About High Availability (Failover)
A high availability or failover setup joins two devices so that if the primary device fails, the secondary device can take over. This helps you keep your network operational in case of device failure.
Configuring high availability requires two identical FTD devices connected to each other through a dedicated failover link and, optionally, a state link. The two units constantly communicate over the failover link to determine the operating status of each unit and to synchronize deployed configuration changes. The system uses the state link to pass connection state information to the standby device, so that if a failover occurs, user connections are preserved.
The units form an active/standby pair, where one unit is the active unit and passes traffic. The standby unit does not actively pass traffic, but synchronizes configuration and other state information from the active unit.
The health of the active unit (hardware, interfaces, software, and environmental status) is monitored to determine if specific failover conditions are met. If those conditions are met, the active unit fails over to the standby unit, which then becomes active.
About Active/Standby Failover
Active/Standby failover lets you use a standby FTD device to take over the functionality of a failed unit. When the active unit fails, the standby unit becomes the active unit.
Primary/Secondary Roles and Active/Standby Status
The main differences between the two units in a failover pair are related to which unit is active and which unit is standby, namely which IP addresses to use and which unit actively passes traffic.
However, a few differences exist between the units based on which unit is primary (as specified in the configuration) and which unit is secondary:
-
The primary unit always becomes the active unit if both units start up at the same time (and are of equal operational health).
-
The primary unit MAC addresses are always coupled with the active IP addresses. The exception to this rule occurs when the secondary unit becomes active and cannot obtain the primary unit MAC addresses over the failover link. In this case, the secondary unit MAC addresses are used.
Active Unit Determination at Startup
The active unit is determined by the following:
-
If a unit boots and detects a peer already running as active, it becomes the standby unit.
-
If a unit boots and does not detect a peer, it becomes the active unit.
-
If both units boot simultaneously, then the primary unit becomes the active unit, and the secondary unit becomes the standby unit.
Failover Events
In Active/Standby failover, failover occurs on a unit basis.
The following table shows the failover action for each failure event. For each failure event, the table shows the failover policy (failover or no failover), the action taken by the active unit, the action taken by the standby unit, and any special notes about the failover condition and actions.
|
Failure Event |
Policy |
Active Unit Action |
Standby Unit Action |
Notes |
|---|---|---|---|---|
|
Active unit failed (power or hardware) |
Failover |
n/a |
Become active Mark active as failed |
No hello messages are received on any monitored interface or the failover link. |
|
Formerly active unit recovers |
No failover |
Become standby |
No action |
None. |
|
Standby unit failed (power or hardware) |
No failover |
Mark standby as failed |
n/a |
When the standby unit is marked as failed, then the active unit does not attempt to fail over, even if the interface failure threshold is surpassed. |
|
Failover link failed during operation |
No failover |
Mark failover link as failed |
Mark failover link as failed |
You should restore the failover link as soon as possible because the unit cannot fail over to the standby unit while the failover link is down. |
|
Failover link failed at startup |
No failover |
Become active Mark failover link as failed |
Become active Mark failover link as failed |
If the failover link is down at startup, both units become active. |
|
State link failed |
No failover |
No action |
No action |
State information becomes out of date, and sessions are terminated if a failover occurs. |
|
Interface failure on active unit above threshold |
Failover |
Mark active as failed |
Become active |
None. |
|
Interface failure on standby unit above threshold |
No failover |
No action |
Mark standby as failed |
When the standby unit is marked as failed, then the active unit does not attempt to fail over even if the interface failure threshold is surpassed. |
Failover and Stateful Failover Links
The failover link is a dedicated connection between the two units. The stateful failover link is also a dedicated connection, but you can either use the one failover link as a combined failover/state link, or you can create a separate, dedicated state link. If you use just the failover link, the stateful information also goes over that link: you do not lose stateful failover capability.
By default, the communications on the failover and stateful failover links are plain text (unencrypted). You can encrypt the communications for enhanced security by configuring an IPsec encryption key.
The following topics explain these interfaces in more detail, and include recommendations on how to wire the devices for the best results.
Failover Link
The two units in a failover pair constantly communicate over a failover link to determine the operating status of each unit and to synchronize configuration changes.
The following information is communicated over the failover link:
-
The unit state (active or standby).
-
Hello messages (keep-alives).
-
Network link status.
-
MAC address exchange.
-
Configuration replication and synchronization.
-
System database updates, including VDB and rules, but not including the geolocation and Security Intelligence databases. Each system separately downloads geolocation and Security Intelligence updates. If you create an update schedule, these should remain synchronized. However, if you do a manual geolocation or Security Intelligence update on the active device, you should also do one on the standby device.
 Note |
Eventing, reporting, and audit log data are not synchronized. Event viewer and the dashboards show data related to the given unit only. In addition, deployment history, task history, and other audit log events are not synchronized. |
Stateful Failover Link
The system uses the state link to pass connection state information to the standby device. This information helps the standby unit maintain existing connections when a failover occurs.
