About Policy-Based Redirect
Cisco Application Centric Infrastructure (ACI) policy-based redirect (PBR) enables provisioning service appliances, such as firewalls or load balancers. Typical use cases include provisioning service appliances that can be pooled, tailored to application profiles, scaled easily, and have reduced exposure to service outages. PBR simplifies the deployment of service appliances by enabling the provisioning consumer and provider endpoint groups to be all in the same virtual routing and forwarding (VRF) instance. PBR deployment consists of configuring a route redirect policy and a cluster redirect policy, and creating a service graph template that uses the route and cluster redirect policies. After the service graph template is deployed, use the service appliance by enabling endpoint groups to consume the service graph provider endpoint group. This can be further simplified and automated by using vzAny. While performance requirements may dictate provisioning dedicated service appliances, virtual service appliances can also be deployed easily using PBR.
The following figure illustrates the use case of redirecting specific traffic to the firewall:

In this use case, you must create two subjects. The first subject permits HTTP traffic, which then gets redirected to the firewall. After the traffic passes through the firewall, it goes to the Web endpoint. The second subject permits all traffic, which captures traffic that is not redirected by the first subject. This traffic goes directly to the Web endpoint.
The following figure illustrates a sample ACI PBR physical topology:

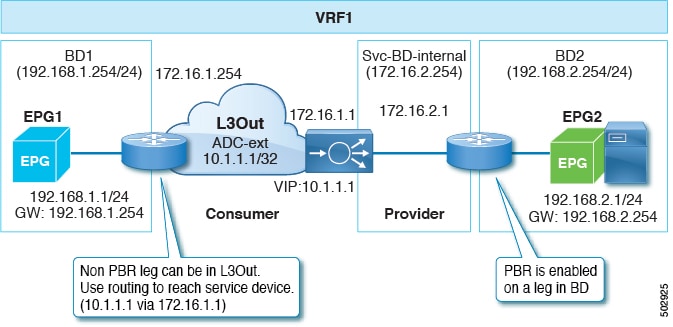
The following figure illustrates a sample ACI PBR logical topology:

While these examples illustrate simple deployments, ACI PBR enables scaling up mixtures of both physical and virtual service appliances for multiple services, such as firewalls and server load balancers.
Guidelines and Limitations for Configuring Policy-Based Redirect
Observe the following guidelines and limitations when planning policy-based redirect (PBR) service nodes:
-
A firewall (or a device that does not perform IP address translation) is inserted by using PBR for both directions.
-
A load balancer (or a device that perorms IP address translation) is inserted by using unidirectional PBR. The destination IP address (VIP address or NAT'd IP address) for the other direction is owned by the device. The exception is Layer 2 direct server return, where the return traffic does not come back to the load balancer.
-
The source MAC address of the packet can be rewritten because of the need to route the packet with PBR inside the fabric. The time-to-live (TTL) field in the IP address header will be decremented by as many times as the packet is routed within the fabric.
-
Select the same action for both service legs. In other words, if you select the deny action for the internal service leg, you should also select the deny action for the external service leg.
-
L3Out EPGs and regular EPGs can be consumer or provider EPGs.
-
L2Out EPGs cannot be either consumer or provider EPGs.
-
For a Cold Standby active/standby deployment, configure the service nodes with the MAC address of the active deployment. In a Cold Standby active/standby deployment, when the active node goes down, the standby node takes over the MAC address of active node.
-
You must provide the next-hop service node IP address.
-
Prior to the 5.2(1) release, you must provide the virtual MAC address. Beginning with the 5.2(1) release, you can optionally choose not to provide the virtual MAC address and instead let the Cisco Application Policy Infrastructure Controller (Cisco APIC) detect the address dynamically.
-
If you provision service appliances in the same bridge domain, you must use Cisco Nexus 9300-EX and 9300-FX platform leaf switches.
-
When downgrading from the Cisco APIC release 3.1, an internal code checks whether the policy-based redirect bridge domain uses the same bridge domain as a consumer or a provider. If it does, then the fault is disabled during the downgrade as such a configuration is not supported in earlier Cisco APIC versions.
-
If you downgrade from the 5.2(1) or later release to a release earlier than 5.2(1), you must remove all PBR-related configurations that include PBR-related features from the 5.2 releases and you must remove the associated service graphs. For example:
-
Remove a device selection policy that uses a PBR destination in an L3Out.
