- はじめに
- 概要
- CLI の使用方法
- スイッチの IP アドレスおよびデフォルト ゲートウェイの割り当て
- Cisco IOS Configuration Engine の設定
- スイッチ スタックの管理
- スイッチのクラスタ化
- スイッチの管理
- SDM テンプレートの設定
- スイッチ ベース認証の設定
- IEEE 802.1X ポートベース認証の設定
- Web ベース認証の設定
- インターフェイス特性の設定
- Auto Smartport マクロの設定
- VLAN の設定
- VTP の設定
- 音声 VLAN の設定
- プライベート VLAN の設定
- IEEE 802.1Q トンネリングおよびレイヤ 2 プロトコル トンネリングの設定
- STP の設定
- MSTP の設定
- オプションのスパニング ツリー機能の設定
- Flex Link および MAC アドレス テーブル 移動更新機能の設定
- Dynamic Host Configuration Protocol (DHCP)機能および IP ソース ガード (IPSG)機能の設定
- ダイナミック ARP インスペクションの設定
- IGMP スヌーピングおよび MVR の設定
- ポート単位のトラフィック制御の設定
- CDP の設定
- LLDP、LLDP-MED、および接続された場所 のサービスの設定
- UDLD の設定
- SPAN および RSPAN の設定
- RMON の設定
- システム メッセージ ロギングの設定
- SNMP の設定
- 組み込みイベント マネージャの設定
- ACL によるネットワーク セキュリティの設定
- QoS の設定
- EtherChannel およびリンクステート トラッ キングの設定
- IP ユニキャスト ルーティングの設定
- IPv6 ユニキャスト ルーティング の設定
- IPv6 MLD スヌーピングの設定
- IPv6 ACL の設定
- HSRP の設定
- Cisco IOS IP SLA 動作の設定
- 拡張オブジェクト トラッキングの設定
- WCCP による Web キャッシュ サービスの 設定
- IP マルチキャスト ルーティングの設定
- MSDP の設定
- フォールバック ブリッジングの設定
- トラブルシューティング
- オンライン診断の設定
- Catalyst 3750G Integrated Wireless LAN Controller スイッチの設定
- サポート対象 MIB
- Cisco IOS ファイル システム、コンフィギュ レーション ファイル、およびソフトウェア イ メージの操作
- Cisco IOS Release 12.2(52)SE でサポート されていないコマンド
- 索引
Catalyst 3750 スイッチ ソフトウェア コンフィギュレーション ガイド,12.2(52)SE
偏向のない言語
この製品のマニュアルセットは、偏向のない言語を使用するように配慮されています。このマニュアルセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザーインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブランゲージに対する取り組みの詳細は、こちらをご覧ください。
翻訳について
このドキュメントは、米国シスコ発行ドキュメントの参考和訳です。リンク情報につきましては、日本語版掲載時点で、英語版にアップデートがあり、リンク先のページが移動/変更されている場合がありますことをご了承ください。あくまでも参考和訳となりますので、正式な内容については米国サイトのドキュメントを参照ください。
- Updated:
- 2017年5月27日
章のタイトル: IP ユニキャスト ルーティングの設定
- IP ルーティングの概要
- ルーティングを設定する手順
- IP アドレス指定の設定
- IP ユニキャスト ルーティングのイネーブル化
- RIP の設定
- OSPF の設定
- EIGRP の設定
- BGP の設定
- ISO CLNS ルーティングの設定
- マルチ VRF CE の設定
- プロトコル独立機能の設定
- IP ネットワークのモニタおよびメンテナンス
IP ユニキャスト ルーティングの設定
この章では、Catalyst 3750 スイッチに Internet Protocol Version 4(IPv4)ユニキャスト ルーティングを設定する方法について説明します。特に明記しないかぎり、 スイッチ という用語はスタンドアロン スイッチおよびスイッチ スタックを意味します。スイッチ スタックは、ネットワーク内のそれ以外のルータに対して、単一のルータとして動作し、認識されます。スタティック ルーティングおよび Routing Information Protocol(RIP)などの基本的なルーティング機能は、IP ベース イメージと IP サービス イメージの両方で使用できます。先進のルーティング機能およびその他のルーティング プロトコルを使用するには、スタンドアロン スイッチやスタック マスターに IP サービス イメージをインストールする必要があります。

(注) スイッチ スタックが拡張 IP サービス イメージを実行している場合、IP バージョン 6(IPv6)ユニキャスト ルーティングもイネーブルにして IPv4 トラフィックに加えて IPv6 トラフィックを転送するようにインターフェイスを設定できます。スイッチに IPv6 を設定する手順については、「IPv6 ユニキャスト ルーティングの設定」を参照してください。
IP ユニキャスト設定情報に関する詳細については、『 Cisco IOS IP Configuration Guide 』Release 12.2 を参照してください。これには、Cisco.com のホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Configuration Guides])からアクセス可能です。このセクションで使用するコマンドの構文および使用方法の詳細については、それぞれのコマンド リファレンスを参照してください。これには、Cisco.com のホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Command References])からアクセス可能です。
•![]() 『Cisco IOS IP Command Reference, Volume 1 of 3: Addressing and Services』Release 12.2
『Cisco IOS IP Command Reference, Volume 1 of 3: Addressing and Services』Release 12.2
•![]() 『Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols』Release 12.2
『Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols』Release 12.2
•![]() 『Cisco IOS IP Command Reference, Volume 3 of 3: Multicast』Release 12.2
『Cisco IOS IP Command Reference, Volume 3 of 3: Multicast』Release 12.2
(注) スイッチにルーティング パラメータを設定する場合、使用できるユニキャスト ルート数が最大となるようにシステム リソースを割り当てるには、sdm prefer routing グローバル コンフィギュレーション コマンドを使用し、ルーティング テンプレートに Switch Database Management(SDM; スイッチ データベース管理)機能を設定します。SDM テンプレートの詳細については、「SDM テンプレートの設定」、またはこのリリースのコマンド リファレンスの sdm prefer コマンドを参照してください。
IP ルーティングの概要
一部のネットワーク環境で、VLAN(仮想 LAN)は各ネットワークまたはサブネットワークに関連付けられています。IP ネットワークで、各サブネットワークは 1 つの VLAN に対応しています。VLAN を設定すると、ブロードキャスト ドメインのサイズを制御し、ローカル トラフィックをローカル内にとどめることができます。ただし、異なる VLAN 内のネットワーク デバイスが相互に通信するには、VLAN 間でトラフィックをルーティング(VLAN 間ルーティング)するレイヤ 3 デバイス(ルータ)が必要です。VLAN 間ルーティングでは、適切な宛先 VLAN にトラフィックをルーティングするため、1 つまたは複数のルータを設定します。
図 38-1 に基本的なルーティング トポロジを示します。スイッチ A は VLAN 10 内、スイッチ B は VLAN20 内にあります。ルータには各 VLAN のインターフェイスが備わっています。

VLAN10 内のホスト A が VLAN10 内のホスト B と通信する場合、ホスト A はホスト B 宛にアドレス指定されたパケットを送信します。スイッチ A はパケットをルータに送信せず、ホスト B に直接転送します。
ホスト A から VLAN20 内のホスト C にパケットを送信する場合、スイッチ A はパケットをルータに転送し、ルータは VLAN10 インターフェイスでトラフィックを受信します。ルータはルーティング テーブルを調べて正しい発信インターフェイスを判別し、VLAN 20 インターフェイスを経由してパケットをスイッチ B に送信します。スイッチ B はパケットを受信し、ホスト C に転送します。
ルーティング タイプ
ルータおよびレイヤ 3 スイッチは、次の 3 つの方法でパケットをルーティングできます。
•![]() 事前にプログラミングされているトラフィックのスタティック ルートの使用
事前にプログラミングされているトラフィックのスタティック ルートの使用
デフォルト ルーティングとは、宛先がルータにとって不明であるトラフィックをデフォルトの出口または宛先に送信することです。
スタティック ユニキャスト ルーティングの場合、パケットは事前に設定されたポートから単一のパスを通り、ネットワークの内部または外部に転送されます。スタティック ルーティングは安全で、帯域幅をほとんど使用しません。ただし、リンク障害などのネットワークの変更には自動的に対応しないため、パケットが宛先に到達しないことがあります。ネットワークが拡大するにつれ、スタティック ルーティングの設定は煩雑になります。
ルータでは、トラフィックを転送する最適ルートを動的に計算するため、ダイナミック ルーティング プロトコルが使用されます。ダイナミック ルーティング プロトコルには次の 2 つのタイプがあります。
•![]() ディスタンス ベクタ プロトコルを使用するルータでは、ネットワーク リソースの距離の値を使用してルーティング テーブルを保持し、これらのテーブルをネイバーに定期的に渡します。ディスタンス ベクタ プロトコルは 1 つまたは複数のメトリックを使用し、最適なルートを計算します。これらのプロトコルは、簡単に設定、使用できます。
ディスタンス ベクタ プロトコルを使用するルータでは、ネットワーク リソースの距離の値を使用してルーティング テーブルを保持し、これらのテーブルをネイバーに定期的に渡します。ディスタンス ベクタ プロトコルは 1 つまたは複数のメトリックを使用し、最適なルートを計算します。これらのプロトコルは、簡単に設定、使用できます。
•![]() リンク ステート プロトコルを使用するルータでは、ルータ間の Link-State Advertisement(LSA; リンクステート アドバタイズメント)の交換に基づき、ネットワーク トポロジに関する複雑なデータベースを保持します。LSA はネットワークのイベントによって起動され、コンバージェンス時間、またはこれらの変更への対応時間を短縮します。リンクステート プロトコルはトポロジの変更にすばやく対応しますが、ディスタンス ベクタ プロトコルよりも多くの帯域幅およびリソースが必要になります。
リンク ステート プロトコルを使用するルータでは、ルータ間の Link-State Advertisement(LSA; リンクステート アドバタイズメント)の交換に基づき、ネットワーク トポロジに関する複雑なデータベースを保持します。LSA はネットワークのイベントによって起動され、コンバージェンス時間、またはこれらの変更への対応時間を短縮します。リンクステート プロトコルはトポロジの変更にすばやく対応しますが、ディスタンス ベクタ プロトコルよりも多くの帯域幅およびリソースが必要になります。
スイッチでサポートされているディスタンス ベクタ プロトコルは、RIP および Border Gateway Protocol(BGP; ボーダー ゲートウェイ プロトコル)です。RIP は最適パスを決定するために単一の距離メトリック(コスト)を使用し、BGP はパス ベクタ メカニズムを追加します。また、Open Shortest Path First(OSPF)リンクステート プロトコル、および従来の Interior Gateway Routing Protocol(IGRP)にリンクステート ルーティング機能の一部を追加して効率化を図った Enhanced IGRP(EIGRP)もサポートされています。
(注) スイッチ スタックでサポートされるプロトコルは、スタック マスター上で稼動しているソフトウェアによって決まります。スタック マスター上で IP ベース イメージが稼動している場合は、デフォルトのルーティング、スタティック ルーティング、および RIP だけがサポートされます。その他のすべてのルーティング プロトコルには、IP サービス イメージが必要です。
IP ルーティングおよびスイッチ スタック
スタック内のどのスイッチがルーティング ピアに接続されているかに関係なく、ネットワークは Catalyst 3750 スイッチ スタックを単一ルータとして認識します。スイッチ スタックの動作の詳細については、「スイッチ スタックの管理」を参照してください。
•![]() ルーティング プロトコル メッセージおよびアップデートを他のルータに送信します。
ルーティング プロトコル メッセージおよびアップデートを他のルータに送信します。
•![]() ピア ルータから受信したルーティング プロトコル メッセージおよびアップデートを処理します。
ピア ルータから受信したルーティング プロトコル メッセージおよびアップデートを処理します。
•![]() distributed Cisco Express Forwarding(dCEF)データベースを生成および維持し、すべてのスタック メンバーに配信します。このデータベースに基づいて、スタック内のすべてのスイッチにルートがプログラムされます。
distributed Cisco Express Forwarding(dCEF)データベースを生成および維持し、すべてのスタック メンバーに配信します。このデータベースに基づいて、スタック内のすべてのスイッチにルートがプログラムされます。
•![]() スタック マスターの MAC(メディア アクセス制御)アドレスはスタック全体のルータ MAC アドレスとして使用され、すべての外部デバイスはこのアドレスを使用して IP パケットをスタックに送信します。
スタック マスターの MAC(メディア アクセス制御)アドレスはスタック全体のルータ MAC アドレスとして使用され、すべての外部デバイスはこのアドレスを使用して IP パケットをスタックに送信します。
•![]() ソフトウェア転送またはソフトウェア処理を必要とするすべての IP パケットは、スタック マスターの CPU を通ります。
ソフトウェア転送またはソフトウェア処理を必要とするすべての IP パケットは、スタック マスターの CPU を通ります。
•![]() ルーティング スタンバイ スイッチとして機能します。スタック マスターに障害が発生し、新規スタック マスターとして選択された場合に、処理を引き継ぐことができます。
ルーティング スタンバイ スイッチとして機能します。スタック マスターに障害が発生し、新規スタック マスターとして選択された場合に、処理を引き継ぐことができます。
•![]() ルートをハードウェアにプログラムします。スタック メンバーによってプログラムされたルートは、dCEF データベースの一部としてスタック マスターがダウンロードしたルートと同じです。
ルートをハードウェアにプログラムします。スタック メンバーによってプログラムされたルートは、dCEF データベースの一部としてスタック マスターがダウンロードしたルートと同じです。
スタック マスターに障害が発生すると、スタックはスタック マスターがダウンしていることを検出し、スタック メンバーの 1 つを新規スタック マスターとして選択します。この期間中に、ハードウェアは一時的な中断を除き、アクティブなプロトコルがない状態で、パケットの転送を継続します。
ただし、スイッチ スタックで障害発生後にハードウェア ID を保持していても、スタック マスターがリスタートする前の短時間の中断中に、ルータ ネイバーのルーティング プロトコルがフラップすることもあります。OSPF や EIGRP などのルーティング プロトコルは、ネイバー トランジションを認識する必要があります。ルータでは、2 つのレベルの Nonstop Forwarding(NSF)を使用してスイッチオーバーを検出し、ネットワーク トラフィックの転送を継続し、ピア デバイスからのルート情報を回復しています。
•![]() NSF 認識ルータは、近接ルータの障害を許容しています。近接ルータが再起動したあとに、NSF 認識ルータが要求に応じてステートとルートの隣接関係に関する情報を提供します。
