Overview
The ICSR feature provides the highest possible availability for continuous call processing without interrupting subscriber services. ICSR allows the operator to configure gateways for redundancy purposes. In the event of a gateway failure, ICSR allows sessions to be transparently routed around the failure, thus maintaining the user experience. ICSR also preserves session information and state.
The system supports ICSR between two instances that support ICSR in the same StarOS release. For combination VMs where more than one service type is in use, only those services that support ICSR can make use of ICSR.
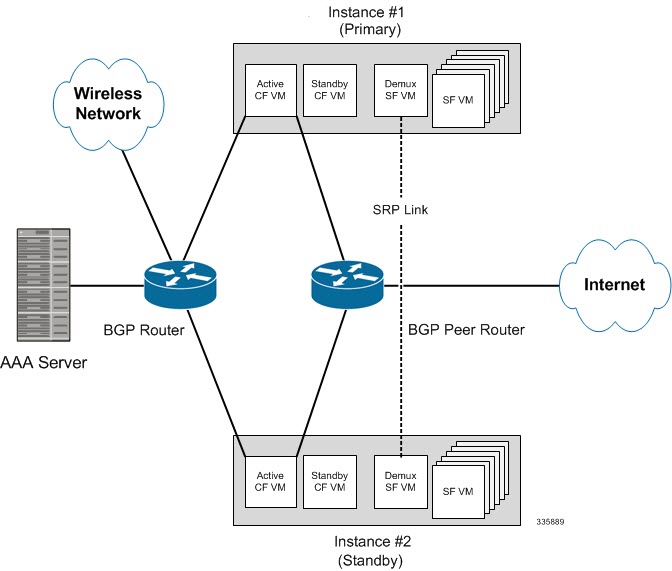
ICSR can provide redundancy for site/row/rack/host outages and major software faults. The two instances must be run on non-overlapping hosts and network interconnects. ICSR is only supported between identically configured VPC-DI or VPC-SI instances.
VPC-DI supports both L2 and L3 ICSR.
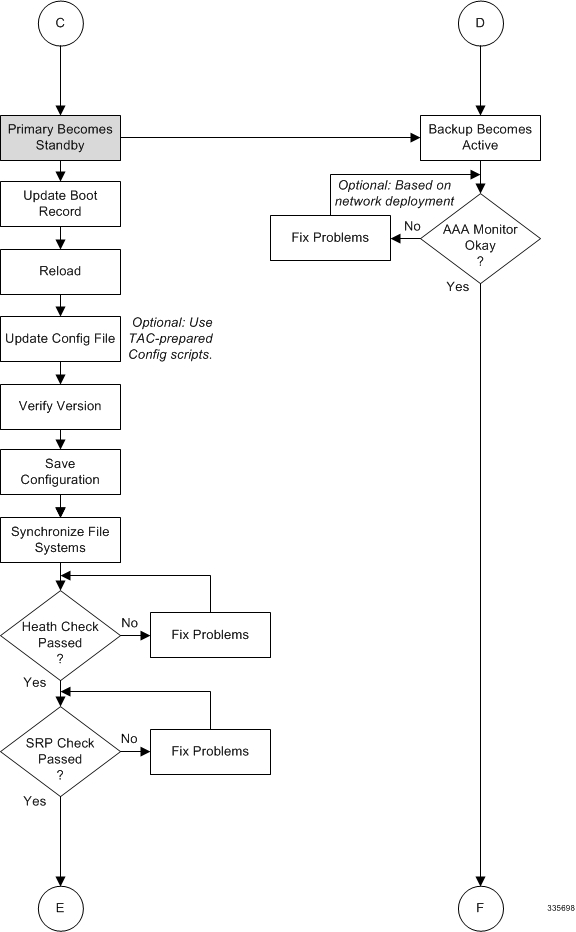
ICSR is implemented through the use of redundant virtual chassis. The virtual chassis for each VPC-DI instance are configured as primary and backup, with one being active and one standby. Both virtual chassis are connected to the same AAA server. A checkpoint duration timer controls when subscriber data is sent from the active chassis to the standby chassis. If the active chassis handling the call traffic goes out of service, the standby chassis transitions to the active state and continues processing the call traffic without interrupting the subscriber session.
The virtual chassis determine which is active through a proprietary TCP-based connection known as the Service Redundancy Protocol (SRP) link. The SRP link is used to exchange Hello messages between the active CFs in the primary and backup chassis and must be maintained for proper system operation. For additional information, refer to the Session Recovery chapter.