-
Remove a Layer 4 to Layer 7 services device that uses the enhanced lag policy.
-
Remove an IP SLA monitoring policy that uses the HTTP SLA type.
-
Remove a PBR destination that does not have the destination MAC address configured.
-
-
The service appliance, source, and bridge domain can be in the same VRF instance.
-
For Cisco N9K-93128TX, N9K-9396PX, N9K-9396TX, N9K-9372PX, and N9K-9372TX switches, the service appliance must not be in the same leaf switch as either the source or destination endpoint group. For Cisco N9K-C93180YC-EX and N9K-93108TC-EX switches, the service appliance can be in the same leaf switch as either the source or destination endpoint group.
-
PBR node interfaces are not supported on FEX host interfaces. A PBR node interface must be connected under leaf down link interface, not under FEX host interface. Consumer and provider endpoints can be connected under FEX host interfaces.
-
The service appliance can only be in a bridge domain.
-
The contract offered by the service appliance provider endpoint group can be configured to
allow-all, but traffic should be routed by the Cisco Application Centric Infrastructure (Cisco ACI) fabric. -
If you use the Cisco Nexus 9300-EX and 9300-FX platform leaf switches, it is not necessary for you to have the endpoint dataplane learning disabled on policy-based redirect bridge domains. During service graph deployment, the endpoint dataplane learning will be automatically disabled only for policy-based redirect node EPG. If you use non-EX and non-FX platform leaf switches, you must have the endpoint dataplane learning disabled on policy-based redirect bridge domains. The policy-based redirect bridge domain must have the endpoint dataplane learning disabled.
-
You can attach a service graph with PBR to a contract subject. The intra-EPG contract with the service graph cannot be used as an inter-EPG contract at the same time. You must use a separate contract for inter-EPG and intra-EPG communication when used with a service graph that has redirect enabled.
-
You can use the filters-from-contract option in the service graph template to use the specific filter of the contract subject where the service graph is attached, instead of the default filter for zoning-rules that do not include consumer EPG class ID as source or destination. For zoning-rules that have consumer EPG class ID as source or destination, it uses the specific filter regardless the option.
-
Multi-node policy-based redirect (multi-node PBR):
-
Supports up to five function nodes in a service graph that can be configured for policy-based redirect.
-
When using a multi-node PBR service chain, all the service devices have to be either in local leaf switch or they have to be connected to a remote leaf switch, but should not spread across both.
-
Supported topology:
In this topology, RL means remote leaf switch and LL means local leaf switch that is under main location, and not under remote leaf switch.
-
N1(LL)--N2(LL)--N3(LL): All the devices are connected to local leaf switches not distributed across main location and remote leaf switch.
-
N1(RL)-N2(RL)--N3(RL): All the devices are connected to remote leaf switches.
-
-
Topology not supported:
-
N1(LL)--N2(RL)--N3(LL): Service devices are distributed across local leaf switches and remote leaf switches.
-
-
-
Multi-node PBR Layer 3 destination guidelines for load balancers:
-
Layer 3 destination upgrade: The Layer 3 destination (VIP) parameter is enabled by default after the upgrade. No issues will occur from this because if the PBR policy was not configured on a specific service node (prior to the 3.2(1) release), the node connector was treated as an Layer 3 destination and will continue to be in the new Cisco APIC release.
-
Traffic does not always need to be destined to only consumer/provider.
-
In the forward direction, the traffic is destined to load balancer VIP address.
-
In the reverse direction, if SNAT is enabled, the traffic is destined to the load balancer’s internal leg.
-
In both directions, enable (check) Layer 3 destination (VIP) on the Logical Interface Context.
-
Enable (check) Layer 3 destination (VIP) in both directions to allow you to switch from SNAT to No-SNAT on the load balancer internal by configuring the PBR policy on the internal side.
-
If SNAT is disabled:
-
Reverse direction traffic is destined to consumer but not to load balancer internal leg (enable PBR policy on the internal leg).
-
Layer 3 destination (VIP) is not applicable in this case because a PBR policy is applied.
-
-
-
-
Multicast and broadcast traffic redirection is not supported.
-
If you change a redirect policy's destination to a different group, the Cisco APIC raises a fault due to the change and the policy's operational status becomes disabled. You must clear the fault to re-enable the policy.
-
An intra-EPG or intra-external EPG contract with PBR must not be used for the inter-EPG contract.