NSF 認識ルータは、近接ルータの障害を許容しています。近接ルータが再起動したあとに、NSF 認識ルータが要求に応じてステートとルートの隣接関係に関する情報を提供します。
•![]() NSF 対応ルータは NSF をサポートします。スタック マスターの変更を検出すると、NSF 認識ネイバーまたは NSF 対応ネイバーからルーティング情報を再構築し、再起動まで待機しません。
NSF 対応ルータは NSF をサポートします。スタック マスターの変更を検出すると、NSF 認識ネイバーまたは NSF 対応ネイバーからルーティング情報を再構築し、再起動まで待機しません。
スイッチ スタックは OSPF および EIGRP の NSF 対応ルーティングをサポートしています。詳細については、「OSPF NSF 機能」および「EIGRP NSF 機能」を参照してください。
新規スタック マスターは、選択されたときに次の機能を実行します。
•![]() ルーティング アップデートの生成、受信、および処理を開始します。
ルーティング アップデートの生成、受信、および処理を開始します。
•![]() ルーティング テーブルを構築し、CEF データベースを生成して、スタック メンバーに配信します。
ルーティング テーブルを構築し、CEF データベースを生成して、スタック メンバーに配信します。
•![]() ルータ MAC アドレスとして自身の MAC アドレスを使用します。新規 MAC アドレスのネットワーク ピアを通知するために、新規ルータ MAC アドレスを使用して Gratuitous Address Resolution Protocol(ARP)応答を定期的に(5 分間、数秒おきに)送信します。
ルータ MAC アドレスとして自身の MAC アドレスを使用します。新規 MAC アドレスのネットワーク ピアを通知するために、新規ルータ MAC アドレスを使用して Gratuitous Address Resolution Protocol(ARP)応答を定期的に(5 分間、数秒おきに)送信します。
(注) 固定 MAC アドレス機能をスタックに設定してスタック マスターを変更した場合、スタック MAC アドレスは設定された期間変更されません。この期間に前のスタック マスターがメンバー スイッチとしてスタックに復帰する場合、スタック MAC アドレスは前のスタック マスターの MAC アドレスのままになります。「固定 MAC アドレスのイネーブル化」を参照してください。
•![]() ARP 要求をプロキシ ARP IP アドレスに送信し、ARP 応答を受信して、各プロキシ ARP エントリの到達可能性を判別しようとします。到達可能なプロキシ ARP IP アドレスごとに、新規ルータ MAC アドレスを使用して Gratuitous ARP 応答を生成します。このプロセスは、新規スタック マスターが選択されたあと、5 分間繰り返されます。
ARP 要求をプロキシ ARP IP アドレスに送信し、ARP 応答を受信して、各プロキシ ARP エントリの到達可能性を判別しようとします。到達可能なプロキシ ARP IP アドレスごとに、新規ルータ MAC アドレスを使用して Gratuitous ARP 応答を生成します。このプロセスは、新規スタック マスターが選択されたあと、5 分間繰り返されます。
(注) スタック マスターで IP サービス イメージが稼動中の場合、スタックは OSPF、EIGRP、BGP などのすべてのサポートするプロトコルを実行することができます。スタック マスターに障害が発生し、新規に選択されたスタック マスター上で IP ベース イメージが稼動している場合、これらのプロトコルはスタック内で稼動しなくなります。

ルーティングを設定する手順
スイッチ上で、IP ルーティングはデフォルトでディセーブルとなっています。ルーティングを行う前に、IP ルーティングをイネーブルにする必要があります。IP ルーティング設定情報に関する詳細については、『 Cisco IOS IP Configuration Guide 』Release 12.2 を参照してください。これには、Cisco.com のホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Configuration Guides])からアクセス可能です。
次の手順では、次に示すレイヤ 3 インターフェイスの 1 つを指定する必要があります。
•![]() ルーテッド ポート: no switchport インターフェイス コンフィギュレーション コマンドを使用し、レイヤ 3 ポートとして設定された物理ポートです。
ルーテッド ポート: no switchport インターフェイス コンフィギュレーション コマンドを使用し、レイヤ 3 ポートとして設定された物理ポートです。
•![]() Switch Virtual Interface(SVI; スイッチ仮想インターフェイス): interface vlan vlan_id グローバル コンフィギュレーション コマンドによって作成された VLAN インターフェイス。デフォルトではレイヤ 3 インターフェイスです。
Switch Virtual Interface(SVI; スイッチ仮想インターフェイス): interface vlan vlan_id グローバル コンフィギュレーション コマンドによって作成された VLAN インターフェイス。デフォルトではレイヤ 3 インターフェイスです。
•![]() レイヤ 3 モードの EtherChannel ポート チャネル: interface port-channel port- channel-number グローバル コンフィギュレーション コマンドを使用し、イーサネット インターフェイスをチャネル グループにバインドして作成されたポートチャネル論理インターフェイスです。詳細については、「レイヤ 3 EtherChannel の設定」を参照してください。
レイヤ 3 モードの EtherChannel ポート チャネル: interface port-channel port- channel-number グローバル コンフィギュレーション コマンドを使用し、イーサネット インターフェイスをチャネル グループにバインドして作成されたポートチャネル論理インターフェイスです。詳細については、「レイヤ 3 EtherChannel の設定」を参照してください。
(注) スイッチは、ユニキャスト ルーテッド トラフィックのトンネル インターフェイスをサポートしません。
ルーティングが発生するすべてのレイヤ 3 インターフェイスに、IP アドレスを割り当てる必要があります。「ネットワーク インターフェイスへの IP アドレスの割り当て」を参照してください。
(注) レイヤ 3 スイッチでは、ルーテッド ポートおよび SVI ごとに IP アドレスを 1 つ割り当てることができます。ソフトウェアに、設定できるルーテッド ポートおよび SVI の個数制限はありません。ただし、ハードウェアによって制限されるため、設定できるルーテッド ポートおよび SVI の個数と、実装されている機能の組み合わせによっては、CPU 利用率が影響を受けることがあります。システム メモリをルーティング用に最適化するには、sdm prefer routing グローバル コンフィギュレーション コマンドを使用します。
•![]() VLAN インターフェイスをサポートするために、スイッチ スタックで VLAN を作成および設定し、レイヤ 2 インターフェイスに VLAN メンバシップを割り当てます。詳細は、「VLAN の設定」を参照してください。
VLAN インターフェイスをサポートするために、スイッチ スタックで VLAN を作成および設定し、レイヤ 2 インターフェイスに VLAN メンバシップを割り当てます。詳細は、「VLAN の設定」を参照してください。
•![]() レイヤ 3 インターフェイスに IP アドレスを割り当てます。
レイヤ 3 インターフェイスに IP アドレスを割り当てます。
IP アドレス指定の設定
IP ルーティングを設定するには、レイヤ 3 ネットワーク インターフェイスに IP アドレスを割り当ててインターフェイスをイネーブルにし、IP を使用するインターフェイスを経由してホストとの通信を許可する必要があります。ここでは、さまざまな IP アドレス機能の設定方法について説明します。IP アドレスをインターフェイスに割り当てる手順は必須ですが、その他の手順は任意です。
•![]() 「ネットワーク インターフェイスへの IP アドレスの割り当て」
「ネットワーク インターフェイスへの IP アドレスの割り当て」
•![]() 「IP ルーティングがディセーブルの場合のルーティング支援機能」
「IP ルーティングがディセーブルの場合のルーティング支援機能」
アドレス指定のデフォルト設定
表 38-1 に、アドレス指定のデフォルト設定を示します。
|
|
|
|---|---|
Address Resolution Protocol(ARP; アドレス解決プロトコル)キャッシュに永続的なエントリはありません。 |
|
ヘルパー アドレスが定義されているか、または UDP フラッディングが設定されている場合、デフォルト ポートでは UDP 転送がイネーブルとなります。 |
|
ネットワーク インターフェイスへの IP アドレスの割り当て
IP アドレスは IP パケットの送信先を特定します。一部の IP アドレスは特殊な目的のために予約されていて、ホスト、サブネット、またはネットワーク アドレスには使用できません。RFC 1166「Internet Numbers」には IP アドレスに関する公式の説明が記載されています。
インターフェイスには、1 つのプライマリ IP アドレスを設定できます。マスクは、IP アドレスのネットワーク番号を表すビットを特定します。マスクを使用してネットワークをサブネット化する場合、そのマスクをサブネット マスクと呼びます。割り当てられているネットワーク番号については、インターネット サービス プロバイダーにお問い合わせください。
IP アドレスおよびネットワーク マスクをレイヤ 3 インターフェイスに割り当てるには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
show interfaces [ interface-id ] |
||
サブネット ゼロの使用
サブネット アドレスがゼロであるサブネットを作成しないでください。同じアドレスを持つネットワークおよびサブネットがある場合に問題が発生することがあります。たとえば、ネットワーク 131.108.0.0 のサブネットが 255.255.255.0 の場合、サブネット ゼロは 131.108.0.0 と記述され、ネットワーク アドレスと同じとなってしまいます。
すべてが 1 のサブネット(131.108.255.0)は使用可能です。また、IP アドレス用にサブネット スペース全体が必要な場合は、サブネット ゼロの使用をイネーブルにできます(ただし推奨できません)。
サブネット ゼロをイネーブルにするには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
デフォルトに戻して、サブネット ゼロの使用をディセーブルにするには、 no ip subnet-zero グローバル コンフィギュレーション コマンドを使用します。
クラスレス ルーティング
ルーティングを行うように設定されたスイッチで、クラスレス ルーティング動作はデフォルトでイネーブルとなっています。クラスレス ルーティングがイネーブルの場合、デフォルト ルートがないネットワークのサブネット宛パケットをルータが受信すると、ルータは最適なスーパーネット ルートにパケットを転送します。 スーパーネット は、単一の大規模アドレス スペースをシミュレーションするために使用されるクラス C アドレス スペースの連続ブロックで構成されています。スーパーネットは、クラス B アドレス スペースの急速な枯渇を回避するために設計されました。
図 38-2 では、クラスレス ルーティングがイネーブルになっています。ホストがパケットを 128.20.4.1 に送信すると、ルータはパケットを廃棄せずに、最適なスーパーネット ルートに転送します。クラスレス ルーティングがディセーブルの場合、デフォルト ルートがないネットワークのサブネット宛パケットを受信したルータは、パケットを廃棄します。
図 38-2 IP クラスレス ルーティングがイネーブルの場合

図 38-3 では、ネットワーク 128.20.0.0 のルータはサブネット 128.20.1.0、128.20.2.0、128.20.3.0 に接続されています。ホストがパケットを 128.20.4.1 に送信した場合、ネットワークのデフォルト ルートが存在しないため、ルータはパケットを廃棄します。
図 38-3 IP クラスレス ルーティングがディセーブルの場合

認識されないサブネット宛のパケットが最適なスーパーネット ルートに転送されないようにするには、クラスレス ルーティング動作をディセーブルにします。
クラスレス ルーティングをディセーブルにするには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
デフォルトに戻して、デフォルト ルートがないネットワークのサブネット宛パケットが最適なスーパーネット ルートに転送されるようにするには、 ip classless グローバル コンフィギュレーション コマンドを使用します。
アドレス解決方法の設定
インターフェイス固有の IP 処理方法を制御するには、アドレス解決を行います。IP を使用するデバイスには、ローカル セグメントまたは LAN 上のデバイスを一意に定義するローカル アドレスまたは MAC(メディア アクセス制御)アドレスと、デバイスが属するネットワークを特定するネットワーク アドレスがあります。
(注) Catalyst 3750 スイッチ スタックでは、スタックの単一の MAC アドレスおよび IP アドレスを使用して、ネットワーク通信を行います。
ローカルアドレス(MAC アドレス)は、パケット ヘッダーのデータ リンク層(レイヤ 2)セクションに格納されて、データ リンク(レイヤ 2)デバイスによって読み取られるため、データ リンク アドレスと呼ばれます。ソフトウェアがイーサネット上のデバイスと通信するには、デバイスの MAC アドレスを学習する必要があります。IP アドレスから MAC アドレスを学習するプロセスを、 アドレス解決 と呼びます。MAC アドレスから IP アドレスを学習するプロセスを、 逆アドレス解決 と呼びます。
•![]() ARP:IP アドレスを MAC アドレスと関連付けるために使用されます。ARP は IP アドレスを入力と解釈し、対応する MAC アドレスを学習します。次に、IP アドレス/MAC アドレスの関連を ARP キャッシュに格納し、すぐに取り出せるようにします。そのあと、IP データグラムがリンク レイヤ フレームにカプセル化され、ネットワークを通じて送信されます。イーサネット以外の IEEE 802 ネットワークにおける IP データグラムのカプセル化、および ARP 要求や応答については、Subnetwork Access Protocol(SNAP)で規定されています。
ARP:IP アドレスを MAC アドレスと関連付けるために使用されます。ARP は IP アドレスを入力と解釈し、対応する MAC アドレスを学習します。次に、IP アドレス/MAC アドレスの関連を ARP キャッシュに格納し、すぐに取り出せるようにします。そのあと、IP データグラムがリンク レイヤ フレームにカプセル化され、ネットワークを通じて送信されます。イーサネット以外の IEEE 802 ネットワークにおける IP データグラムのカプセル化、および ARP 要求や応答については、Subnetwork Access Protocol(SNAP)で規定されています。
•![]() プロキシ ARP:ルーティング テーブルを持たないホストで、他のネットワークまたはサブネット上のホストの MAC アドレスを学習できるようにします。スイッチ(ルータ)が送信元と異なるインターフェイス上のホストに宛てた ARP 要求を受信した場合、そのルータに他のインターフェイスを経由してそのホストに至るすべてのルートが格納されていれば、ルータは自身のローカル データ リンク アドレスを示すプロキシ ARP パケットを生成します。ARP 要求を送信したホストはルータにパケットを送信し、ルータはパケットを目的のホストに転送します。
プロキシ ARP:ルーティング テーブルを持たないホストで、他のネットワークまたはサブネット上のホストの MAC アドレスを学習できるようにします。スイッチ(ルータ)が送信元と異なるインターフェイス上のホストに宛てた ARP 要求を受信した場合、そのルータに他のインターフェイスを経由してそのホストに至るすべてのルートが格納されていれば、ルータは自身のローカル データ リンク アドレスを示すプロキシ ARP パケットを生成します。ARP 要求を送信したホストはルータにパケットを送信し、ルータはパケットを目的のホストに転送します。
スイッチでは、ARP と同様の機能(RARP パケットがローカル MAC アドレスでなく IP アドレスを要求する点を除く)を持つ Reverse Address Resolution Protocol(RARP; 逆アドレス解決プロトコル)を使用することもできます。RARP を使用するには、ルータ インターフェイスと同じネットワーク セグメント上に RARP サーバを設置する必要があります。サーバを識別するには、 ip rarp-server address インターフェイス コンフィギュレーション コマンドを使用します。