Using a single link for both the failover and stateful failover links is the best way to conserve interfaces. However, you must consider a dedicated interface for the state link and failover link, if you have a large configuration and a high traffic network.
Interfaces for the Failover and State Links
You can use an unused, but enabled, data interface (physical) as the failover link; however, you cannot specify an interface that is currently configured with a name. The failover link interface is not configured as a normal networking interface; it exists for failover communication only. This interface can only be used for the failover link (and also for the state link). You cannot use a management interface or a subinterface for failover.
The FTD device does not support sharing interfaces between user data and the failover link.
See the following guidelines for sizing the failover and state link:
-
Firepower 4100/9300—We recommend that you use a 10 GB data interface for the combined failover and state link.
-
All other models—1 GB interface is large enough for a combined failover and state link.
Connecting the Failover and Stateful Failover Interfaces
You can use any unused data physical interfaces as the failover link and optional dedicated state link. However, you cannot select an interface that is currently configured with a name, or one that has subinterfaces. The failover and stateful failover link interfaces are not configured as normal networking interfaces. They exist for failover communication only, and you cannot use them for through traffic or management access.
Because the configuration is synchronized between the devices, you must select the same port number for each end of a link. For example, GigabitEthernet1/3 on both devices for the failover link.
Connect the failover link, and the dedicated state link if used, in one of the following two ways:
-
Using a switch, with no other device on the same network segment (broadcast domain or VLAN) as the failover interfaces of the FTD device. A dedicated state link has the same requirement, but must be on a different network segment than the failover link.
Note
The advantage of using a switch is that if one of the unit’s interfaces goes down, it is easy to troubleshoot which interface failed. If you are using a direct cable connection, if one interface fails, the link is brought down on both peers, which makes it difficult to determine which device is at fault.
-
Using an Ethernet cable to connect the units directly, without the need for an external switch. The FTD supports Auto-MDI/MDIX on its copper Ethernet ports, so you can either use a crossover cable or a straight-through cable. If you use a straight-through cable, the interface automatically detects the cable and swaps one of the transmit/receive pairs to MDIX.
For optimum performance when using long distance failover, the latency for the state link should be less than 10 milliseconds and no more than 250 milliseconds. If latency is more than 10 milliseconds, some performance degradation occurs due to retransmission of failover messages.
Avoiding Interrupted Failover and Data Links
We recommend that failover links and data interfaces travel through different paths to decrease the chance that all interfaces fail at the same time. If the failover link is down, the FTD device can use the data interfaces to determine if a failover is required. Subsequently, the failover operation is suspended until the health of the failover link is restored.
See the following connection scenarios to design a resilient failover network.
Scenario 1—Not Recommended
If a single switch or a set of switches are used to connect both failover and data interfaces between two FTD devices, then when a switch or inter-switch-link is down, both FTD devices become active. Therefore, the two connection methods shown in the following figures are not recommended.


Scenario 2—Recommended
We recommend that failover links not use the same switch as the data interfaces. Instead, use a different switch or use a direct cable to connect the failover link, as shown in the following figures.
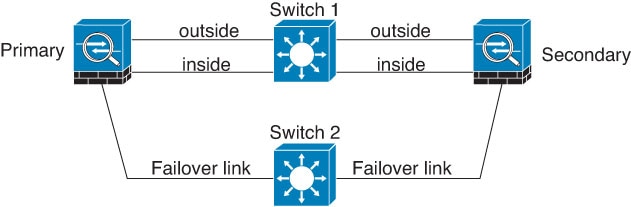
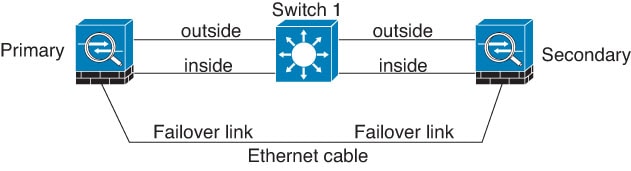
Scenario 3—Recommended
If the FTD data interfaces are connected to more than one set of switches, then a failover link can be connected to one of the switches, preferably the switch on the secure (inside) side of network, as shown in the following figure.
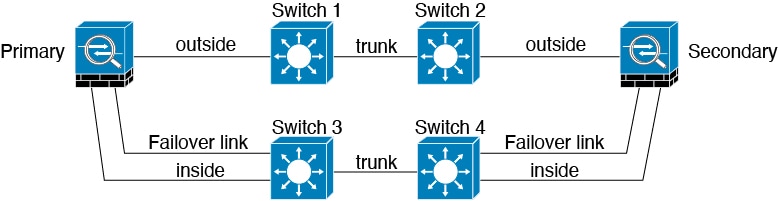
How Stateful Failover Affects User Connections
The active unit shares connection state information with the standby unit. This means that the standby unit can maintain certain types of connections without impacting the user.
