den Befehl utils service start A Cisco DB aus, um ihn zu starten. Wenn dies fehlschlägt, wenden Sie sich an das Cisco TAC.
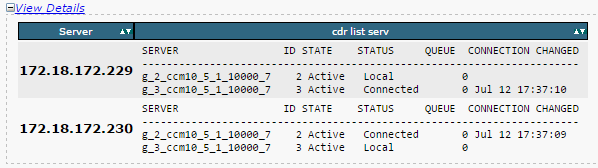
- Stellen Sie sicher, dass Replication Server List (cdr list serv) für alle Knoten ausgefüllt ist.
Dieses Bild stellt eine ideale Ausgabe dar.
Wenn die Cisco Database Replicator (CDR)-Liste für einige Knoten leer ist, fahren Sie mit Schritt 8 fort.
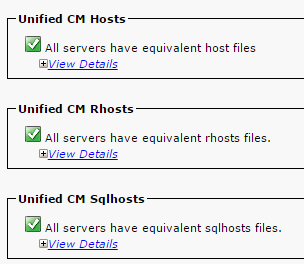
- Stellen Sie sicher, dass die Unified CM-Hosts, Rhosts und Sqlhosts auf allen Knoten gleich sind.
Dies ist ein wichtiger Schritt. Wie in dieser Abbildung dargestellt, sind die Unified CM-Hosts, die Rhosts und die Sqlhosts auf allen Knoten gleichwertig.
Die Hosts-Dateien stimmen nicht überein:
Wenn sich eine IP-Adresse ändert oder der Hostname auf dem Server aktualisiert wird, kann eine falsche Aktivität vorliegen.
Unter diesem Link können Sie die IP-Adresse in den Hostnamen für den CUCM ändern.
Änderungen der IP-Adresse und des Hostnamens
Starten Sie diese Dienste über die CLI des Publisher-Servers neu, und überprüfen Sie, ob die Inkongruenz behoben ist. Falls ja, fahren Sie mit Schritt 8 fort. Falls nein, wenden Sie sich an das Cisco TAC. Generieren Sie bei jeder Änderung an der GUI/CLI einen neuen Bericht, um zu überprüfen, ob die Änderungen übernommen wurden.
Cluster Manager ( utils service restart Cluster Manager)
A Cisco DB ( utils service restart A Cisco DB)
Die Rhosts-Dateien stimmen nicht überein:
Wenn die Rhosts-Dateien und die Host-Dateien nicht übereinstimmen, befolgen Sie die Schritte unter „Die Hosts-Dateien stimmen nicht überein“. Wenn nur die Rhosts-Dateien nicht übereinstimmen, führen Sie die Befehle über die CLI aus:
A Cisco DB ( utils service restart A Cisco DB ) Cluster Manager ( utils service restart Cluster Manager)
Generieren Sie einen neuen Bericht, und überprüfen Sie, ob die Rhost-Dateien auf allen Servern gleich sind. Falls ja, fahren Sie mit Schritt 8 fort. Falls nein, wenden Sie sich an das Cisco TAC.
Die Sqlhosts stimmen nicht überein:
Wenn die Sqlhosts und die Host-Dateien nicht übereinstimmen, befolgen Sie die Schritte unter „Die Hosts-Dateien stimmen nicht überein“. Wenn nur die Sqlhosts-Dateien nicht übereinstimmen, führen Sie folgenden Befehl über die CLI aus:
utils service restart A Cisco DB
Generieren Sie einen neuen Bericht, und überprüfen Sie, ob die Sqlhost-Dateien auf allen Servern gleichwertig sind. Falls ja, fahren Sie mit Schritt 8 fort. Falls nein, wenden Sie sich an das Cisco TAC.
-
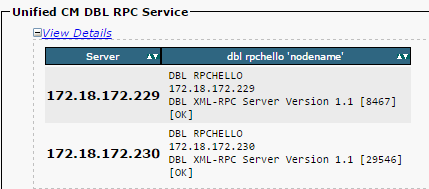
Stellen Sie sicher, dass der DBL-RPC-Hello (Database Layer Remote Procedural Call/Remoteprozeduraufruf auf Datenbankebene) erfolgreich ist (siehe Abbildung).
Wenn der RPC-Hello für einen bestimmten Knoten nicht funktioniert:
- Stellen Sie sicher, dass eine Netzwerkverbindung zwischen dem jeweiligen Knoten und dem Publisher besteht.