RARP に関する詳細については、『 Cisco IOS Configuration Fundamentals Configuration Guide 』Release 12.2 を参照してください。これには、Cisco.com のホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Configuration Guides])からアクセス可能です。
スタティック ARP キャッシュの定義
ARP および他のアドレス解決プロトコルを使用すると、IP アドレスと MAC アドレス間を動的にマッピングできます。ほとんどのホストでは動的なアドレス解決がサポートされているため、通常の場合、スタティック ARP キャッシュ エントリを指定する必要はありません。スタティック ARP キャッシュ エントリを定義する必要がある場合は、グローバルに定義できます。グローバルに定義すると、IP アドレスを MAC アドレスに変換するために使用される永続的なエントリを、ARP キャッシュに確保できます。また、指定された IP アドレスがスイッチに属する場合と同じ方法で、スイッチが ARP 要求に応答するように指定することもできます。ARP エントリを永続的なエントリにしない場合は、ARP エントリのタイムアウト期間を指定できます。
IP アドレスと MAC アドレスの間でスタティック マッピングを行うには、特権 EXEC モードで次の手順を実行します。
ARP キャッシュからエントリを削除するには、 no arp ip-address hardware-address type グローバル コンフィギュレーション コマンドを使用します。ARP キャッシュから非スタティック エントリをすべて削除するには、 clear arp-cache 特権 EXEC コマンドを使用します 。
ARP カプセル化の設定
IP インターフェイスでは、イーサネット ARP 形式の ARP カプセル化( arpa キーワードで表される)がデフォルトでイネーブルに設定されています。ネットワークの必要性に応じて、カプセル化方法を SNAP に変更できます。
ARP カプセル化タイプを指定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
カプセル化タイプをディセーブルにするには、 no arp arpa または no arp snap インターフェイス コンフィギュレーション コマンドを使用します。
プロキシ ARP のイネーブル化
デフォルトでは、プロキシ ARP が使用されます。ホストが他のネットワークまたはサブネット上のホストの MAC アドレスを学習できるようにするためです。
ディセーブルになっているプロキシ ARP をイネーブルにするには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
インターフェイスでプロキシ ARP をディセーブルにするには、 no ip proxy-arp インターフェイス コンフィギュレーション コマンドを使用します。
IP ルーティングがディセーブルの場合のルーティング支援機能
次のメカニズムを使用することで、スイッチは IP ルーティングがイネーブルでない場合、別のネットワークへのルートを取得できます。
プロキシ ARP
プロキシ ARP は、他のルートを取得する場合の最も一般的な方法です。プロキシ ARP を使用すると、ルーティング情報を持たないイーサネット ホストと、他のネットワークまたはサブネット上のホストとの通信が可能になります。このホストでは、すべてのホストが同じローカル イーサネット上にあり、ARP を使用して MAC アドレスを学習すると想定されています。送信元と異なるネットワーク上にあるホストに宛てた ARP 要求を受信したスイッチは、そのホストへの最適なルートがあるかどうかを調べます。最適ルートがある場合、スイッチはスイッチ自身のイーサネット MAC アドレスが格納された ARP 応答パケットを送信します。要求の送信元ホストはパケットをスイッチに送信し、スイッチは目的のホストにパケットを転送します。プロキシ ARP は、すべてのネットワークをローカルな場合と同様に処理し、IP アドレスごとに ARP 処理を実行します。
プロキシ ARP は、デフォルトでイネーブルに設定されています。ディセーブル化されたプロキシ ARP をイネーブルにするには、「プロキシ ARP のイネーブル化」を参照してください。プロキシ ARP は、他のルータでサポートされている限り有効です。
デフォルト ゲートウェイ
ルートを特定するもう 1 つの方法は、デフォルト ルータ、つまりデフォルト ゲートウェイを定義する方法です。ローカルでないすべてのパケットはこのルータに送信されます。このルータは適切なルーティングを行う、または IP Control Message Protocol(ICMP)リダイレクト メッセージを返信するという方法で、ホストが使用するローカル ルータを定義します。スイッチはリダイレクト メッセージをキャッシュに格納し、各パケットをできるだけ効率的に転送します。この方法には、デフォルト ルータがダウンした場合、または使用できなくなった場合に、検出が不可能となる制限があります。
IP ルーティングがディセーブルの場合にデフォルト ゲートウェイ(ルータ)を定義するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
この機能をディセーブルにするには、 no ip default-gateway グローバル コンフィギュレーション コマンドを使用します。
ICMP Router Discovery Protocol(IRDP)
ルータ ディスカバリを使用すると、スイッチは IRDP を使用し、他のネットワークへのルートを動的に取得します。ホストは IRDP を使用し、ルータを特定します。クライアントとして動作しているスイッチは、ルータ ディスカバリ パケットを生成します。ホストとして動作しているスイッチは、ルータ ディスカバリ パケットを受信します。スイッチは Routing Information Protocol(RIP)ルーティングの更新を受信し、この情報からルータの場所を推測することもできます。実際のところ、ルーティング デバイスによって送信されたルーティング テーブルは、スイッチに格納されません。どのシステムがデータを送信しているのかが記録されるだけです。IRDP を使用する利点は、プライオリティと、パケットが受信されなくなってからデバイスがダウンしていると見なされるまでの期間をルータごとに両方指定できることです。
検出された各デバイスは、デフォルト ルータの候補となります。現在のデフォルト ルータがダウンしたと宣言された場合、または再送信が多すぎて TCP 接続がタイムアウトになりつつある場合、プライオリティが上位のルータが検出されると、最も高いプライオリティを持つ新しいルータが選択されます。
インターフェイスで IRDP ルーティングを行う場合は、インターフェイスで IRDP 処理をイネーブルにしてください。IRDP 処理をイネーブルにすると、デフォルトのパラメータが適用されます。これらのパラメータを変更することもできます。
インターフェイス上で IRDP をイネーブルにして設定するには、特権 EXEC モードで次の手順を実行します。
maxadvertinterval 値を変更すると、 holdtime 値および minadvertinterval 値も変更されます。最初に maxadvertinterval 値を変更し、次に holdtime 値または minadvertinterval 値のいずれかを手動で変更することが重要です。
IRDP ルーティングをディセーブルにするには、 no ip irdp インターフェイス コンフィギュレーション コマンドを使用します。
ブロードキャスト パケットの処理方法の設定
IP インターフェイス アドレスを設定したあとで、ルーティングをイネーブルにしたり、1 つまたは複数のルーティング プロトコルを設定したり、ネットワーク ブロードキャストへのスイッチの応答方法を設定したりできます。ブロードキャストは、物理ネットワーク上のすべてのホスト宛のデータ パケットです。2 種類のブロードキャストがサポートされています。
•![]() 指定ブロードキャスト パケット:特定のネットワークまたは一連のネットワークに送信されます。指定ブロードキャスト アドレスには、ネットワークまたはサブネット フィールドが含まれます。
指定ブロードキャスト パケット:特定のネットワークまたは一連のネットワークに送信されます。指定ブロードキャスト アドレスには、ネットワークまたはサブネット フィールドが含まれます。
•![]() フラッディング ブロードキャスト パケット:すべてのネットワークに送信されます。
フラッディング ブロードキャスト パケット:すべてのネットワークに送信されます。
(注) storm-control インターフェイス コンフィギュレーション コマンドを使用して、トラフィック抑制レベルを設定し、レイヤ 2 インターフェイスでブロードキャスト、ユニキャスト、マルチキャスト トラフィックを制限することもできます。詳細は、「ポート単位のトラフィック制御の設定」を参照してください。
ルータはローカル ケーブル長を制限して、ブロードキャスト ストームを防ぎます。ブリッジ(インテリジェントなブリッジを含む)はレイヤ 2 デバイスであるため、ブロードキャストはすべてのネットワーク セグメントに転送され、ブロードキャスト ストームが伝播します。ブロードキャスト ストーム問題を解決する最善の方法は、ネットワーク上で単一のブロードキャスト アドレス方式を使用することです。最新の IP 実装機能ではほとんどの場合、アドレスをブロードキャスト アドレスとして使用するように設定できます。スイッチをはじめ、多数の実装機能では、ブロードキャスト メッセージを転送するためのアドレス方式が複数サポートされています。
これらの方式をイネーブルにするには、次に示す作業を実行します。
•![]() 「指定ブロードキャストから物理ブロードキャストへの変換のイネーブル化」
「指定ブロードキャストから物理ブロードキャストへの変換のイネーブル化」
指定ブロードキャストから物理ブロードキャストへの変換のイネーブル化
デフォルトでは、IP 指定ブロードキャストが廃棄されるため、転送されることはありません。IP 指定ブロードキャストが廃棄されると、ルータが DoS 攻撃にさらされる危険が少なくなります。
ブロードキャストが物理(MAC レイヤ)ブロードキャストになるインターフェイスでは、IP 指定ブロードキャストの転送をイネーブルにできます。 ip forward-protocol グローバル コンフィギュレーション コマンドを使用し、設定されたプロトコルだけを転送できます。
転送するブロードキャストを制御するアクセス リストを指定できます。アクセス リストを指定すると、アクセス リストで許可されている IP パケットだけが、指定ブロードキャストから物理ブロードキャストに変換できるようになります。アクセス リストの詳細については、「ACL によるネットワーク セキュリティの設定」を参照してください。
インターフェイス上で IP 指定ブロードキャストの転送をイネーブルにするには、特権 EXEC モードで次の手順を実行します。
指定ブロードキャストから物理ブロードキャストへの変換をディセーブルにするには、 no ip directed-broadcast インターフェイス コンフィギュレーション コマンドを使用します。プロトコルまたはポートを削除するには、 no ip forward-protocol グローバル コンフィギュレーション コマンドを使用します。
UDP ブロードキャスト パケットおよびプロトコルの転送
UDP は IP のホスト間レイヤ プロトコルで、TCP と同様です。UDP はオーバーヘッドが少ない、コネクションレスのセッションを 2 つのエンド システム間に提供しますが、受信されたデータグラムの確認応答は行いません。場合に応じてネットワーク ホストは UDP ブロードキャストを使用し、アドレス、コンフィギュレーション、名前に関する情報を検索します。このようなホストが、サーバを含まないネットワーク セグメント上にある場合、通常 UDP ブロードキャストは転送されません。この状況を改善するには、特定のクラスのブロードキャストをヘルパー アドレスに転送するように、ルータのインターフェイスを設定します。インターフェイスごとに、複数のヘルパー アドレスを使用できます。
UDP 宛先ポートを指定し、転送される UDP サービスを制御できます。複数の UDP プロトコルを指定することもできます。旧式のディスクレス Sun ワークステーションおよびネットワーク セキュリティ プロトコル SDNS で使用される Network Disk(ND)プロトコルも指定できます。
ヘルパー アドレスがインターフェイスに定義されている場合、デフォルトでは UDP と ND の両方の転送がイネーブルになっています。 『Cisco IOS IP Command Reference, Volume 1 of 3: Addressing and Services』Release 12.2 の ip forward-protocol インターフェイス コンフィギュレーション コマンドの説明には、UDP ポートを指定しない場合にデフォルトで転送されるポートがリストされています。
UDP ブロードキャストの転送を設定するときに UDP ポートを指定しないと、ルータは BOOTP 転送エージェントとして動作するように設定されます。BOOTP パケットは Dynamic Host Configuration Protocol(DHCP)情報を伝達します。
インターフェイスで UDP ブロードキャスト パケットの転送をイネーブルにし、宛先アドレスを指定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
特定アドレスへのブロードキャスト パケットの転送をディセーブルにするには、 no ip helper-address インターフェイス コンフィギュレーション コマンドを使用します。プロトコルまたはポートを削除するには、 no ip forward-protocol グローバル コンフィギュレーション コマンドを使用します。
IP ブロードキャスト アドレスの確立
最も一般的な(デフォルトの)IP ブロードキャスト アドレスは、すべて 1 で構成されているアドレスです(255.255.255.255)。ただし、任意の形式の IP ブロードキャスト アドレスを生成するようにスイッチを設定することもできます。
インターフェイス上で IP ブロードキャスト アドレスを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
デフォルトの IP ブロードキャスト アドレスに戻すには、 no ip broadcast-address インターフェイス コンフィギュレーション コマンドを使用します。
IP ブロードキャストのフラッディング
IP ブロードキャストをインターネットワーク全体に、制御可能な方法でフラッディングできるようにするには、ブリッジング STP で作成されたデータベースを使用します。この機能を使用すると、ループを回避することもできます。この機能を使用できるようにするには、フラッディングが行われるインターフェイスごとにブリッジングを設定する必要があります。ブリッジングが設定されていないインターフェイス上でも、ブロードキャストを受信できます。ただし、ブリッジングが設定されていないインターフェイスでは、受信したブロードキャストが転送されません。また、異なるインターフェイスで受信されたブロードキャストを送信する場合、このインターフェイスは使用されません。
IP ヘルパー アドレスのメカニズムを使用して単一のネットワーク アドレスに転送されるパケットを、フラッディングできます。各ネットワーク セグメントには、パケットのコピーが 1 つだけ送信されます。
フラッディングを行う場合、パケットは次の条件を満たす必要があります(これらの条件は、IP ヘルパー アドレスを使用してパケットを転送するときの条件と同じです)。
•![]() パケットは MAC レベルのブロードキャストでなければなりません。
パケットは MAC レベルのブロードキャストでなければなりません。
•![]() パケットは IP レベルのブロードキャストでなければなりません。
パケットは IP レベルのブロードキャストでなければなりません。
•![]() パケットは Trivial File Transfer Protocol(TFTP; 簡易ファイル転送プロトコル)、Domain Name System(DNS; ドメイン ネーム システム)、Time、NetBIOS、ND、または BOOTP パケット、または ip forward-protocol udp グローバル コンフィギュレーション コマンドで指定された UDP でなければなりません。
パケットは Trivial File Transfer Protocol(TFTP; 簡易ファイル転送プロトコル)、Domain Name System(DNS; ドメイン ネーム システム)、Time、NetBIOS、ND、または BOOTP パケット、または ip forward-protocol udp グローバル コンフィギュレーション コマンドで指定された UDP でなければなりません。
•![]() パケットの Time To Live(TTL)値は 2 以上でなければなりません。
パケットの Time To Live(TTL)値は 2 以上でなければなりません。
フラッディングされた UDP データグラムには、出力インターフェイスで ip broadcast-address インターフェイス コンフィギュレーション コマンドによって指定された宛先アドレスを設定します。宛先アドレスを、任意のアドレスに設定できます。このため、データグラムがネットワーク内を伝播するにつれ、宛先アドレスが変更されることもあります。送信元アドレスは変更されません。TTL 値が減ります。
