Use the following procedure to migrate CDL half-rack configuration to full-rack configuration.
-
Set rack-1 as Active and rack-2 as Standby.

Prerequisite: Both sites must have full-rack resources though CDL is running using half-rack configuration.
Action: Make rack-1 as Active and rack-2 as Standby. No configuration change in CDL.
Post-validation: Traffic lands only on rack-1.
-
Set the system mode shutdown in rack-2.

Prerequisite: Rack-1 must be on active mode and rack-2 must be on standby mode.
Action: Do system mode shutdown in rack-2.
Post-validation: The mirror-maker on site-1 is not in running state.
-
Configure rack-2 as Standby. Configure full-rack CDL along with new configuration to enable the scale-up mode with prev-map-count
configured.
The following is a sample configuration:
configure
cdl datastore session mode scale-up
cdl datastore session index prev-map-count 2
Half-rack configuration without scaleup mode:
cdl datastore session
label-config session
index map 2
slot map 4
exit
Full-rack configuration with scaleup mode:
cdl datastore session
label-config session
mode scale-up
index map 4
index prev-map-count 2
slot map 8
exit
-
Enable system mode running of rack-2.

Prerequisite: Rack-1 must be active and rack-2 must be on standby with full-rack CDL configuration.
Action: Execute the system mode running in rack-2.
Post-validation: The mirror-maker in both sites must be in running state. The old indexes or slots in site-2 must be able to do initial sync
with remote peers.
-
Switch the traffic to rack-2.

Prerequisite: Rack-1 must be active and have full-rack resources with CDL running on half-rack configuration. Rack-2 must be on standby
and have full-rack resources with CDL running on full -ack configuration.
Action: Make rack-1 as standby and rack-2 as active. No configuration change is required in CDL.
Post-validation: The traffic lands on rack-2 only.
-
Enable system mode shutdown of rack-1.

Prerequisite: Rack-2 must be on active and rack-1 must be on standby.
Action:Do system mode shutdown in rack-1.
Post-validation: The mirror-maker on site-2 is not in running state.
-
Configure rack-1 as Standby. Configure full-rack CDL with the new configuration to enable scale-up mode with premap-count
configured.
The following is a sample configuration:
configure
cdl datastore session mode scale-up
cdl datastore session index prev-map-count 2
The full configuration updates the slot maps count and index maps count. The label configuration is added for newly added
slots and indexes.
-
Enable system mode running of rack-1.

