Data Center Design Considerations
Available Languages
Table Of Contents
Data Center Design Considerations
Factors that Influence Scalability
Why Implement a Data Center Core Layer?
Why Use the Three-Tier Data Center Design?
Determining Maximum Number of VLANs
Data Center Design Considerations
This chapter describes factors that influence the enterprise data center design. The following topics are included:
•
Factors that Influence Scalability
Factors that Influence Scalability
Determining scalability is never an easy task because there are always unknown factors and inter-dependencies. This section examines some of the most common scalability-related questions that arise when designing a data center network.
Why Implement a Data Center Core Layer?
Do I need a separate core layer for the data center? Can I use my existing campus core?
The campus core can be used as the data center core. The recommendation is to consider the long-term requirements so that a data center core does not have to be introduced at a later date. Advance planning helps avoid disruption to the data center environment. Consider the following items when determining the right core solution:
•
•
•
Why Use the Three-Tier Data Center Design?
Why not connect servers directly to a distribution layer and avoid installing an access layer?
The three-tier approach consisting of the access, aggregation, and core layers permit flexibility in the following areas:
•
•
•
•
Why Deploy Services Switch?
When would I deploy Services Switch instead of just putting Services Modules in the Aggregation Switch?
Incorporating Services Switch into the data center design is desirable for the following reasons:
•
•
•
•
Determining Maximum Servers
What is the maximum number of servers that should be on an access layer switch? What is the maximum number of servers to an aggregation module?
The answer is usually based on considering a combination of oversubscription, failure domain sizing, and port density. No two data centers are alike when these aspects are combined. The right answer for a particular data center design can be determined by examining the following areas:
•
–
–
–
–
•
–
–
–
–
•
The data center, unlike other network areas, should be designed to have flexibility in terms of emerging services such as firewalls, SSL offload, server load balancing, AON, and future possibilities. These services will most likely require slots in the aggregation layer, which would limit the amount of 10GigE port density available.
Determining Maximum Number of VLANs
What is the maximum number of VLANs that can be supported in an aggregation module?
•
•
Figure 4-1 Graphed Average CPU Utilization with HSRP

Server Clustering
The goal of server clustering is to combine multiple servers so that they appear as a single unified system through special software and network interconnects. "Clusters" were initially used with the Digital Equipment Corporation VAX VMS Clusters in the late 1980s. Today, "clustering" is a more general term that is used to describe a particular type of grouped server arrangement that falls into the following four main categories:
•
Figure 4-2 High Availability Cluster
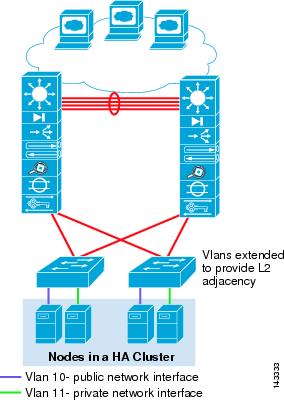
•
Figure 4-3 Network Load Balanced Clusters

•
Figure 4-4 Database Clusters

NIC Teaming
Servers with a single Network Interface Card (NIC) interface can have many single points of failure. The NIC card, the cable, and the switch to which it connects are all single points of failure. NIC teaming is a solution developed by NIC card vendors to eliminate this single point of failure by providing special drivers that allow two NIC cards to be connected to two different access switches or different line cards on the same access switch. If one NIC card fails, the secondary NIC card assumes the IP address of the server and takes over operation without disruption. The various types of NIC teaming solutions include active/standby and active/active. All solutions require the NIC cards to have Layer 2 adjacency with each other. NIC teaming solutions are common in the data center multi-tier model design and are shown in Figure 4-5.
Figure 4-5 NIC Teaming Configurations

Note the following:
•
•
Pervasive 10GigE
Customers are seeing the benefit of moving beyond Gigabit or Gigabit EtherChannel implementations to 10GigE, which includes benefits such as the following:
•
•
•
•
•
Many customers are also moving to 10GigE access layer uplinks in anticipation of future requirements. The implications relative to this trend are usually related to density in the aggregation layer.
A proven method of increasing aggregation layer 10GigE ports is to use multiple aggregation modules, as shown in Figure 4-6.
Figure 4-6 Multiple Aggregation Modules

Aggregation modules provide a way to scale 10GigE port requirements while also distributing CPU processing for spanning tree and HSRP. Other methods to increase port density include using the service layer switch, which moves service modules out of the aggregation layer and into a standalone chassis, making slots available for 10GigE ports. Other methods of improving 10GE density are in the access layer design topology used such as a looped square topology. More on this subject is covered in Chapter 2 "Data Center Multi-Tier Model Design," and Chapter 6 "Data Center Access Layer Design."
Server Consolidation
The majority of servers in the data center are underutilized in terms of CPU and memory; particularly the web server tier and development environment server resources. Virtual machine solutions are being used to solve this deficiency and to improve the use of server resources.
•
Figure 4-7 Multiple Virtual Machines

Virtual machine solutions can be attached to the network with multiple GE network interfaces, one for each virtual host implementation. Other implementations include the use of 802.1Q on GE or 10GE interfaces to connect virtual hosts directly to a specific VLAN over a single interface. Although 10GE interfaces are not supported on all virtual machine solutions available today, it is expected that this will change in the near future. This requirement could have implications on access layer platform selection, NIC teaming support, and in determining uplink oversubscription values.
Top of Rack Switching
The most common access layer topology in the enterprise today is based on the modular chassis Catalyst 6500 or 4500 Series platforms. This method has proven to be a very scalable method of building out server farms that are providing high density, high speed uplinks, and redundant power and processors. Although this approach has been very successful, it has certain challenges related to the environments of data centers. The enterprise data center is experiencing a large amount of growth in the sheer number of servers while at the same time server density has been improved with 1RU and blade server solutions. Three particular challenges that result from this trend are related to the following:
•
•
•
These challenges have forced customers to find alternative solutions by spacing out cabinets, modifying cable routes, or other means, including to not deploy high density server solutions. Another way that customers are seeking to solve some of these problems is by using a rack-based switching solution. By using 1RU top of rack switches, the server interface cables are kept in the cabinet, reducing the amount of cabling in the floor and thus reducing the cabling and cooling issues. Figure 4-8 shows both a modular (top) and rack-based (bottom) access layer approach.
Figure 4-8 Modular and 1RU Access Layers

The upper half of Figure 4-8 has the following characteristics:
•
•
•
The lower half of Figure 4-8 has the following characteristics:
•
•
•
•
When considering a 1RU top of rack switch implementation, the following should be considered:
•
•
•
•
Blade Servers
Blade-server chasses have become very popular in the enterprise data center, driven mostly by the IBM BladeCenter, HP BladeServer, and Dell Blade Server products. Although the blade server seeks to reduce equipment footprint, improve integration, and improve management, it has the following specific challenges related to designing and supporting the data center network:
•
•
•
•
•
Importance of Team Planning
Considering the roles of different personnel in an IT organization shows that there is a growing need for team planning with data center design efforts. The following topics demonstrate some of the challenges that the various groups in an IT organization have related to supporting a "business ready" data center environment:
•
•
•
These are all distinct but related issues that are growing in the enterprise data center and are creating the need for a more integrated team planning approach. If communication takes place at the start, many of the issues are addressed, expectations are set, and the requirements are understood across all groups.
 Feedback
Feedback