フラッディングされた UDP データグラムがインターフェイスから送信されると(場合によっては宛先アドレスが変更される)、データグラムは通常の IP 出力ルーチンに渡されます。このため、出力インターフェイスにアクセス リストがある場合、データグラムはその影響を受けます。
ブリッジング スパニング ツリー データベースを使用し、UDP データグラムをフラッディングするには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
IP ブロードキャストのフラッディングをディセーブルにするには、 no ip forward-protocol spanning-tree グローバル コンフィギュレーション コマンドを使用します。
スイッチでは、パケットの大部分がハードウェアで転送され、スイッチの CPU を経由しません。CPU に送信されるパケットの場合は、ターボフラッディングを使用し、スパニング ツリーベースの UDP フラッディングを約 4 ~ 5 倍高速化します。この機能は、ARP カプセル化用に設定されたイーサネット インターフェイスでサポートされています。
スパニング ツリーベースのフラッディングを向上させるには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
この機能をディセーブルにするには、 no ip forward-protocol turbo-flood グローバル コンフィギュレーション コマンドを使用します。
IP アドレスのモニタおよびメンテナンス
特定のキャッシュ、テーブル、またはデータベースの内容が無効になった場合、または無効である可能性がある場合は、 clear 特権 EXEC コマンドを使用し、すべての内容を消去できます。 表 38-2 に、内容を消去するために使用するコマンドを示します。
|
|
|
|---|---|
IP ルーティング テーブル、キャッシュ、データベースの内容、ノードへの到達可能性、ネットワーク内のパケットのルーティング パスなど、特定の統計情報を表示できます。 表 38-3 に、IP 統計情報を表示するために使用する特権 EXEC コマンドを示します。
|
|
|
|---|---|
デフォルトのドメイン名、検索サービスの方式、サーバ ホスト名、およびキャッシュに格納されているホスト名とアドレスのリストを表示します。 |
|
IP ユニキャスト ルーティングのイネーブル化
デフォルトで、スイッチはレイヤ 2 スイッチング モード、IP ルーティングはディセーブルとなっています。スイッチのレイヤ 3 機能を使用するには、IP ルーティングをイネーブルにする必要があります。
IP ルーティングをイネーブルにするには、特権 EXEC モードで次の手順を実行します。
ルーティングをディセーブルにするには、 no ip routing グローバル コンフィギュレーション コマンドを使用します。
次に、ルーティング プロトコルとして RIP を使用し、IP ルーティングをイネーブルにする例を示します。
ここで、選択したルーティング プロトコルのパラメータを設定できます。具体的な手順は次のとおりです。
•![]() 「プロトコル独立機能の設定」(任意)
「プロトコル独立機能の設定」(任意)
RIP の設定
RIP は、小規模な同種ネットワーク間で使用するために作成された Interior Gateway Protocol(IGP; 内部ゲートウェイ プロトコル)です。RIP は、ブロードキャスト UDP データ パケットを使用してルーティング情報を交換するディスタンス ベクタ ルーティング プロトコルです。このプロトコルは RFC 1058 に文書化されています。RIP の詳細については、『 IP Routing Fundamentals 』(Cisco Press 刊)を参照してください。
(注) RIP は IP ベース イメージでサポートされている唯一のルーティング プロトコルです。その他のルーティング プロトコルを使用する場合は、スタック マスター上で IP サービス イメージを稼動させる必要があります。
スイッチは RIP を使用し、30 秒ごとにルーティング情報アップデート(アドバタイズメント)を送信します。180 秒以上を経過しても別のルータからアップデートがルータに届かない場合、該当するルータから送られたルートは使用不能としてマークされます。240 秒が経過してもアップデートが届かない場合、アップデートを行わないルータに関するすべてのルーティング テーブル エントリは削除されます。
RIP では、各ルートの値を評価するためにホップ カウントが使用されます。ホップ カウントは、ルート内で経由されるルータ数です。直接接続されているネットワークのホップ カウントは 0 です。ホップ カウントが 16 のネットワークに到達することはできません。このように範囲(0 ~ 15)が狭いため、RIP は大規模ネットワークには適していません。
ルータにデフォルトのネットワーク パスが設定されている場合、RIP はルータを疑似ネットワーク 0.0.0.0 にリンクするルートをアドバタイズします。0.0.0.0 ネットワークは存在しません。RIP はデフォルトのルーティング機能を実行するためのネットワークとして、このネットワークを処理します。デフォルト ネットワークが RIP によって取得された場合、またはルータが最終ゲートウェイで、RIP がデフォルト メトリックによって設定されている場合、スイッチはデフォルト ネットワークをアドバタイズします。RIP は指定されたネットワーク内のインターフェイスにアップデートを送信します。インターフェイスのネットワークを指定しないと、RIP アップデート中にアドバタイズされません。
•![]() 「サマリー アドレスおよびスプリット ホライズンの設定」
「サマリー アドレスおよびスプリット ホライズンの設定」
RIP のデフォルト設定
表 38-4 に、RIP のデフォルト設定を示します。
|
|
|
|---|---|
基本的な RIP パラメータの設定
RIP を設定するには、ネットワークに対して RIP ルーティングをイネーブルにします。他のパラメータを設定することもできます。Catalyst 3750 スイッチでは、ネットワーク番号を設定するまで RIP コンフィギュレーション コマンドは無視されます。
RIP をイネーブルにして設定するには、特権 EXEC モードで次の手順を実行します。
RIP ルーティング プロセスをオフにするには、 no router rip グローバル コンフィギュレーション コマンドを使用します。
アクティブなルーティング プロトコル プロセスのパラメータと現在のステートを表示するには、 show ip protocols 特権 EXEC コマンドを使用します。RIP データベースのサマリー アドレス エントリを表示するには、 show ip rip database 特権 EXEC コマンドを使用します。
RIP 認証の設定
RIP バージョン 1 では、認証がサポートされていません。RIP バージョン 2 のパケットを送受信する場合は、インターフェイスで RIP 認証をイネーブルにできます。インターフェイスで使用できる一連の鍵は、キー チェーンによって決まります。キー チェーンが設定されていないと、デフォルトの場合でも認証は実行されません。「認証鍵の管理」に記載されている作業も実行してください。
RIP 認証がイネーブルであるインターフェイスでは、プレーン テキストと MD5 という 2 つの認証モードがサポートされています。デフォルトはプレーン テキストです。
インターフェイスに RIP 認証を設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
クリア テキスト認証に戻すには、 no ip rip authentication mode インターフェイス コンフィギュレーション コマンドを使用します。認証を禁止するには、 no ip rip authentication key-chain インターフェイス コンフィギュレーション コマンドを使用します。
サマリー アドレスおよびスプリット ホライズンの設定
ブロードキャストタイプの IP ネットワークに接続され、ディスタンス ベクタ ルーティング プロトコルを使用するルータでは、通常ルーティング ループの発生を抑えるために、スプリット ホライズン メカニズムが使用されます。スプリット ホライズンは、ルートに関する情報がその情報の発信元であるインターフェイスで、ルータによってアドバタイズされないようにします。この機能を使用すると、通常の場合は複数のルータ間通信が最適化されます(特にリンクが壊れている場合)。
(注) ルートを適切にアドバタイズするため、スプリット ホライズンをディセーブルにすることがアプリケーションに必要な場合を除き、通常はこの機能をディセーブルにしないでください。
ダイヤルアップ クライアント用のネットワーク アクセス サーバで、サマライズされたローカルな IP アドレス プールをアドバタイズするように、RIP が動作しているインターフェイスを設定する場合は、 ip summary-address rip インターフェイス コンフィギュレーション コマンドを使用します。
(注) スプリット ホライズンがイネーブルの場合、自動サマリーとインターフェイス IP サマリー アドレスはともにアドバタイズされません。
サマライズされたローカル IP アドレスをアドバタイズし、インターフェイスのスプリット ホライズンをディセーブルにするようにインターフェイスを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
IP サマライズをディセーブルにするには、 no ip summary-address rip ルータ コンフィギュレーション コマンドを使用します。
次の例では、主要ネットは 10.0.0.0 です。自動サマリー アドレス 10.0.0.0 はサマリー アドレス 10.2.0.0 によって上書きされるため、10.2.0.0 はインターフェイス ギガビット イーサネット ポート 2 からアドバタイズされますが、10.0.0.0 はアドバタイズされません。次の例では、インターフェイスがまだレイヤ 2 モード(デフォルト)の場合、 no switchport インターフェイス コンフィギュレーション コマンドを入力してから、 ip address インターフェイス コンフィギュレーション コマンドを入力する必要があります。
(注) スプリット ホライズンがイネーブルである場合、(ip summary-address rip ルータ コンフィギュレーション コマンドによって設定される)自動サマリーとインターフェイス サマリー アドレスはともにアドバタイズされません。
スプリット ホライズンの設定
ブロードキャストタイプの IP ネットワークに接続され、ディスタンス ベクタ ルーティング プロトコルを使用するルータでは、通常ルーティング ループの発生を抑えるために、スプリット ホライズン メカニズムが使用されます。スプリット ホライズンは、ルートに関する情報がその情報の発信元であるインターフェイスで、ルータによってアドバタイズされないようにします。この機能を使用すると、複数のルータ間通信が最適化されます(特にリンクが壊れている場合)。
(注) ルートを適切にアドバタイズするために、スプリット ホライズンをディセーブルにすることがアプリケーションに必要である場合を除き、通常この機能をディセーブルにしないでください。
インターフェイスでスプリット ホライズンをディセーブルにするには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
スプリット ホライズン メカニズムをイネーブルにするには、 ip split-horizon インターフェイス コンフィギュレーション コマンドを使用します。
OSPF の設定
ここでは、OSPF の設定方法について簡単に説明します。OSPF コマンドの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 を参照してください。これには、Cisco.com ホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [ Command References])からアクセスできます。
(注) OSPF では、各メディアがブロードキャスト ネットワーク、非ブロードキャスト ネットワーク、ポイントツーポイント ネットワークに分類されます。スイッチでは、ブロードキャスト ネットワーク(イーサネット、トークン リング、FDDI)およびポイントツーポイント ネットワーク(ポイントツーポイント リンクとして設定されたイーサネット インターフェイス)がサポートされます。
OSPF は IP ネットワーク専用の IGP で、IP サブネット化、および外部から取得したルーティング情報のタグ付けをサポートしています。OSPF を使用するとパケット認証も可能になり、パケットを送受信するときに IP マルチキャストが使用されます。シスコの実装機能では、RFC1253 の OSPF MIB(管理情報ベース)がサポートされています。
シスコの実装機能は、次の主要機能を含む OSPF バージョン 2 仕様に準拠します。
•![]() 任意の IP ルーティング プロトコルによって取得されたルートは、別の IP ルーティング プロトコルに再配信されます。つまり、ドメイン内レベルで、OSPF は EIGRP および RIP によって取得したルートを取り込むことができます。OSPF ルートを RIP に伝達することもできます。
任意の IP ルーティング プロトコルによって取得されたルートは、別の IP ルーティング プロトコルに再配信されます。つまり、ドメイン内レベルで、OSPF は EIGRP および RIP によって取得したルートを取り込むことができます。OSPF ルートを RIP に伝達することもできます。
•![]() エリア内の近接ルータ間でのプレーン テキスト認証および MD5 認証がサポートされています。
エリア内の近接ルータ間でのプレーン テキスト認証および MD5 認証がサポートされています。
•![]() 設定可能なルーティング インターフェイス パラメータには、インターフェイス出力コスト、再送信インターバル、インターフェイス送信遅延、ルータ プライオリティ、ルータの dead と hello インターバル、認証鍵などがあります。
設定可能なルーティング インターフェイス パラメータには、インターフェイス出力コスト、再送信インターバル、インターフェイス送信遅延、ルータ プライオリティ、ルータの dead と hello インターバル、認証鍵などがあります。
•![]() RFC 1587 に基づく Not-So-Stubby-Area(NSSA)がサポートされています。
RFC 1587 に基づく Not-So-Stubby-Area(NSSA)がサポートされています。
通常、OSPF を使用するには、多くの内部ルータ、複数のエリアに接続された Area Border Router (ABR; エリア境界ルータ)、および Autonomous System Boundary Router (ASBR; 自律システム境界ルータ)間で調整する必要があります。最小設定では、すべてのデフォルト パラメータ値、エリアに割り当てられたインターフェイスが使用され、認証は行われません。環境をカスタマイズする場合は、すべてのルータの設定を調整する必要があります。
(注) OSPF をイネーブルにするには、スタック マスター上で IP サービス イメージが稼動している必要があります。
OSPF のデフォルト設定
表 38-5 に、OSPF のデフォルト設定を示します。
|
|
|
|---|---|
ディセーブル。イネーブルの場合、デフォルトのメトリック設定は 10 で、外部ルート タイプのデフォルトはタイプ 2 です。 |
|
dist1(エリア内のすべてのルート):110。 |
|
NSF1 認識 |
IP サービス イメージが稼動しているスイッチの場合、イネーブル。 レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、近接する NSF 対応ルータからのパケットを転送し続けることができます。 |
ディセーブル。Catalyst 3750 スイッチは、IPv4 対応の OSPF NSF(NSF 対応ルーティング)をサポートしています。 |
|
OSPF Nonstop Forwarding
OSPF NSF 認識
IP サービス イメージは IPv4 の OSPF NSF 認識をサポートしています。近接ルータが NSF 対応で、レイヤ 3 スイッチでは、プライマリ Route Processor(RP)に障害が発生してルータのバックアップ RP によって引き継がれる前に、または処理を中断させずにソフトウェア アップグレードを行うためにプライマリ RP を手動でリロードしている間、ルータからパケットを転送し続けます。
この機能をディセーブルにすることはできません。この機能の詳細については、次の URL の『 OSPF Nonstop Forwarding (NSF) Awareness Feature Guide 』を参照してください。
http://www.cisco.com/en/US/products/sw/iosswrel/ps1839/products_white_paper09186a0080153edd.shtml
OSPF NSF 機能
IP サービス イメージは、良好なコンバージェンスおよびスタック マスター変更後のトラフィックの損失を低減させるために、IPv4 の OSPF NSF 対応ルーティングをサポートしています。スタック マスターの変更が OSPF NSF 対応スタックで発生すると、新規スタック マスターでは、OSFP ネイバーとのリンクステート デーベースを再同期させるために、次の 2 つのことを行う必要があります。