-
When Migrating endpoints from a non-PBR EPG to a PBR EPG, the remote endpoints on the destination leaf switches do not clear their remote endpoints, which have the sclass details of the old non-PBR EPG. This issue occurs when the destination leaf switch with the remote endpoint is a switch with the -EX, -FX, or -GX suffix in the product ID. This issue does not occur with switches that have -FX2, -GX2, or a later suffix in the product ID.
If you encounter this issue, you can manually clear the remote endpoint by using the following CLI command:
vsh -c "clear system internal epm endpoint key vrf vrf_name ip ip_name" -
Supported policy-based redirect configurations include the following:
Figure 4. Policy-based Redirect in the Same VRF Instance 
Figure 5. Policy-based Redirect With Different VRF Instances 
Figure 6. Policy-based Redirect With an L3Out Destination 
-
Unsupported policy-based redirect configurations include the following:
Figure 7. Unsupported Policy-based Redirect Configurations 
Configuring Policy-Based Redirect Using the GUI
The following procedure configures policy-based redirect (PBR) using the GUI.
Procedure
|
Step 1 |
On the menu bar, choose . |
||||
|
Step 2 |
In the Work pane, double click the tenant's name. |
||||
|
Step 3 |
In the Navigation pane, choose . |
||||
|
Step 4 |
In the Work pane, choose . |
||||
|
Step 5 |
In the Create L4-L7 Devices dialog box, complete the fields as required. In the General section, the Service Type can be Firewall, ADC, or Other.
|
||||
|
Step 6 |
In the Navigation pane, choose . |
||||
|
Step 7 |
In the Work pane, choose . |
||||
|
Step 8 |
In the Create L4-L7 Service Graph Template dialog box, perform the following actions: |
||||
|
Step 9 |
In the Navigation pane, choose Tenant tenant_name > Policies > Protocol > L4-L7 Policy Based Redirect. |
||||
|
Step 10 |
In the Work pane, choose . |
||||
|
Step 11 |
In the Create L4-L7 Policy Based Redirect dialog box, complete the fields as required. This policy-based redirect policy is for the consumer connector. |
||||
|
Step 12 |
Create another policy-based redirect policy for the provider connector. |
||||
|
Step 13 |
In the Navigation pane, choose . Choose the service graph template that you just created. |
||||
|
Step 14 |
Right click the service graph template and choose Apply L4-L7 Service Graph Template. |
||||
|
Step 15 |
In the Apply L4-L7 Service Graph Template to EPGs dialog box, perform the following actions:
|
Configuring Policy-Based Redirect Using the NX-OS-Style CLI
The example commands in this procedure include the route redirect, the cluster redirect, and the graph deployment. The device is created under tenant T1.
Procedure
|
Step 1 |
Create the device cluster. Example: |
|
Step 2 |
Under tenant PBRv6_ASA_HA_Mode, deploy the PBR service graph instance. Example: |
|
Step 3 |
Create a contract for PBR with the filter match IP protocol. Under the subject, specify the Layer 4 to Layer 7 service graph name. The contract offered by the service
appliance provider endpoint group cannot be configured with the Example: |
|
Step 4 |
Create a bridge domain for the client and server endpoint group. Both the client and server are in the same VRF instance. Example: |
|
Step 5 |
Create a separate bridge domain for the external and internal leg of the firewall. PBR requires the learning of the source VTEP on remote leaf switches to be disabled, which is done using the no ip learning command. Example: |
|
Step 6 |
Create the application profile and specify the endpoint groups. Example: |
|
Step 7 |
Specify the default gateway for the bridge domains. Example: |
|
Step 8 |
Import the device from tenant T1. Example: |
|
Step 9 |
Create the service graph using the service redirect policy. Example: |
|
Step 10 |
Create the service redirect policy for the external and internal legs. IPv6 addresses are used in this example; you can also specify IPv4 addresses using the same command. Example: |
Verifying a Policy-Based Redirect Configuration Using the NX-OS-Style CLI
After you have configured policy-based redirect, you can verify the configuration using the NX-OS-style CLI.
Procedure
|
Step 1 |
Show the running configuration of the tenant. Example: |
|
Step 2 |
Show the running configuration of the tenant and its service graph. Example: |
|
Step 3 |
Show the service graph configuration. Example: |

















 Feedback
Feedback