Prerequisite: Rack-2 must be active and rack-1 must be on standby with full-rack CDL configuration.
Action: Do system mode running in rack-1.
Post-validation: The mirror-maker in both sites must be in a running state. All indexes and slots in site-1 must be able to do initial sync
with remote peers. Check in CEE alerts for CDL replication errors if any.
-
Trigger index rebalances using the CLI on rack-1 (Standby).
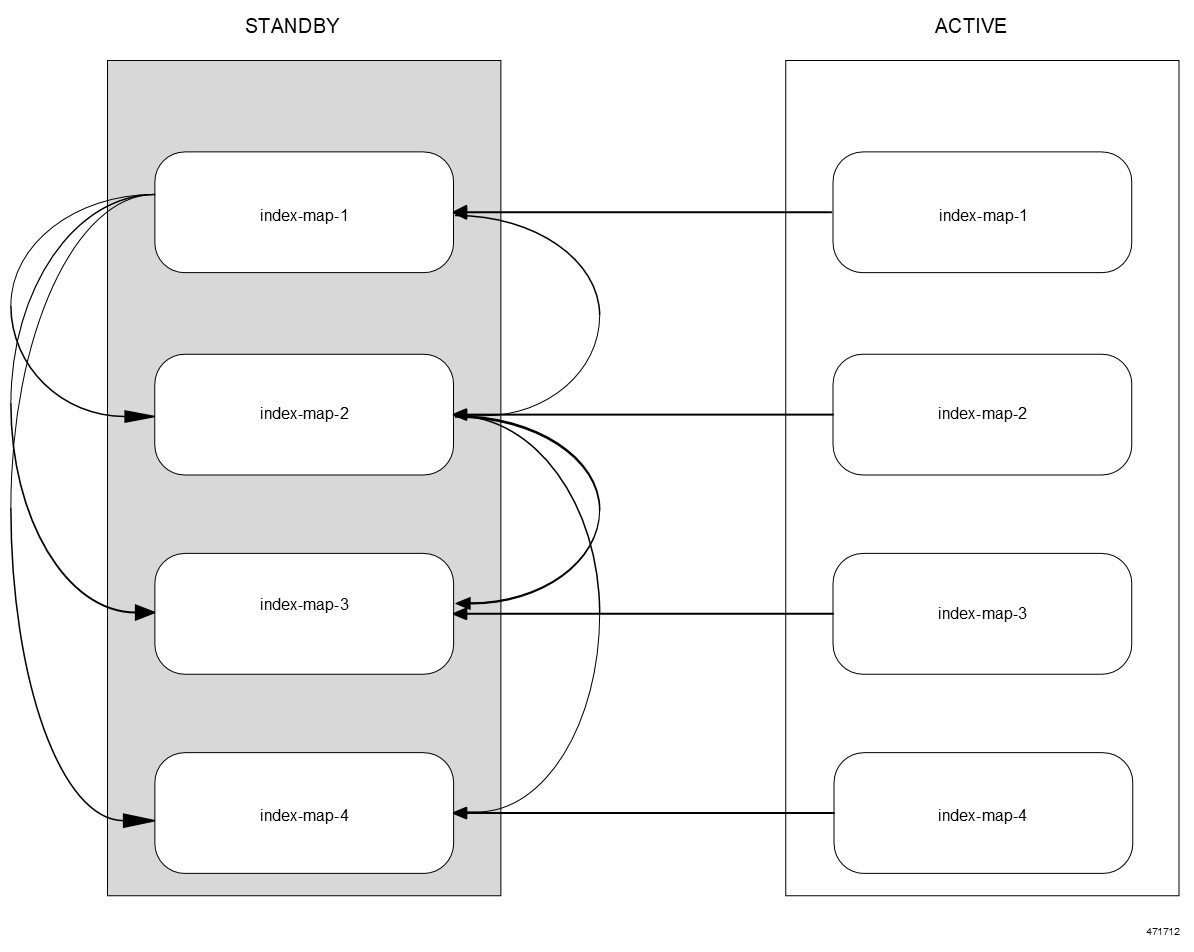
Prerequisite: The CDL must be in a healthy state at both sites. Rack-1 must be on standby and rack-2 must be on active. Both sites must
have scale-up mode configured with index prev-map-count.
Index rebalancing through the CLI on rack-1 triggers copying the index from the old calculated map (as per the old map count)
to the newly calculated map (as per the new map count). This is done after deleting index from the old calculated map once
the copying is complete.
Action: Trigger the rebalance-index run using the following command in standby site(rack1):
cdl rebalance-index run tps tps_value
Post-validation: To track the rebalancing status, use the following steps:
-
Monitor the rebalance status using the following CLI command:
cdl rebalance-index status
-
Validate the rebalance run using the following CLI command:
cdl rebalance-index validate
-
Switch the instances to Active-Active.

Prerequisite: The rebalancing must be done successfully.
Action: Enable rack-1 and rack-2 as active.
Post-validation: The traffic must land on both sites.
-
Remove the CDL scale-up mode configuration from both sites.
Prerequisite: Both rack-1 and rack-2 must be active.
Action: Configure the following command on both sites:
no cdl datastore session mode
Post-validation: CDL must be running in a healthy state. The mirror-maker restarts after scale-up mode is disabled.

















 Feedback
Feedback