•![]() ネイバー関係をリセットせずにネットワーク上にある、利用可能な OSPF ネイバーを解放する。
ネイバー関係をリセットせずにネットワーク上にある、利用可能な OSPF ネイバーを解放する。
•![]() ネットワークのリンクステート データベースの内容を再取得する。
ネットワークのリンクステート データベースの内容を再取得する。
スタック マスターの変更後、新規マスターは OSPF NSF 信号をネイバー NSF 認識デバイスに送信します。デバイスでは、この信号を認識してスタックとのネイバー関係をリセットする必要がないことを把握します。NSF 対応スタック マスターは、ネットワーク上の他のルートから信号を受信すると、近接リストの再構築を開始します。
ネイバー関係が再構築されると、NSF 対応スタック マスターがデータベースと NSF 認識ネイバーを再同期させ、ルーティング情報を OSPF ネイバーと交換します。新規スタック マスターがこのルーティング情報を使用して無効なルートを削除し、Routing Information Database(RIB)をアップデートし、新規情報で Forwarding Information Base(FIB; 転送情報ベース)をアップデートします。これで、OSPF プロトコルが完全にコンバージします。
(注) OSPF NSF では、すべての近接ネットワーキング デバイスが NSF 認識となっている必要があります。NSF 対応ルータがネットワーク セグメント内で非 NSF 対応ネイバーを検出すると、そのセグメントの NSF 機能がディセーブルになります。すべてのデバイスが NSF 認識または NSF 対応である他のネットワーク セグメントでは、NSF 機能が提供され続けます。
OSPF NSF ルーティングをイネーブルにするには、 nsf OSPF ルーティング コンフィギュレーション コマンドを使用します。このルーティングがイネーブルであることを確認するには、 show ip ospf 特権 EXEC コマンドを使用します。
NSF の詳細については、次の URL の『 Cisco Nonstop Forwarding Feature Overview 』を参照してください。 http://www.cisco.com/en/US/products/sw/iosswrel/ps1829/products_feature_guide09186a00800ab7fc.html
(注) NSF は、Hot Standby Router Protocol(HSRP; ホットスタンバイ ルータ プロトコル)に設定されたインターフェイスをサポートしていません。
基本的な OSPF パラメータの設定
OSPF をイネーブルにするには、OSPF ルーティング プロセスを作成し、ルーティング プロセスに関連付ける IP アドレスの範囲を指定して、この範囲に関連付けるエリア ID を割り当てる必要があります。
OSPF をイネーブルにするには、特権 EXEC モードで次の手順を実行します。
OSPF ルーティング プロセスを終了するには、 no router ospf process-id グローバル コンフィギュレーション コマンドを使用します。
次に、OSPF ルーティング プロセスを設定し、プロセス番号 109 を割り当てる例を示します。
OSPF インターフェイスの設定
ip ospf インターフェイス コンフィギュレーション コマンドを使用すると、インターフェイス固有の OSPF パラメータを変更できます。これらのパラメータを変更する必要はありませんが、一部のインターフェイス パラメータ(hello インターバル、dead インターバル、認証鍵など)については、接続されたネットワーク内のすべてのルータで統一性を維持する必要があります。これらのパラメータを変更した場合は、ネットワーク内のすべてのルータの値も同様に変更してください。
(注) ip ospf インターフェイス コンフィギュレーション コマンドはすべて任意です。
OSPF インターフェイス パラメータを変更にするには、特権 EXEC モードで次の手順を実行します。
OSPF エリア パラメータの設定
複数の OSPF エリア パラメータを設定することもできます。設定できるパラメータには、エリア、スタブ エリア、および Not-So-Stubby-Area(NSSA)への無許可アクセスをパスワードによって阻止する認証用パラメータがあります。 スタブ エリア に外部ルートに関する情報は送信されません が、代わりに、Autonomous System(AS; 自律システム)外の宛先に対するデフォルトの外部ルートが、Area Border Router(ABR)によって生成されます。NSSA ではコアからそのエリアへ向かう LSA の一部がフラッディングされませんが、再配信することによって、エリア内の AS 外部ルートを取り込むことができます。
ルートのサマライズは、アドバタイズされたアドレスを、他のエリアでアドバタイズされる単一のサマリー ルートに統合することです。ネットワーク番号が連続する場合は、 area range ルータ コンフィギュレーション コマンドを使用し、範囲内のすべてのネットワークを対象とするサマリー ルートをアドバタイズするように ABR を設定できます。
(注) OSPF area ルータ コンフィギュレーション コマンドはすべて任意です。
エリア パラメータを設定するには、特権 EXEC モードで次の手順を実行します。
その他の OSPF パラメータの設定
ルータ コンフィギュレーション モードで、その他の OSPF パラメータを設定することもできます。
•![]() ルート サマライズ:他のプロトコルからのルートを再配信すると(「ルート マップによるルーティング情報の再配信」を参照)、各ルートは外部 LSA 内で個別にアドバタイズされます。OSPF リンク ステート データベースのサイズを小さくするには、 summary-address ルータ コンフィギュレーション コマンドを使用し、指定されたネットワーク アドレスおよびマスクに含まれる、再配信されたすべてのルートを単一のルータにアドバタイズします。
ルート サマライズ:他のプロトコルからのルートを再配信すると(「ルート マップによるルーティング情報の再配信」を参照)、各ルートは外部 LSA 内で個別にアドバタイズされます。OSPF リンク ステート データベースのサイズを小さくするには、 summary-address ルータ コンフィギュレーション コマンドを使用し、指定されたネットワーク アドレスおよびマスクに含まれる、再配信されたすべてのルートを単一のルータにアドバタイズします。
•![]() 仮想リンク:OSPF では、すべてのエリアがバックボーン エリアに接続されている必要があります。バックボーンが不連続である場合に仮想リンクを確立するには、2 つの ABR を仮想リンクのエンドポイントとして設定します。設定情報には、他の仮想エンドポイント(他の ABR)の ID、および 2 つのルータに共通する非バックボーン リンク(通過エリア)などがあります。仮想リンクをスタブ エリアから設定することはできません。
仮想リンク:OSPF では、すべてのエリアがバックボーン エリアに接続されている必要があります。バックボーンが不連続である場合に仮想リンクを確立するには、2 つの ABR を仮想リンクのエンドポイントとして設定します。設定情報には、他の仮想エンドポイント(他の ABR)の ID、および 2 つのルータに共通する非バックボーン リンク(通過エリア)などがあります。仮想リンクをスタブ エリアから設定することはできません。
•![]() デフォルト ルート:OSPF ルーティング ドメイン内へのルート再配信を設定すると、ルータは自動的に自律システム境界ルータ(ASBR)になります。ASBR を設定し、強制的に OSPF ルーティング ドメインにデフォルト ルートを生成できます。
デフォルト ルート:OSPF ルーティング ドメイン内へのルート再配信を設定すると、ルータは自動的に自律システム境界ルータ(ASBR)になります。ASBR を設定し、強制的に OSPF ルーティング ドメインにデフォルト ルートを生成できます。
•![]() すべての OSPF show 特権 EXEC コマンドで使用される Domain Name Server(DNS)名を使用すると、ルータ ID やネイバー ID を指定して表示する場合に比べ、ルータを簡単に特定できます。
すべての OSPF show 特権 EXEC コマンドで使用される Domain Name Server(DNS)名を使用すると、ルータ ID やネイバー ID を指定して表示する場合に比べ、ルータを簡単に特定できます。
•![]() デフォルト メトリック:OSPF は、インターフェイスの帯域幅に従ってインターフェイスの OSPF メトリックを計算します。メトリックは、帯域幅で分割された ref-bw として計算されます。ここでの ref のデフォルト値は 10 で、帯域幅( bw )は bandwidth インターフェイス コンフィギュレーション コマンドによって指定されます。大きな帯域幅を持つ複数のリンクの場合は、大きな数値を指定し、これらのリンクのコストを区別できます。
デフォルト メトリック:OSPF は、インターフェイスの帯域幅に従ってインターフェイスの OSPF メトリックを計算します。メトリックは、帯域幅で分割された ref-bw として計算されます。ここでの ref のデフォルト値は 10 で、帯域幅( bw )は bandwidth インターフェイス コンフィギュレーション コマンドによって指定されます。大きな帯域幅を持つ複数のリンクの場合は、大きな数値を指定し、これらのリンクのコストを区別できます。
•![]() 管理距離は、ルーティング情報送信元の信頼性を表す数値です。0 ~ 255 の整数を指定でき、値が大きいほど信頼性は低下します。管理距離が 255 の場合はルーティング情報送信元をまったく信頼できないため、無視する必要があります。OSPF では、エリア内のルート(エリア内)、別のエリアへのルート(エリア間)、および再配信によって取得した別のルーティング ドメインからのルート(外部)の 3 つの管理距離が使用されます。どの管理距離の値でも変更できます。
管理距離は、ルーティング情報送信元の信頼性を表す数値です。0 ~ 255 の整数を指定でき、値が大きいほど信頼性は低下します。管理距離が 255 の場合はルーティング情報送信元をまったく信頼できないため、無視する必要があります。OSPF では、エリア内のルート(エリア内)、別のエリアへのルート(エリア間)、および再配信によって取得した別のルーティング ドメインからのルート(外部)の 3 つの管理距離が使用されます。どの管理距離の値でも変更できます。
•![]() パッシブ インターフェイス:イーサネット上の 2 つのデバイス間のインターフェイスは 1 つのネットワーク セグメントしか表しません。このため、OSPF が送信側インターフェイスに hello パケットを送信しないようにするには、送信側デバイスをパッシブ インターフェイスに設定する必要があります。両方のデバイスは受信側インターフェイス宛の hello パケットを使用することで、相互の識別を可能にします。
パッシブ インターフェイス:イーサネット上の 2 つのデバイス間のインターフェイスは 1 つのネットワーク セグメントしか表しません。このため、OSPF が送信側インターフェイスに hello パケットを送信しないようにするには、送信側デバイスをパッシブ インターフェイスに設定する必要があります。両方のデバイスは受信側インターフェイス宛の hello パケットを使用することで、相互の識別を可能にします。
•![]() ルート計算タイマー:OSPF がトポロジ変更を受信してから SPF 計算を開始するまでの遅延時間、および 2 つの SPF 計算の間のホールド タイムを設定できます。
ルート計算タイマー:OSPF がトポロジ変更を受信してから SPF 計算を開始するまでの遅延時間、および 2 つの SPF 計算の間のホールド タイムを設定できます。
•![]() ネイバー変更ログ:OSPF ネイバー ステートが変更されたときに Syslog メッセージを送信するようにルータを設定し、ルータの変更を詳細に表示できます。
ネイバー変更ログ:OSPF ネイバー ステートが変更されたときに Syslog メッセージを送信するようにルータを設定し、ルータの変更を詳細に表示できます。
上記の OSPF パラメータを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
(任意)1 つのサマリー ルートだけがアドバタイズされるように、再配信されたルートのアドレスおよび IP サブネット マスクを指定します。 |
||
area area-id virtual-link router-id [ hello-interval seconds ] [ retransmit-interval seconds ] [ trans ] [[ authentication-key key ] | message-digest-key keyid md5 key ]] |
(任意)仮想リンクを確立し、パラメータを設定します。パラメータ定義については「OSPF インターフェイスの設定」、仮想リンクのデフォルト設定については表 38-5 を参照してください。 |
|
default-information originate [ always ] [ metric metric-value ] [ metric-type type-value ] [ route-map map-name ] |
(任意)強制的に OSPF ルーティング ドメインにデフォルト ルートを生成するように ASBR を設定します。パラメータはすべて任意です。 |
|
distance ospf {[ inter-area dist1 ] [ inter-area dist2 ] [ external dist3 ]} |
(任意)OSPF の距離の値を変更します。各タイプのルートのデフォルト距離は 110 です。指定できる範囲は 1 ~ 255 です。 |
|
| • • |
||
特定のルータの OSPF データベースに関連する情報のリストを表示します。キーワード オプションの一部については、「OSPF のモニタ」を参照してください。 |
||
LSA グループ同期設定の変更
OSPF LSA グループ同期設定機能を使用すると、OSPF LSA をグループ化し、リフレッシュ、チェックサム、エージング機能の同期を取って、ルータをより効率的に使用することが可能となります。デフォルトでこの機能はイネーブルとなっています。デフォルトの同期インターバルは 4 分間です。通常は、このパラメータを変更する必要はありません。最適なグループ同期インターバルは、ルータがリフレッシュ、チェックサム、エージングを行う LSA 数に反比例します。たとえば、データベース内に約 10,000 個の LSA が格納されている場合は、同期設定インターバルを短くすると便利です。小さなデータベース(40 ~ 100 LSA)を使用する場合は、同期インターバルを長くし、10 ~ 20 分に設定してください。
OSPF LSA 同期を設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
デフォルト値に戻すには、 no timers lsa-group-pacing ルータ コンフィギュレーション コマンドを使用します。
ループバック インターフェイスの設定
OSPF は、インターフェイスに設定されている最大の IP アドレスをルータ ID として使用します。このインターフェイスがダウンした場合、または削除された場合、OSPF プロセスは新しいルータ ID を再計算し、すべてのルーティング情報をそのルータのインターフェイスから再送信します。ループバック インターフェイスが IP アドレスによって設定されている場合、他のインターフェイスにより大きな IP アドレスがある場合でも、OSPF はこの IP アドレスをルータ ID として使用します。ループバック インターフェイスに障害は発生しないため、安定性は増大します。OSPF は他のインターフェイスよりもループバック インターフェイスを自動的に優先し、すべてのループバック インターフェイスの中で最大の IP アドレスを選択します。
ループバック インターフェイスを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
ループバック インターフェイスをディセーブルにするには、 no interface loopback 0 グローバル コンフィギュレーション コマンドを使用します。
OSPF のモニタ
IP ルーティング テーブル、キャッシュ、データベースの内容など、特定の統計情報を表示できます。
表 38-6 に、統計情報を表示するために使用する特権 EXEC コマンドの一部を示します。 show ip ospf database 特権 EXEC コマンドのオプションおよび表示されるフィールドの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 を参照してください。
EIGRP の設定
EIGRP は IGRP のシスコ独自の拡張バージョンです。EIGRP は IGRP と同じディスタンス ベクタ アルゴリズムおよび距離情報を使用しますが、EIGRP では収束性および動作効率が大幅に改善されています。
コンバージェンス技術には、Diffusing Update Algorithm(DUAL)と呼ばれるアルゴリズムが採用されています。DUAL を使用すると、ルート計算の各段階でループが発生しなくなり、トポロジの変更に関連するすべてのデバイスを同時に同期できます。トポロジ変更の影響を受けないルータは、再計算から除外されます。