- Stellen Sie sicher, dass die Portnummer 1515 im Netzwerk erlaubt ist.
Unter diesem Link finden Sie Details zur Verwendung von TCP-/UDP-Ports:
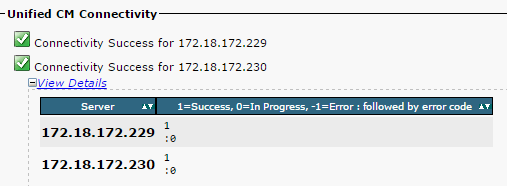
- Stellen Sie sicher, dass die Netzwerkverbindung zwischen den Knoten erfolgreich ist (siehe Abbildung):

Wenn die Netzwerkverbindung für die Knoten ausfällt:
- Stellen Sie sicher, dass die Netzwerkerreichbarkeit zwischen den Knoten vorhanden ist.
- Stellen Sie sicher, dass die entsprechenden TCP-/UDP-Portnummern im Netzwerk zulässig sind.
Generieren Sie einen neuen Bericht, und überprüfen Sie, ob die Verbindung erfolgreich hergestellt wurde. Wenn die Verbindung nicht hergestellt werden konnte, fahren Sie mit Schritt 8 fort.
Schritt 4: Überprüfen Sie die einzelnen Komponenten, die den Utils Diagnose-Testbefehl verwenden.
Der Befehl utils diagnostize test überprüft alle Komponenten und gibt als Wert „passed/failed“ (bestanden/fehlgeschlagen) zurück. Folgende Komponenten sind für das ordnungsgemäße Funktionieren der Datenbankreplikation essenziell:
-
Netzwerkkonnektivität:
Der Befehl validate_network überprüft alle Aspekte der Netzwerkverbindung mit allen Knoten im Cluster. Wenn ein Verbindungsproblem vorliegt, wird häufig ein Fehler auf dem Domain Name Server/Reverse Domain Name Server (DNS/RDNS) angezeigt. Mit dem Befehl validate_network wird der Vorgang in 300 Sekunden abgeschlossen. Die häufigsten Fehlermeldungen aus den Netzwerkverbindungstests:
1. Fehler "Kommunikation innerhalb des Clusters unterbrochen", wie in diesem Bild dargestellt.

- Ursache
Dieser Fehler wird verursacht, wenn ein oder mehrere Knoten im Cluster ein Netzwerkverbindungsproblem haben. Stellen Sie sicher, dass alle Knoten über Ping erreichbar sind.
- Wirkung
Wenn die Kommunikation innerhalb des Clusters unterbrochen wird, treten Probleme bei der Datenbankreplikation auf.
2. Fehler bei der umgekehrten DNS-Suche.
- Ursache
Dieser Fehler wird verursacht, wenn die umgekehrte DNS-Suche auf einem Knoten fehlschlägt. Sie können jedoch überprüfen, ob der DNS konfiguriert ist und ordnungsgemäß funktioniert, wenn Sie die folgenden Befehle verwenden:
utils network eth0 all - Shows the DNS configuration (if present) utils network host <ip address/Hostname> - Checks for resolution of ip address/Hostname
- Wirkung
Wenn der DNS nicht ordnungsgemäß funktioniert, kann es bei der Definition der Server und der Verwendung der Hostnamen zu Problemen mit der Datenbankreplikation kommen.
-
NTP-Erreichbarkeit (Netzwerkzeit-Protokoll):
Das NTP ist dafür verantwortlich, die Uhrzeit des Servers mit der Referenzuhr zu synchronisieren. Der Publisher synchronisiert die Uhrzeit immer mit dem Gerät, dessen IP-Adresse als NTP-Server aufgeführt ist. Die Abonnenten dagegen synchronisieren die Uhrzeit mit dem Publisher.
Es ist äußerst wichtig, dass das NTP voll funktionsfähig ist, um Probleme bei der Datenbankreplikation zu vermeiden.
Es ist wichtig, dass die NTP-Schicht (Anzahl der Hops zum übergeordneten Referenzuhr) kleiner als 5 ist, da sie sonst als unzuverlässig gilt.
Gehen Sie folgendermaßen vor, um den NTP-Status zu überprüfen:
- Verwenden Sie den Befehl utils diagnose test, um die Ausgabe zu überprüfen, wie in dieser Abbildung dargestellt.