ICSR licenses are currently supported for the following services:
-
GGSN Gateway GPRS Support Node
-
P-GW Packet Data Network Gateway
-
S-GW Serving Gateway
-
SAE-GW System Architecture Evolution Gateway
L2TP Access Concentrator (LAC) functionality for ICSR is supported by the following protocol and services:
-
eGTP enhanced GPRS Tunneling Protocol
-
GGSN Gateway GPRS Support Node
-
P-GW Packet Data Network Gateway
-
SAEGW System Architecture Evolution Gateway
L2TP Access Concentrator (LAC) functionality for ICSR is not supported by the following service:
-
PMIP Proxy Mobile IP
L2TP Network Server (LNS) functionality for ICSR is not supported by any services.
 Note |
ICSR support for LAC requires a separate LAC license, as well as an Inter-Chassis Session Recovery license. |
Note |
Contact your Cisco account representative to verify whether a specific service supports ICSR as an option. |
Interchassis Communication
VPC-DI virtual chassis are configured to support ICSR communication using periodic Hello messages. These messages are sent by the active CF in each virtual chassis to notify the peer of its current state. The Hello message contains information about the virtual chassis such as its configuration and priority. A dead interval is used to set a time limit for a Hello message to be received from the chassis' CF peer. If the CF in the standby chassis does not receive a Hello message from the active CF in the active chassis within the dead interval, the standby virtual chassis transitions to the active state.
In situations where the SRP link goes out of service, a priority scheme is used to determine which chassis processes the session. The following priority scheme is used:
-
route modifier
-
chassis priority
-
MIO/UMIO/MIO2 MAC address
Checkpoint Messages
Checkpoint messages are sent from the active CF in the active virtual chassis to the active CF in the standby virtual chassis. These messages are sent at specific intervals and contain all the information needed to recreate the sessions on the standby chassis, if that chassis were to become active. Once a session exceeds the checkpoint duration, checkpoint data is collected on the session.
For additional information, refer to the ICSR Checkpointing appendix.
SRP CLI Commands
Exec Mode CLI Commands
Exec mode srp CLI configuration commands can be used to enable, disable and initiate SRP functions. The table below lists and briefly describes these commands. For complete information see the Exec Mode Commands (D-S) chapter of the Command Line Interface Reference.
| Command | Description |
|---|---|
| srp disable nack micro-chkpt-cmd | Disables the sending of NACK messages from the standby chassis that may trigger a full checkpoint from the active chassis. Sending full checkpoints increases SRP bandwidth. This command disables the NACK feature for a specific micro-checkpoint which is failing continuously. |
| srp initiate-audit manual-with-sync | Initiates a forced audit between ICSR chassis. This audit ensures that two ICSR peers are synchronized and identifies any discrepancies prior to scheduled or unscheduled switchover events. |
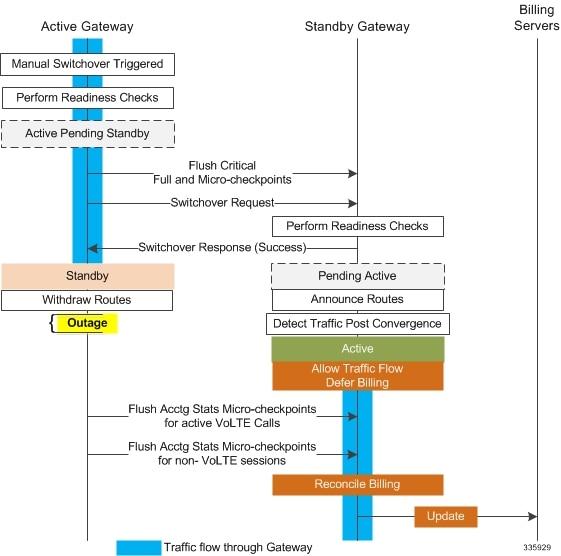
| srp initiate-switchover | Executes a forced switchover from active to inactive. When executed on the active chassis, this command switches the active chassis to the inactive state and the inactive chassis to an active state. See Note below. |
| srp reset-auth-probe-fail | Resets the auth probe monitor failure information to 0. |
| srp reset-diameter-fail | Resets the Diameter monitor failure information to 0. |
| srp terminate-post-process | Forcibly terminates post-switchover processing. |
| srp validate-configuration | Validates the configuration for an active chassis. |
| srp validate-switchover | Validates that both active and standby chassis are ready for a planned SRP switchover. |
Important |
For release 20.0 and higher, ICSR will verify session manager connectivity on both chassis prior to allowing a manual switchover. If one or more of the session managers in the active chassis is not connected on the standby chassis, the switchover will not be initiated. An error message will appear on the screen noting the number of session managers that are mismatched. The force keyword can be used to initiate the switchover despite the mismatch(es). The output of the show checkpoint statistics verbose command will not indicate "Ready" for a session manager instance ("smgr inst") in the "peer conn" column for any instance that is not connected to the peer chassis. |
show Commands
Exec mode show srp commands display a variety of information related to SRP functions. The table below lists and briefly describes these commands. For complete information on these commands, see the Exec Mode show Commands (Q-S) chapter of the Command Line Interface Reference.