IP EIGRP を導入すると、ネットワークの幅が広がります。RIP の場合、ネットワークの最大幅は 15 ホップです。EIGRP メトリックは数千ホップをサポートするほど大きいため、ネットワークを拡張するときに問題となるのは、トランスポート レイヤのホップ カウンタだけです。IP パケットが 15 台のルータを経由し、宛先方向のネクスト ホップが EIGRP によって取得されている場合だけ、EIGRP は転送制御フィールドの値を増やします。RIP ルートを宛先へのネクスト ホップとして使用する場合、転送制御フィールドでは、通常どおり値が増加します。
•![]() 差分更新:宛先のステートが変更された場合、ルーティング テーブルの内容全体を送信する代わりに差分更新を行い、EIGRP パケットに必要な帯域幅を最小化します。
差分更新:宛先のステートが変更された場合、ルーティング テーブルの内容全体を送信する代わりに差分更新を行い、EIGRP パケットに必要な帯域幅を最小化します。
•![]() 低い CPU 使用率:受信ごとに完全更新パケットを処理する必要がないため、CPU 使用率が低下します。
低い CPU 使用率:受信ごとに完全更新パケットを処理する必要がないため、CPU 使用率が低下します。
•![]() プロトコルに依存しない近接ディスカバリ メカニズム:このメカニズムを使用し近接ルータに関する情報を取得します。
プロトコルに依存しない近接ディスカバリ メカニズム:このメカニズムを使用し近接ルータに関する情報を取得します。
•![]() Variable-Length Subnet Mask(VLSM; 可変長サブネット マスク)
Variable-Length Subnet Mask(VLSM; 可変長サブネット マスク)
EIGRP には次に示す 4 つの基本コンポーネントがあります。
•![]() 近接ディスカバリおよび回復 :直接接続されたネットワーク上の他のルータに関する情報を動的に取得するために、ルータで使用されるプロセスです。ネイバーが到達不能になる場合、または操作不能になった場合、ルータもこの情報を検出する必要があります。近接ディスカバリおよび回復は、サイズの小さな hello パケットを定期的に送信することにより、わずかなオーバーヘッドで実現されます。hello パケットが受信されているかぎり、Cisco ISO ソフトウェアは、ネイバーが有効に機能していると学習します。このように判別された場合、近接ルータはルーティング情報を交換できます。
近接ディスカバリおよび回復 :直接接続されたネットワーク上の他のルータに関する情報を動的に取得するために、ルータで使用されるプロセスです。ネイバーが到達不能になる場合、または操作不能になった場合、ルータもこの情報を検出する必要があります。近接ディスカバリおよび回復は、サイズの小さな hello パケットを定期的に送信することにより、わずかなオーバーヘッドで実現されます。hello パケットが受信されているかぎり、Cisco ISO ソフトウェアは、ネイバーが有効に機能していると学習します。このように判別された場合、近接ルータはルーティング情報を交換できます。
•![]() 信頼できるトランスポート プロトコル :EIGRP パケットをすべてのネイバーに確実に、順序どおりに配信します。マルチキャストおよびユニキャスト パケットが混在する送信もサポートされます。EIGRP パケットには確実に送信する必要があるものと、そうでないものがあります。効率を高めるために、必要な場合だけ信頼性が確保されます。たとえば、マルチキャスト機能があるマルチアクセス ネットワーク(イーサネットなど)では、すべてのネイバーにそれぞれ hello パケットを確実に送信する必要はありません。したがって、EIGRP はパケットへの確認応答が不要であることを知らせる、レシーバー宛の情報をパケットに格納し、単一のマルチキャスト hello を送信します。他のタイプのパケット(アップデートなど)の場合は、確認応答(ACK パケット)を要求します。信頼性の高い伝送であれば、ペンディング中の未確認応答パケットがある場合、マルチキャスト パケットを迅速に送信できます。このため、リンク速度が変化する場合でも、コンバージェンス時間を短く保つことができます。
信頼できるトランスポート プロトコル :EIGRP パケットをすべてのネイバーに確実に、順序どおりに配信します。マルチキャストおよびユニキャスト パケットが混在する送信もサポートされます。EIGRP パケットには確実に送信する必要があるものと、そうでないものがあります。効率を高めるために、必要な場合だけ信頼性が確保されます。たとえば、マルチキャスト機能があるマルチアクセス ネットワーク(イーサネットなど)では、すべてのネイバーにそれぞれ hello パケットを確実に送信する必要はありません。したがって、EIGRP はパケットへの確認応答が不要であることを知らせる、レシーバー宛の情報をパケットに格納し、単一のマルチキャスト hello を送信します。他のタイプのパケット(アップデートなど)の場合は、確認応答(ACK パケット)を要求します。信頼性の高い伝送であれば、ペンディング中の未確認応答パケットがある場合、マルチキャスト パケットを迅速に送信できます。このため、リンク速度が変化する場合でも、コンバージェンス時間を短く保つことができます。
•![]() DUAL 有限状態マシン :すべてのルート計算に関する決定プロセスを統合し、すべてのネイバーによってアドバタイズされたすべてのルートをトラッキングします。DUAL は距離情報(メトリックともいう)を使用して、効率的な、ループのないパスを選択し、さらに DUAL は適切な後継ルータに基づいて、ルーティング テーブルに挿入するルートを選択します。後継ルータは、宛先への最小コスト パス(ルーティング ループに関連しないことが保証されている)を持つ、パケット転送に使用される近接ルータです。適切な後継ルータが存在しなくても、宛先にアドバタイズするネイバーが存在する場合は再計算が行われ、この結果、新しい後継ルータが決定されます。ルートの再計算に要する時間によって、コンバージェンス時間が変わります。再計算はプロセッサに負荷がかかるため、必要でない場合は、再計算しないようにしてください。トポロジが変更されると、DUAL は適切な後継ルータの有無を調べます。適切な後継ルータが存在する場合は、それらを探して使用し、不要な再計算を回避します。
DUAL 有限状態マシン :すべてのルート計算に関する決定プロセスを統合し、すべてのネイバーによってアドバタイズされたすべてのルートをトラッキングします。DUAL は距離情報(メトリックともいう)を使用して、効率的な、ループのないパスを選択し、さらに DUAL は適切な後継ルータに基づいて、ルーティング テーブルに挿入するルートを選択します。後継ルータは、宛先への最小コスト パス(ルーティング ループに関連しないことが保証されている)を持つ、パケット転送に使用される近接ルータです。適切な後継ルータが存在しなくても、宛先にアドバタイズするネイバーが存在する場合は再計算が行われ、この結果、新しい後継ルータが決定されます。ルートの再計算に要する時間によって、コンバージェンス時間が変わります。再計算はプロセッサに負荷がかかるため、必要でない場合は、再計算しないようにしてください。トポロジが変更されると、DUAL は適切な後継ルータの有無を調べます。適切な後継ルータが存在する場合は、それらを探して使用し、不要な再計算を回避します。
•![]() プロトコル依存モジュール :ネットワーク レイヤ プロトコル特有の作業を行います。たとえば、IP EIGRP モジュールは、IP でカプセル化された EIGRP パケットを送受信します。このモジュールは、EIGRP パケットを解析し、受信した新しい情報を DUAL に通知する作業を行います。EIGRP は DUAL にルーティング決定を行うように要求しますが、結果は IP ルーティング テーブルに格納されます。EIGRP は、他の IP ルーティング プロトコルによって取得したルートの再配信も行います。
プロトコル依存モジュール :ネットワーク レイヤ プロトコル特有の作業を行います。たとえば、IP EIGRP モジュールは、IP でカプセル化された EIGRP パケットを送受信します。このモジュールは、EIGRP パケットを解析し、受信した新しい情報を DUAL に通知する作業を行います。EIGRP は DUAL にルーティング決定を行うように要求しますが、結果は IP ルーティング テーブルに格納されます。EIGRP は、他の IP ルーティング プロトコルによって取得したルートの再配信も行います。
(注) EIGRP をイネーブルにするには、スタック マスター上で IP サービス イメージが稼動している必要があります。
EIGRP のデフォルト設定
表 38-7 に、EIGRP のデフォルト設定を示します。
|
|
|
|---|---|
デフォルト メトリックなしで再配信できるのは、接続されたルートおよびインターフェイスのスタティック ルートだけです。デフォルト メトリックは次のとおりです。 • • • • |
|
低速の Nonbroadcast Multiaccess(NBMA; 非ブロードキャスト マルチアクセス)ネットワークの場合:60 秒、それ以外のネットワークの場合:5 秒 |
|
NSF2 認識 |
IP サービス イメージが稼動しているスイッチの場合、イネーブル。 レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、近接する NSF 対応ルータからのパケットを転送し続けることができます。 |
| (注) Catalyst 3750 スイッチは IPv4 の EIGRP NSF 対応ルーティングをサポートしています。 | |
EIGRP ルーティング プロセスを作成するには、EIGRP をイネーブルにし、ネットワークを関連付ける必要があります。EIGRP は指定されたネットワーク内のインターフェイスにアップデートを送信します。インターフェイス ネットワークを指定しないと、どの EIGRP アップデートでもアドバタイズされません。
(注) ネットワーク上に IGRP 用に設定されているルータがあり、この設定を EIGRP に変更する場合は、IGRP と EIGRP の両方が設定された移行ルータを指定する必要があります。この場合は、この次のセクションに記載されているステップ 1 ~ 3 を実行してください(「スプリット ホライズンの設定」も参照)。ルートを自動的に再配信するには、同じ AS 番号を使用する必要があります。
EIGRP Nonstop Forwarding
EIGRP NSF 認識
EIGRP NSF 認識機能が IP サービス イメージの IPv4 でサポートされています。近接ルータが NSF 対応である場合、レイヤ 3 スイッチでは、ルータに障害が発生してプライマリ RP がバックアップ RP によって引き継がれる間、または処理を中断させずにソフトウェア アップグレードを行うためにプライマリ RP を手動でリロードしている間、近接ルータからパケットを転送し続けます。
この機能をディセーブルにすることはできません。この機能の詳細については、次の URL の『 EIGRP Nonstop Forwarding (NSF) Awareness Feature Guide 』を参照してください。 http://www.cisco.com/en/US/products/sw/iosswrel/ps1839/products_feature_guide09186a0080160010.html
EIGRP NSF 機能
良好なコンバージェンスと、スタック マスター変更後のトラフィック損失を低減させるために、IP サービス イメージで IPv4 の EIGRP NSF 対応ルーティングをサポートしています。EIGRP NSF 対応スタック マスターがリスタートする際、または新規スタック マスターが起動して NSF が再起動する際、スイッチにはネイバーがなく、トポロジ テーブルは空です。スイッチでは、スイッチ スタックに向かうトラフィックを中断せずに、インターフェイスを始動させ、ネイバーを再取得して、トポロジとルーティング テーブルを再構築する必要があります。EIGRP ピア ルータでは、新規スタック マスターから学習したルートを維持し、NSF リスタート プロセスを通じてトラフィックを転送し続けます。
ネイバーによる隣接リセットを避けるために、新規スタック マスターは新規リスタート(RS)ビットを使用して EIGRP パケット ヘッダーにリスタートを表示します。ネイバーがこれを受信すると、ピア リスト内のスタックを同期させてスタックとの隣接関係を維持します。次にネイバーは、NSF 認識を示し新規スタック マスターを援助するように設定された RS ビットとともにトポロジ テーブルをスタック マスターに送信します。
少なくともスタック ピア ネイバーの 1 つが NSF 認識である場合、スタック マスターはアップデートを受信してそのデータベースを再構築します。各 NSF 認識ネイバーは、最後のアップデート パケットで End of Table(EOT)マーカを送信して、テーブル内容の終了を示します。スタック マスターで EOT マーカを受信すると、コンバージェンスを認識し、アップデートの送信を開始します。スタック マスターがすべての EOT マーカをネイバーから受信するか、あるいは NSF コンバージ タイマーが切れると、EIGRP によって RIB がコンバージェンスが通知され、トポロジ テーブルがすべての NSF 認識ピアにフラッディングされます。
(注) NSF は、Hot Standby Router Protocol(HSRP)に設定されたインターフェイスをサポートしていません。
EIGRP NSF ルーティングをイネーブルにするには、 nsf EIGRP ルーティング コンフィギュレーション コマンドを使用します。NFS がデバイスでイネーブルであることを確認するには、 show ip protocol 特権 EXEC コマンドを使用します。 nsf コマンドの詳細については、このリリースに対応するコマンド リファレンスを参照してください。
基本的な EIGRP パラメータの設定
EIGRP を設定するには、特権 EXEC モードで次の手順を実行します。ルーティング プロセスの設定は必須ですが、それ以外のステップは任意です。
EIGRP インターフェイスの設定
インターフェイスごとに、他の EIGRP パラメータを任意で設定できます。
EIGRP インターフェイスを設定するには、特権 EXEC モードで次の手順を実行します。
EIGRP ルート認証の設定
EIGRP ルート認証を行うと、EIGRP ルーティング プロトコルからのルーティング アップデートに関する MD5 認証が可能になり、承認されていない送信元から無許可または問題のあるルーティング メッセージを受け取ることがなくなります。
認証をイネーブルにするには、特権 EXEC モードで次の手順を実行します。
EIGRP スタブ ルーティングの設定
EIGRP スタブ ルーティング機能は、すべてのイメージで使用することができ、エンド ユーザの近くにルーテッド トラフィックを移動することでリソースの利用率を低減させます。
(注) IP ベース イメージに含まれているのは EIGRP スタブ ルーティング機能だけです。この機能は、ルーティング テーブルからネットワークの他のスイッチに接続ルートまたは集約ルートをアドバタイズするだけです。スイッチはアクセス レイヤで EIGRP スタブ ルーティングを使用するため、その他の種類のルーティング アドバタイズを使用する必要がなくなります。拡張機能および完全な EIGRP ルーティングのために、スイッチは IP サービス イメージを実行している必要があります。
IP ベース イメージが稼動しているスイッチで、マルチ VRF CE と EIGRP スタブ ルーティングを同時に設定しようとする場合、この設定は許可されません。
EIGRP スタブ ルーティングを使用するネットワークでは、ユーザへの IP トラフィックの許可ルートだけが EIGRP スタブ ルーティングを設定しているスイッチを通過します。スイッチは、ユーザ インターフェイスとして設定されているインターフェイスまたは他のデバイスに接続されているインターフェイスにルーテッド トラフィックを送信します。
EIGRP スタブ ルーティングを使用しているときは、EIGRP を使用してスイッチだけをスタブとして設定するように、分散ルータおよびリモート ルータを設定する必要があります。指定したルートだけがスイッチから伝播されます。スイッチは、サマリー、接続ルート、およびルーティング アップデートに対するすべてのクエリーに応答します。
スタブ ステータスを通知するパケットを受信するネイバーは、スタブ ルータのクエリーを実行せず、スタブ ピアを有するルータはそのピアのクエリーを実行しません。スタブ ルータは、分散ルータに依存してすべてのピアに適切なアップデートを送信します。
図 38-4 では、スイッチ B が EIGRP スタブ ルータとして設定されています。スイッチ A および C は残りの WAN に接続されています。スイッチ B は、接続ルート、スタティック ルート、再配信ルート、およびサマリー ルートをスイッチ A および C にアドバタイズします。スイッチ B は、スイッチ A から学習したルートをアドバタイズしません(その逆も同様)。
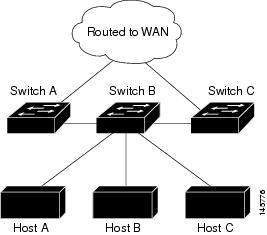
(注) eigrp stub ルータ コンフィギュレーション コマンドを入力したあと、eigrp stub connected summary コマンドだけが有効です。Command-Line Interface(CLI; コマンド ライン インターフェイス)のヘルプが receive-only および static キーワードを表示し、これらのキーワードを入力したとしても、IP ベース イメージが稼動しているスイッチは、常に connected および summary キーワードが設定されているように動作します。