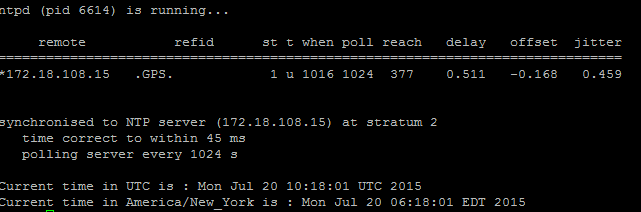
2. Außerdem können Sie den folgenden Befehl ausführen:
utils ntp status
Schritt 5: Überprüfen Sie den Verbindungsstatus aller Knoten, und stellen Sie sicher, dass sie authentifiziert sind.
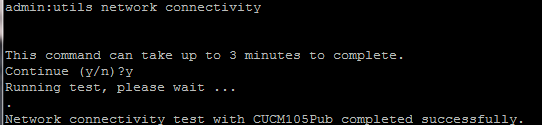
- Wenn nach Abschluss von Schritt 4 keine Probleme gemeldet werden, führen Sie den Befehl utils network connectivity auf allen Knoten aus, um zu überprüfen, ob die Verbindung zu den Datenbanken erfolgreich ist (siehe Abbildung).

2. Wenn Sie als Fehlermeldung "TCP/UDP-Pakete können nicht gesendet werden" erhalten, überprüfen Sie Ihr Netzwerk auf Neuübertragungen oder blockieren Sie die TCP/UDP-Ports. Der Befehl show network cluster überprüft die Authentifizierung aller Knoten.
3. Wenn der Status des Knotens nicht authentifiziert ist, stellen Sie sicher, dass die Netzwerkverbindung und das Sicherheitskennwort auf allen Knoten identisch sind, wie in diesem Bild gezeigt.
Über die Links können Sie die Sicherheitskennwörter ändern/wiederherstellen:
So setzen Sie Kennwörter auf CUCM zurück
Wiederherstellung des CUCM-Betriebssystemadministrator-Passworts
Schritt 6: Der Befehl Utils Dbreplication RuntimeState wird nicht synchronisiert oder nicht angefordert angezeigt
Sie müssen wissen, dass die Datenbankreplikation eine netzwerkintensive Aufgabe ist, da sie die tatsächlichen Tabellen an alle Knoten im Cluster weiterleitet. Stellen Sie Folgendes sicher:
-
Die Knoten befinden sich im selben Rechenzentrum/am selben Standort: Alle Knoten sind mit einer relativ geringen Round Trip Time (RTT) erreichbar. Wenn der RTT-Wert ungewöhnlich hoch ist, überprüfen Sie die Netzwerkleistung.
-
Die Knoten sind über das Wide Area Network (WAN) verteilt: Stellen Sie sicher, dass die Knoten über Netzwerkverbindungen mit deutlich weniger als 80 ms verfügen. Wenn einige Knoten nicht in der Lage sind, sich am Replikationsprozess zu beteiligen, erhöhen Sie den Parameter wie gezeigt auf einen höheren Wert.
utils dbreplication setprocess <1-40>
Anmerkung: Wenn Sie diesen Parameter ändern, wird die Performance der Replikationseinrichtung verbessert, jedoch werden zusätzliche Systemressourcen verbraucht.
-
Das Replikations-Timeout basiert auf der Anzahl der Knoten im Cluster: Das Replikations-Timeout (Standard: 300 Sekunden) ist die Zeit, in der der Publisher auf alle Abonnenten wartet, um ihre definierten Nachrichten zu senden. Berechnen Sie das Replikations-Timeout basierend auf der Anzahl der Knoten im Cluster.
Server 1-5 = 1 Minute Per Server Servers 6-10 = 2 Minutes Per Server Servers >10 = 3 Minutes Per Server.
Example: 12 Servers in Cluster : Server 1-5 * 1 min = 5 min, + 6-10 * 2 min = 10 min, + 11-12 * 3 min = 6 min, Repltimeout should be set to 21 Minutes.
Befehle zum Überprüfen/Festlegen des Replikations-Timeouts:
show tech repltimeout ( To check the current replication timeout value ) utils dbreplication setrepltimeout ( To set the replication timeout )
Die Schritte 7 und 8 müssen ausgeführt werden, wenn die Checkliste erfüllt ist:
Checkliste:
- Alle Knoten sind miteinander verbunden. Siehe Schritt 5.