However, there are some types of connections that do not support stateful failover. For these connections, the user will need to reestablish the connection if there is a failover. Often times, this happens automatically based on the behavior of the protocol used in the connection.
The following topics explain which features are supported or not supported for stateful failover.
Supported Features
For Stateful Failover, the following state information is passed to the standby FTD device:
-
NAT translation table.
-
TCP and UDP connections and states, including HTTP connection states. Other types of IP protocols, and ICMP, are not parsed by the active unit, because they get established on the new active unit when a new packet arrives.
-
Snort connection states, inspection results, and pin hole information, including strict TCP enforcement.
-
The ARP table
-
The Layer 2 bridge table (for bridge groups)
-
The ISAKMP and IPsec SA table
-
GTP PDP connection database
-
SIP signaling sessions and pin holes.
-
Static and dynamic routing tables—Stateful Failover participates in dynamic routing protocols, like OSPF and EIGRP, so routes that are learned through dynamic routing protocols on the active unit are maintained in a Routing Information Base (RIB) table on the standby unit. Upon a failover event, packets travel normally with minimal disruption to traffic because the active secondary unit initially has rules that mirror the primary unit. Immediately after failover, the re-convergence timer starts on the newly active unit. Then the epoch number for the RIB table increments. During re-convergence, OSPF and EIGRP routes become updated with a new epoch number. Once the timer is expired, stale route entries (determined by the epoch number) are removed from the table. The RIB then contains the newest routing protocol forwarding information on the newly active unit.
Note
Routes are synchronized only for link-up or link-down events on an active unit. If the link goes up or down on the standby unit, dynamic routes sent from the active unit may be lost. This is normal, expected behavior.
-
DHCP Server—DHCP address leases are not replicated. However, a DHCP server configured on an interface will send a ping to make sure an address is not being used before granting the address to a DHCP client, so there is no impact to the service. State information is not relevant for DHCP relay or DDNS.
-
Access control policy decisions—Decisions related to traffic matching (including URL, URL category, geolocation, and so forth), intrusion detection, malware, and file type are preserved during failover. However, for connections being evaluated at the moment of failover, there are the following caveats:
-
AVC—App-ID verdicts are replicated, but not detection states. Proper synchronization occurs as long as the App-ID verdicts are complete and synchronized before failover occurs.
-
Intrusion detection state—Upon failover, once mid-flow pickup occurs, new inspections are completed, but old states are lost.
-
File malware blocking—The file disposition must become available before failover.
-
File type detection and blocking—The file type must be identified before failover. If failover occurs while the original active device is identifying the file, the file type is not synchronized. Even if your file policy blocks that file type, the new active device downloads the file.
-
-
Passive user identity decisions from the identity policy, but not those gathered through active authentication through captive portal.
-
Security Intelligence decisions.
-
RA VPN—Remote access VPN end users do not have to reauthenticate or reconnect the VPN session after a failover. However, applications operating over the VPN connection could lose packets during the failover process and not recover from the packet loss.
-
From all the connections, only established ones will be replicated on the Standby ASA.
Unsupported Features
For Stateful Failover, the following state information is not passed to the standby FTD device:
-
Sessions in plaintext tunnels such as GRE or IP-in-IP. Sessions inside tunnels are not replicated and the new active node will not be able to reuse existing inspection verdicts to match the correct policy rules.
-
Decrypted TLS/SSL connections—The decryption states are not synchronized, and if the active unit fails, then decrypted connections will be reset. New connections will need to be established to the new active unit. Connections that are not decrypted (in other words, those that match a TLS/SSL Do Not Decrypt rule action) are not affected and are replicated correctly.
-
Multicast routing.
Configuration Changes and Actions Allowed on a Standby Unit
When operating in high-availability mode, you make configuration changes to the active unit only. When you deploy the configuration, the new changes are also transmitted to the standby unit.
However, some properties are unique to the standby unit. You can change the following on a standby unit:
-
Management IP address and gateway.
-
(CLI only.) The password for the admin user account and other local user accounts. You can make this change in the CLI only, you cannot make it in the FDM. Any local user will have to change their password on both units separately.
In addition, the following actions are available on a standby device.
-
High availability actions, such as suspend, resume, reset, and break HA, and switch modes between active and standby.
-
Dashboard and eventing data are unique per device, and are not synchronized. This includes custom views in Event Viewer.
-
Audit log information is unique per device.
-
Smart Licensing registration. However, you must enable or disable the optional licenses on the active unit, and the action is synchronized with the standby unit, which requests or releases the appropriate license.
-
Backup, but not restore. You must break HA on the unit to restore a backup. If the backup includes the HA configuration, the unit will rejoin the HA group.
-
Software upgrade installation.
-
Generating troubleshooting logs.
-
Manually updating the Geolocation or Security Intelligence databases. These databases are not synchronized between the units. If you create an update schedule, the units can independently maintain consistency.
-
You can view active the FDM user sessions, and delete sessions, from the page.





 Feedback
Feedback