| Command | Description |
|---|---|
| show srp audit-statistics | Displays statistics of an external audit. |
| show srp call-loss statistics | Displays the history of calls lost during switchover. |
| show srp checkpoint statistics | Displays check pointing statistics on session redundancy data (session managers, current call recovery records, etc.). |
| show srp info | Displays Service Redundancy Protocol information (context, chassis state, peer, connection state, etc.). |
| show srp monitor | Displays SRP monitor information. |
| show srp statistics | Displays SRP statistics (hello messages sent, configuration validation, resource messages, switchovers, etc.). |
For additional information about the output of show srp commands, see the Statistics and Counters Reference.
AAA Monitor
AAA servers are monitored using the authentication probe mechanism. AAA servers are considered Up if the authentication-probe receives a valid response. AAA servers are considered Down when the max-retries count specified in the configuration of the AAA server has been reached. SRP initiates a switchover when none of the configured AAA servers responds to an authentication probe. AAA probing is only performed on the active chassis.
Important |
A switchover event caused by an AAA monitoring failure is non-revertible. |
If the newly active chassis fails to monitor the configured AAA servers, it remains as the active chassis until one of the following occurs:
-
a manual switchover
-
another non-AAA failure event causes the system to switchover
-
a CLI command is used to clear the AAA failure flag and allow the chassis to switch to standby
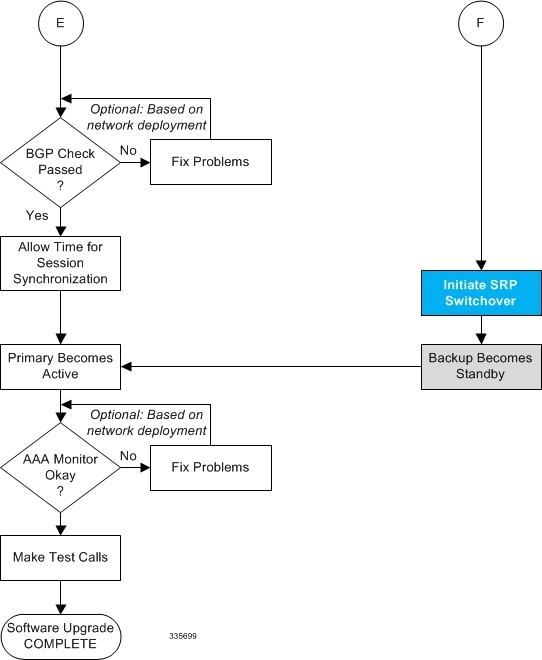
BGP Interaction
The Service Redundancy Protocol implements revertible switchover behavior via a mechanism that adjusts the route modifier value for the advertised loopback/IP Pool routes. The initial value of the route modifier value is determined by the chassis' configured role and is initialized to a value that is higher than a normal operational value. This ensures that in the event of an SRP link failure and an SRP task failure, the correct chassis is still preferred in the routing domain.
Important |
For ICSR you must configure busyout ip pool commands in the same order on Active and Standby chassis to avoid SRP validation failures. |
The Active and Standby chassis share current route modifier values. When BGP advertises the loopback and IP pool routes, it converts the route modifier into an autonomous systems (AS) path prepend count. The Active chassis always has a lower route modifier, and thus prepends less to the AS-path attribute. This causes the route to be preferred in the routing domain.
If communication on the SRP link is lost, and both chassis in the redundant pair are claiming to be Active, the previously Active chassis is still preferred since it is advertising a smaller AS-path into the BGP routing domain. The route modifier is incremented as switchover events occur. A threshold determines when the route modifier should be reset to its initial value to avoid rollover.
Requirements
ICSR configurations require the following:
-
Two VPC-DI instances or UGP instances identically configured for the same service types. The services must be bound on an SRP-activated loopback interface. Both instances must have identical hardware.
-
Three contexts:
-
Redundancy – to configure the primary and backup chassis redundancy.
-
Source – AAA configuration of the specified nas-ip-address must be the IP address of an interface bound to an HA, or any core network service configured within the same context.
-
Destination – to configure monitoring and routing to the PDN.
-
-
Border Gateway Protocol (BGP) – ICSR uses the route modifier to determine the chassis priority.
Important |
ICSR is a licensed Cisco feature. Verify that each chassis has the appropriate license before using these procedures. To do this, log in to both chassis and execute a show license information command. Look for "Inter-Chassis Session Recovery". If the chassis is not licensed, please contact your Cisco account representative. |
RADIUS and Diameter protocols can be monitored to trigger a switchover.
The following figure shows an ICSR network.



 Feedback
Feedback