- RPC ist erreichbar. Siehe Schritt 3.
- Konsultieren Sie das Cisco TAC, bevor Sie mit den Schritten 7 und 8 fortfahren, falls der Knoten größer als 8 ist.
- Führen Sie das Verfahren außerhalb der Geschäftszeiten durch.
Schritt 7: Reparieren aller/selektiven Tabellen für die Datenbankreplikation
Wenn der Befehl utils dbreplication runtimestate anzeigt, dass es Tabellen mit Fehlern/nicht übereinstimmende Tabellen gibt, führen Sie folgenden Befehl aus:
Utils dbreplication repair all
Führen Sie den Befehl utils dbreplication runtimestate aus, um den Status erneut zu überprüfen.
Fahren Sie mit Schritt 8 fort, wenn sich der Status nicht ändert.
Schritt 8: Zurücksetzen der Datenbankreplikation von Grund auf
Informationen zum Zurücksetzen der Datenbankreplikation und zum Starten des Prozesses von Grund auf finden Sie in der Sequenz.
utils dbreplication stop all (Only on the publisher) utils dbreplication dropadmindb (First on all the subscribers one by one then the publisher) utils dbreplication reset all ( Only on the publisher )
Um den Prozess zu überwachen, führen Sie den Befehl RTMT/utils dbreplication runtimestate aus.
Beachten Sie die Reihenfolge zum Zurücksetzen der Datenbankreplikation für einen bestimmten Knoten:
utils dbreplication stop <sub name/IP> (Only on the publisher) utils dbreplcation dropadmindb (Only on the affected subscriber) utils dbreplication reset <sub name/IP> (Only on the publisher )
Falls Sie das Cisco TAC für weitere Unterstützung erreichen, stellen Sie sicher, dass die folgenden Ergebnisse und Berichte bereitgestellt werden:
utils dbreplication runtimestate utils diagnose test utils network connectivity
Berichte:
- Der Cisco Unified Reporting CM-Datenbankbericht (siehe Schritt 2).
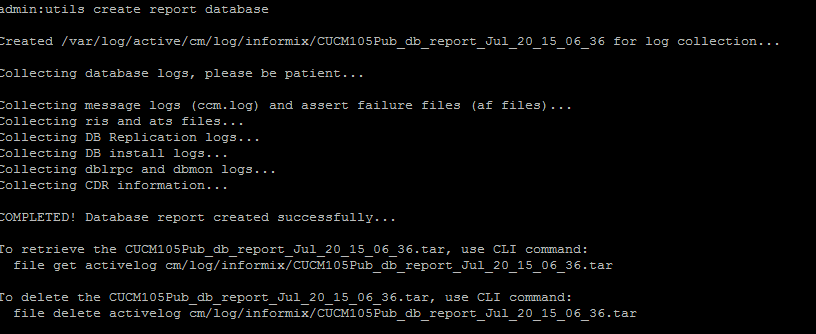
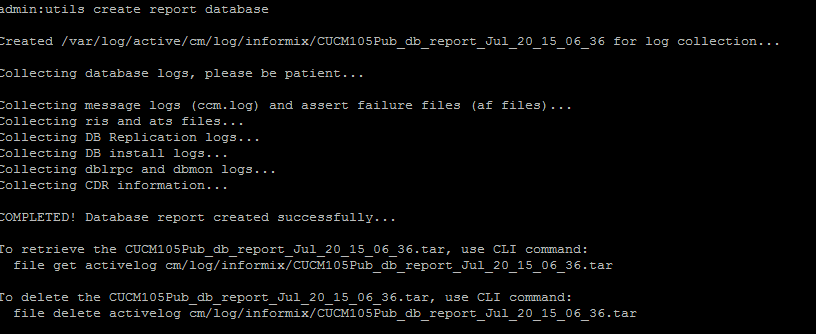
- Der Befehl utils create report database aus der CLI. Laden Sie die TAR-Datei herunter, und verwenden Sie einen SFTP-Server.
Zugehörige Informationen
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
4.0 |
12-Nov-2024 |
Aktualisierter Alternativer Text, maschinelle Übersetzung und Formatierung. |
1.0 |
13-Aug-2021 |
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Kaustubh AcharekarCisco TAC Engineer
- Jose Pablo Villalobos UrenaCisco TAC Engineer
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)