EIGRP スタブ ルーティングの詳細については、『 Cisco IOS IP Configuration Guide, Volume 2 of 3: Routing Protocols 』Release 12.2 の「Configuring EIGRP Stub Routing」を参照してください。このマニュアルには、Cisco.com の [Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Configuration Guides] からアクセスできます。
EIGRP のモニタおよびメンテナンス
近接テーブルからネイバーを削除できます。さらに、各種 EIGRP ルーティング統計情報を表示することもできます。 表 38-8 に、ネイバー削除および統計情報表示用の特権 EXEC コマンドを示しています。表示されるフィールドの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 を参照してください。このマニュアルには、Cisco.com の [Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Command References] からアクセスできます。
|
|
|
|---|---|
show ip eigrp topology [ autonomous-system-number ] | [[ ip-address ] mask ]] |
|
BGP の設定
Border Gateway Protocol(BGP; ボーダー ゲートウェイ プロトコル)は、Exterior Gateway Protocol(EGP; 外部ゲートウェイ プロトコル)です。Autonomous System(AS; 自律システム)間で、ループの発生しないルーティング情報交換を保証するドメイン間ルーティング システムを設定するために使用されます。AS は、同じ管理下で動作して RIP や OSPF などの IGP を境界内で実行し、EGP を使用して相互接続されるルータで構成されます。BGP バージョン 4 は、インターネット内でドメイン間ルーティングを行うための標準 EGP です。このプロトコルは、RFC 1163、1267、および 1771 で定義されています。RIP の詳細については、Cisco Press 発行の『 Internet Routing Architectures 』および、『 Cisco IP and IP Routing Configuration Guide 』の「Configuring BGP」の章を参照してください。この資料には、Cisco.com の [Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Configuration Guides] からアクセスできます。
BGP コマンドおよびキーワードの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 の「IP Routing Protocols」を参照してください。このマニュアルには、Cisco.com の [Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Command References] からアクセスできます。表示されているにもかかわらずスイッチでサポートされない BGP コマンドについては、 付録 D「Cisco IOS Release 12.2(52)SE でサポートされていないコマンド」 を参照してください。
BGP アップデートを交換する場合、同じ AS に属するルータは Internal BGP (IBGP)を実行し、異なる AS に属するルータは External BGP (EBGP)を実行します。大部分のコンフィギュレーション コマンドは、EBGP と IBGP で同じですが、ルーティング アップデートが AS 間で交換されるか(EBGP)、または AS 内で交換されるか(IBGP)という点で異なります。図 38-5 に、EBGP と IBGP の両方が稼動するネットワークを示します。

外部 AS と情報を交換する前に、BGP は AS 内のルータ間で内部 BGP ピアリングを定義し、IGRP や OSPF など AS 内で稼動する IGP に BGP ルーティング情報を再配信して、AS 内のネットワークに到達することを確認します。
BGP ルーティング プロセスを実行するルータは、通常 BGP スピーカー と呼ばれます。BGP はトランスポート プロトコルとして TCP を使用します(特にポート 179)。ルーティング情報を交換するため相互に TCP 接続された 2 つの BGP スピーカーを、ピアまたは ネイバー と呼びます。図 38-5 では、ルータ A と B、ルータ B と C、およびルータ C と D がそれぞれ BGP ピアです。ルーティング情報は、宛先ネットワークへの完全パスを示す一連の AS 番号です。BGP はこの情報を使用し、ループのない AS マップを作成します。
•![]() ルータ A および B では EBGP が、ルータ B および C では IBGP が稼動しています。EBGP ピアは直接接続されていますが、IBGP ピアは直接接続されていないことに注意してください。IGP が稼動し、2 つのネイバーが相互に到達するかぎり、IBGP ピアを直接接続する必要はありません。
ルータ A および B では EBGP が、ルータ B および C では IBGP が稼動しています。EBGP ピアは直接接続されていますが、IBGP ピアは直接接続されていないことに注意してください。IGP が稼動し、2 つのネイバーが相互に到達するかぎり、IBGP ピアを直接接続する必要はありません。
•![]() AS 内のすべての BGP スピーカーは、相互にピア関係を確立する必要があります。つまり、AS 内の BGP スピーカーは、論理的な完全メッシュ型に接続する必要があります。BGP4 は、論理的な完全メッシュに関する要求を軽減する 2 つの技術( 連合 および ルート リフレクタ )を提供します。
AS 内のすべての BGP スピーカーは、相互にピア関係を確立する必要があります。つまり、AS 内の BGP スピーカーは、論理的な完全メッシュ型に接続する必要があります。BGP4 は、論理的な完全メッシュに関する要求を軽減する 2 つの技術( 連合 および ルート リフレクタ )を提供します。
•![]() AS 200 は AS 100 および AS 300 の中継 AS です。つまり、AS 200 は AS 100 と AS 300 間でパケットを転送するために使用されます。
AS 200 は AS 100 および AS 300 の中継 AS です。つまり、AS 200 は AS 100 と AS 300 間でパケットを転送するために使用されます。
BGP ピアは完全な BGP ルーティング テーブルを最初に交換し、差分更新だけを送信します。BGP ピアはキープアライブ メッセージ(接続が有効であることを確認)、および通知メッセージ(エラーまたは特殊条件に応答)を交換することもできます。
BGP の場合、各ルートはネットワーク番号、情報が通過した AS のリスト( AS パス )、および他の パス アトリビュート リストで構成されます。BGP システムの主な機能は、AS パスのリストに関する情報など、ネットワークの到達可能性情報を他の BGP システムと交換することです。この情報は、AS が接続されているかどうかを判別したり、ルーティング ループをプルーニングしたり、AS レベル ポリシー判断を行うために使用できます。
Cisco IOS が稼動しているルータまたはスイッチが IBGP ルートを選択または使用するのは、ネクスト ホップ ルータで使用可能なルートがあり、IGP から同期信号を受信している(IGP 同期がディセーブルの場合は除く)場合です。複数のルートが使用可能な場合、BGP は アトリビュート 値に基づいてパスを選択します。BGP アトリビュートの詳細については、「BGP 判断アトリビュートの設定」を参照してください。
BGP バージョン 4 では Classless Interdomain Routing(CIDR)がサポートされているため、集約ルートを作成して スーパーネット を構築し、ルーティング テーブルのサイズを削減できます。CIDR は、BGP 内部のネットワーク クラスの概念をエミュレートし、IP プレフィクスのアドバタイズメントをサポートします。
•![]() 「BGP フィルタリング用のプレフィクス リストの設定」
「BGP フィルタリング用のプレフィクス リストの設定」
BGP 設定の詳細については、『Cisco IOS IP Configuration Guide』Release 12.2 の「IP Routing Protocols」の「Configuring BGP」を参照してください。特定コマンドの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocol 』Release 12.2 を参照してください。これらのマニュアルは、Cisco.com ホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Configuration Guides] または [Command References])にあります。
表示されているにもかかわらずスイッチでサポートされない BGP コマンドについては、 付録 D「Cisco IOS Release 12.2(52)SE でサポートされていないコマンド」 を参照してください。
BGP のデフォルト設定
表 38-9 に、BGP の基本的なデフォルト設定を示します。すべての特性の詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 の特定のコマンドを参照してください。
|
|
|
|---|---|
• |
|
ループバック インターフェイスに IP アドレスが設定されている場合は、ループバック インターフェイスの IP アドレス、またはルータの物理インターフェイスに対して設定された最大の IP アドレス |
|
• • • • • |
|
NSF3 認識 |
ディセーブル レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、近接する NSF 対応ルータからのパケットを転送し続けることができます。 (注) NSF 認識は、グレースフル リスタートをイネーブルすることにより、IP サービス イメージが稼動しているスイッチの IPv4 に対してイネーブルにできます。 |
NSF 認識
BGP NSF 認識機能が IP サービス イメージの IPv4 でサポートされます。BGP ルーティングでこの機能をイネーブルにするには、グレースフル リスタートをイネーブルにする必要があります。近接ルータが NSF 対応で、この機能がイネーブルである場合、レイヤ 3 スイッチでは、ルータに障害が発生してプライマリ RP がバックアップ RP によって引き継がれる間、または処理を中断させずにソフトウェア アップグレードを行うためにプライマリ RP を手動でリロードしている間、近接ルータからパケットを転送し続けます。
詳細については、次の URL の『 BGP Nonstop Forwarding (NSF) Awareness Feature Guide 』を参照してください。
http://www.cisco.com/en/US/products/sw/iosswrel/ps1839/products_feature_guide09186a008015fede.html
BGP ルーティングのイネーブル化
BGP ルーティングをイネーブルにするには、BGP ルーティング プロセスを確立し、ローカル ネットワークを定義します。BGP はネイバーとの関係を完全に認識する必要があるため、BGP ネイバーも指定する必要があります。
BGP は、内部および外部の 2 種類のネイバーをサポートします。内部ネイバーは同じ AS 内に、外部ネイバーは異なる AS 内にあります。通常の場合、外部ネイバーは相互に隣接し、1 つのサブネットを共有しますが、内部ネイバーは同じ AS 内の任意の場所に存在します。
スイッチではプライベート AS 番号を使用できます。プライベート AS 番号は通常サービス プロバイダーによって割り当てられ、ルートが外部ネイバーにアドバタイズされないシステムに設定されます。プライベート AS 番号の範囲は 64512 ~ 65535 です。AS パスからプライベート AS 番号を削除するように外部ネイバーを設定するには、 neighbor remove-private-as ルータ コンフィギュレーション コマンドを使用します。この結果、外部ネイバーにアップデートを渡すとき、AS パス内にプライベート AS 番号が含まれている場合は、これらの番号が削除されます。
AS が別の AS からさらに別の AS にトラフィックを渡す場合は、アドバタイズメント対象のルートに矛盾が存在しないことが重要です。BGP がルートをアドバタイズしてから、ネットワーク内のすべてのルータが IGP を通してルートを学習した場合、AS は一部のルータがルーティングできなかったトラフィックを受信することがあります。このような事態を避けるため、BGP は IGP が AS に情報を伝播し、BGP が IGP と 同期化 されるまで、待機する必要があります。同期化は、デフォルトでイネーブルに設定されています。AS が特定の AS から別の AS にトラフィックを渡さない場合、または AS 内のすべてのルータで BGP が稼動している場合は、同期化をディセーブルにし、IGP 内で伝送されるルート数を少なくして、BGP がより短時間で収束するようにします。
(注) BGP をイネーブルにするには、スタック マスター上で IP サービス イメージが稼動している必要があります。
BGP ルーティングをイネーブルにして BGP ルーティング プロセスを確立し、ネイバーを指定するには、特権 EXEC モードで次の手順を実行します。
BGP AS を削除するには、 no router bgp autonomous-system グローバル コンフィギュレーション コマンドを使用します。BGP テーブルからネットワークを削除するには、 no network network-number ルータ コンフィギュレーション コマンドを使用します。ネイバーを削除するには、 no neighbor { ip-address | peer-group-name } remote-as number ルータ コンフィギュレーション コマンドを使用します。ネイバーにアップデート内のプライベート AS 番号を追加するには、 no neighbor { ip-address | peer-group-name } remove-private-as ルータ コンフィギュレーション コマンドを使用します。同期化を再度イネーブルにするには、 synchronization ルータ コンフィギュレーション コマンドを使用します。
次に、図 38-5 に示されたルータ上で BGP を設定する例を示します。
BGP ピアが稼動していることを確認するには、show ip bgp neighbors 特権 EXEC コマンドを使用します。次に、ルータ A にこのコマンドを実行した場合の出力例を示します。
state = established 以外の情報が出力された場合、ピアは稼動していません。リモート ルータ ID は、ルータ(または最大のループバック インターフェイス)上の最大の IP アドレスです。テーブルが新規情報でアップデートされるたびに、テーブルのバージョン番号は増加します。継続的にテーブル バージョン番号が増加している場合は、ルートがフラッピングし、ルーティング アップデートが絶えず発生しています。
外部プロトコルの場合、 network ルータ コンフィギュレーション コマンドから IP ネットワークへの参照によって制御されるのは、アドバタイズされるネットワークだけです。これは、 network コマンドを使用してアップデートの送信先を指定する IGP(EIGRP など)と対照的です。
BGP 設定の詳細については、『 Cisco IOS IP Configuration Guide 』Release 12.2 の「IP Routing Protocols」を参照してください。特定コマンドの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocol 』Release 12.2 を参照してください。表示されているにもかかわらずスイッチでサポートされない BGP コマンドについては、 付録 D「Cisco IOS Release 12.2(52)SE でサポートされていないコマンド」 を参照してください。
ルーティング ポリシー変更の管理
ピアのルーティング ポリシーには、着信または発信ルーティング テーブル アップデートに影響する可能性があるすべての設定が含まれます。BGP ネイバーとして定義された 2 台のルータは、BGP 接続を形成し、ルーティング情報を交換します。このあとで BGP フィルタ、ウェイト、距離、バージョン、またはタイマーを変更する場合、または同様の設定変更を行う場合は、BGP セッションをリセットし、設定の変更を有効にする必要があります。
リセットには、ハード リセットとソフト リセットの 2 つのタイプがあります。事前に設定を行わなくても、ソフト リセットを使用できます。事前設定なしにソフト リセットを使用するには、両方の BGP ピアでソフト ルート リフレッシュ機能がサポートされていなければなりません。この機能は、ピアによって TCP セッションが確立されたときに送信される OPEN メッセージに格納されてアドバタイズされます。ソフト リセットを使用すると、BGP ルータ間でルート リフレッシュ要求およびルーティング情報を動的に交換したり、それぞれの発信ルーティング テーブルをあとで再アドバタイズできます。
•![]() ソフト リセットによってネイバーから着信アップデートが生成された場合、このリセットは ダイナミック着信ソフト リセット といいます。
ソフト リセットによってネイバーから着信アップデートが生成された場合、このリセットは ダイナミック着信ソフト リセット といいます。
•![]() ソフト リセットによってネイバーに一連のアップデートが送信された場合、このリセットは 発信ソフト リセット といいます。
ソフト リセットによってネイバーに一連のアップデートが送信された場合、このリセットは 発信ソフト リセット といいます。
ソフト着信リセットが発生すると、新規着信ポリシーが有効になります。ソフト発信リセットが発生すると、BGP セッションがリセットされずに、新規ローカル発信ポリシーが有効になります。発信ポリシーのリセット中に新しい一連のアップデートが送信されると、新規着信ポリシーも有効になる場合があります。
表 38-10 に、ハード リセットとソフト リセットの利点および欠点を示します。
|
|
|
|
|---|---|---|
ネイバーから提供された BGP、IP、および Forwarding Information Base(FIB; 転送情報ベース)テーブルのプレフィクスが失われます。推奨しません。 |
||
BGP ピアがルート リフレッシュ機能をサポートするかどうかを学習して、BGP セッションをリセットするには、特権 EXEC モードで次の手順を実行します。
BGP 判断アトリビュートの設定
BGP スピーカーが複数の AS から受信したアップデートが、同じ宛先に対して異なるパスを示している場合、BGP スピーカーはその宛先に到達する最適パスを 1 つ選択する必要があります。選択されたパスは BGP ルーティング テーブルに格納され、ネイバーに伝播されます。この判断は、アップデートに格納されているアトリビュート値、および BGP で設定可能な他の要因に基づいて行われます。
BGP ピアはネイバー AS からプレフィクスに対する 2 つの EBGP パスを学習するとき、最適パスを選択して IP ルーティング テーブルに挿入します。BGP マルチパス サポートがイネーブルで、同じネイバー AS から複数の EBGP パスを学習する場合、単一の最適パスの代わりに、複数のパスが IP ルーティング テーブルに格納されます。そのあと、パケット スイッチング中に、複数のパス間でパケット単位または宛先単位のロード バランシングが実行されます。 maximum-paths ルータ コンフィギュレーション コマンドは、許可されるパス数を制御します。
これらの要因により、BGP が最適パスを選択するためにアトリビュートを評価する順序が決まります。
1.![]() パスで指定されているネクスト ホップが到達不能な場合、このアップデートは削除されます。BGP のネクスト ホップのアトリビュート(ソフトウェアによって自動判別される)は、宛先に到達するために使用されるネクスト ホップの IP アドレスです。EBGP の場合、通常このアドレスは neighbor remote-as ルータ コンフィギュレーション コマンドで指定されたネイバーの IP アドレスです。ネクスト ホップの処理をディセーブルにするには、ルート マップまたは neighbor next-hop-self ルータ コンフィギュレーション コマンドをネクスト ホップ使用します。
パスで指定されているネクスト ホップが到達不能な場合、このアップデートは削除されます。BGP のネクスト ホップのアトリビュート(ソフトウェアによって自動判別される)は、宛先に到達するために使用されるネクスト ホップの IP アドレスです。EBGP の場合、通常このアドレスは neighbor remote-as ルータ コンフィギュレーション コマンドで指定されたネイバーの IP アドレスです。ネクスト ホップの処理をディセーブルにするには、ルート マップまたは neighbor next-hop-self ルータ コンフィギュレーション コマンドをネクスト ホップ使用します。
2.![]() 最大ウェイトのパスを推奨します(シスコ独自のパラメータ)。ウェイト アトリビュートはルータにローカルであるため、ルーティング アップデートで伝播されません。デフォルトでは、ルータ送信元のパスに関するウェイト アトリビュートは 32768 で、それ以外のパスのウェイト アトリビュートは 0 です。最大ウェイトのルートを推奨します。ウェイトを設定するには、アクセス リスト、ルート マップ、または neighbor weight ルータ コンフィギュレーション コマンドを使用します。
最大ウェイトのパスを推奨します(シスコ独自のパラメータ)。ウェイト アトリビュートはルータにローカルであるため、ルーティング アップデートで伝播されません。デフォルトでは、ルータ送信元のパスに関するウェイト アトリビュートは 32768 で、それ以外のパスのウェイト アトリビュートは 0 です。最大ウェイトのルートを推奨します。ウェイトを設定するには、アクセス リスト、ルート マップ、または neighbor weight ルータ コンフィギュレーション コマンドを使用します。
3.![]() ローカル初期設定値が最大のルートを推奨します。ローカル初期設定はルーティング アップデートに含まれ、同じ AS 内のルータ間で交換されます。ローカル初期設定アトリビュートのデフォルト値は 100 です。ローカル初期設定を設定するには、 bgp default local-preference ルータ コンフィギュレーション コマンドまたはルート マップを使用します。
ローカル初期設定値が最大のルートを推奨します。ローカル初期設定はルーティング アップデートに含まれ、同じ AS 内のルータ間で交換されます。ローカル初期設定アトリビュートのデフォルト値は 100 です。ローカル初期設定を設定するには、 bgp default local-preference ルータ コンフィギュレーション コマンドまたはルート マップを使用します。
4.![]() ローカル ルータ上で稼動する BGP から送信されたルートを推奨します。
ローカル ルータ上で稼動する BGP から送信されたルートを推奨します。
6.![]() 送信元タイプが最小のルートを推奨します。内部ルートまたは IGP は、EGP によって学習されたルートよりも小さく、EGP で学習されたルートは、未知の送信元のルートまたは別の方法で学習されたルートよりも小さくなります。
送信元タイプが最小のルートを推奨します。内部ルートまたは IGP は、EGP によって学習されたルートよりも小さく、EGP で学習されたルートは、未知の送信元のルートまたは別の方法で学習されたルートよりも小さくなります。
7.![]() 想定されるすべてのルートについてネイバー AS が同じである場合は、MED メトリック アトリビュートが最小のルートを推奨します。MED を設定するには、ルート マップまたは default-metric ルータ コンフィギュレーション コマンドを使用します。IBGP ピアに送信されるアップデートには、MED が含まれます。
想定されるすべてのルートについてネイバー AS が同じである場合は、MED メトリック アトリビュートが最小のルートを推奨します。MED を設定するには、ルート マップまたは default-metric ルータ コンフィギュレーション コマンドを使用します。IBGP ピアに送信されるアップデートには、MED が含まれます。
8.![]() 内部(IBGP)パスより、外部(EBGP)パスを推奨します。
内部(IBGP)パスより、外部(EBGP)パスを推奨します。
9.![]() 最も近い IGP ネイバー(最小の IGP メトリック)を通って到達できるルートを推奨します。ルータは、AS 内の最短の内部パス(BGP のネクスト ホップへの最短パス)を使用し、宛先に到達するためです。
最も近い IGP ネイバー(最小の IGP メトリック)を通って到達できるルートを推奨します。ルータは、AS 内の最短の内部パス(BGP のネクスト ホップへの最短パス)を使用し、宛先に到達するためです。
10.![]() 次の条件にすべて該当する場合は、このパスのルートを IP ルーティング テーブルに挿入してください。
次の条件にすべて該当する場合は、このパスのルートを IP ルーティング テーブルに挿入してください。
•![]() 最適ルートと目的のルートの両方が、同じネイバー AS からのルートである
最適ルートと目的のルートの両方が、同じネイバー AS からのルートである
11.![]() マルチパスがイネーブルでない場合は、BGP ルータ ID の IP アドレスが最小であるルートを推奨します。通常、ルータ ID はルータ上の最大の IP アドレスまたはループバック(仮想)アドレスですが、実装に依存することがあります。
マルチパスがイネーブルでない場合は、BGP ルータ ID の IP アドレスが最小であるルートを推奨します。通常、ルータ ID はルータ上の最大の IP アドレスまたはループバック(仮想)アドレスですが、実装に依存することがあります。
同じ判断アトリビュートを設定するには、特権 EXEC モードで次の手順を実行します。
ルート マップによる BGP フィルタリングの設定
BGP 内でルート マップを使用すると、ルーティング情報を制御、変更したり、ルーティング ドメイン間でルートを再配信する条件を定義できます。ルート マップの詳細については、「ルート マップによるルーティング情報の再配信」を参照してください。各ルート マップには、ルート マップを識別する名前( マップ タグ )およびオプションのシーケンス番号が付いています。
ルート マップを使用してネクスト ホップ処理をディセーブルにするには、特権 EXEC モードで次の手順を実行します。
ルート マップを削除するには、 no route-map map-tag コマンドを使用します。ネクスト ホップ処理を再びイネーブルにするには、 no set ip next-hop ip-address コマンドを使用します。
ネイバーによる BGP フィルタリングの設定
BGP アドバタイズメントをフィルタリングするには、 as-path access-list グローバル コンフィギュレーション コマンドや neighbor filter-list ルータ コンフィギュレーション コマンドなどの AS パス フィルタを使用します。 neighbor distribute-list ルータ コンフィギュレーション コマンドとアクセス リストを併用することもできます。distribute-list フィルタはネットワーク番号に適用されます。 distribute-list コマンドの詳細については、「ルーティング アップデートのアドバタイズメントおよび処理の制御」を参照してください。
ネイバー単位でルート マップを使用すると、アップデートをフィルタリングしたり、各アトリビュートを変更できます。ルート マップは、着信アップデートまたは発信アップデートのいずれかに適用できます。ルート マップを渡すルートだけが、アップデート内で送信または許可されます。着信および発信の両方のアップデートで、AS パス、コミュニティ、およびネットワーク番号に基づくマッチングがサポートされています。AS パスのマッチングには match as-path access-lis t ルート マップ コマンド、コミュニティに基づくマッチングには match community-list ルート マップ コマンド、ネットワークに基づくマッチングには ip access-list グローバル コンフィギュレーション コマンドが必要です。
ネイバー単位のルート マップを適用するには、特権 EXEC モードで次の手順を実行します。
ネイバーからアクセス リストを削除するには、 no neighbor distribute-list コマンドを使用します。ネイバーからルート マップを削除するには、 no neighbor route-map map-tag ルータ コンフィギュレーション コマンドを使用します。
BGP AS パスに基づいて着信および発信の両方のアップデートにアクセス リスト フィルタを指定して、フィルタリングすることもできます。各フィルタは、正規表現に基づくアクセス リストです(正規表現の作成方法については、 『Cisco IOS Dial Technologies Command Reference』Release 12.2 の付録「Regular Expressions」を参照してください)。この方法を使用するには、AS パスのアクセス リストを定義し、特定のネイバーに対して送受信されるアップデートに適用します。
BGP パス フィルタリングを設定するには、特権 EXEC モードで次の手順を実行します。
BGP フィルタリング用のプレフィクス リストの設定
neighbor distribute-list ルータ コンフィギュレーション コマンドを含む多数の BGP ルート フィルタリング コマンドでは、アクセス リストの代わりにプレフィクス リストを使用できます。プレフィクス リストを使用すると、大規模リストのロードおよび検索パフォーマンスが改善し、差分更新がサポートされ、CLI(コマンドライン インターフェイス)設定が簡素化され、柔軟性が増すなどの利点が生じます。
プレフィクス リストによるフィルタリングでは、アクセス リストの照合の場合と同様に、プレフィクス リストに記載されたプレフィクスとルートのプレフィクスが照合されます。一致が存在する場合は、一致したルートが使用されます。プレフィクスが許可されるか、または拒否されるかは、次に示す規則に基づいて決定されます。
•![]() 空のプレフィクス リストはすべてのプレフィクスを許可します。
空のプレフィクス リストはすべてのプレフィクスを許可します。
•![]() 指定されたプレフィクスがプレフィクス リスト内のどのエントリとも一致しない場合は、暗黙の拒否が使用されます。
指定されたプレフィクスがプレフィクス リスト内のどのエントリとも一致しない場合は、暗黙の拒否が使用されます。
•![]() 指定されたプレフィクスと一致するエントリがプレフィクス リスト内に複数存在する場合は、シーケンス番号が最小であるプレフィクス リスト エントリが識別されます。
指定されたプレフィクスと一致するエントリがプレフィクス リスト内に複数存在する場合は、シーケンス番号が最小であるプレフィクス リスト エントリが識別されます。
デフォルトでは、シーケンス番号は自動生成され、5 ずつ増分します。シーケンス番号の自動生成をディセーブルにした場合は、エントリごとにシーケンス番号を指定する必要があります。シーケンス番号を指定する場合の増分値に制限はありません。増分値が 1 の場合は、このリストに追加エントリを挿入できません。増分値が大きい場合は、値がなくなることがあります。
コンフィギュレーション エントリを削除する場合は、シーケンス番号を指定する必要はありません。 show コマンドの出力には、シーケンス番号が含まれます。
コマンド内でプレフィクス リストを使用する場合は、あらかじめプレフィクス リストを設定しておく必要があります。プレフィクス リストを作成したり、プレフィクス リストにエントリを追加するには、特権 EXEC モードで次の手順を実行します。
プレフィクス リストまたはそのエントリをすべて削除する場合は、 no ip prefix-list list-name グローバル コンフィギュレーション コマンドを使用します。プレフィクス リストから特定のエントリを削除する場合は、 no ip prefix-list seq seq-value グローバル コンフィギュレーション コマンドを使用します。シーケンス番号の自動生成をディセーブルにするには no ip prefix-list sequence number コマンドを、自動生成を再びイネーブルにするには ip prefix-list sequence number コマンドを使用します。プレフィクス リスト エントリのヒット数テーブルをクリアするには、 clear ip prefix-list 特権 EXEC コマンドを使用します。
BGP コミュニティ フィルタリングの設定
BGP コミュニティ フィルタリングは、COMMUNITIES アトリビュートの値に基づいてルーティング情報の配信を制御する BGP の方法の 1 つです。このアトリビュートによって、宛先はコミュニティにグループ化され、コミュニティに基づいてルーティング判断が適用されます。この方法を使用すると、ルーティング情報の配信制御を目的とする BGP スピーカーの設定が簡単になります。
コミュニティは、共通するいくつかのアトリビュートを共有する宛先のグループです。各宛先は複数のコミュニティに属します。AS 管理者は、宛先が属するコミュニティを定義できます。デフォルトでは、すべての宛先が一般的なインターネット コミュニティに属します。コミュニティは、過渡的でグローバルな、オプションの COMMUNITIES アトリビュート(1 ~4294967200)によって識別されます。事前に定義された既知のコミュニティの一部を、次に示します。
•![]() internet :このルートをインターネット コミュニティにアドバタイズします。すべてのルータが所属します。
internet :このルートをインターネット コミュニティにアドバタイズします。すべてのルータが所属します。
•![]() no-export :EBGP ピアにこのルートをアドバタイズしません。
no-export :EBGP ピアにこのルートをアドバタイズしません。
•![]() no-advertise :いずれのピア(内部または外部)にもこのルートをアドバタイズしません。
no-advertise :いずれのピア(内部または外部)にもこのルートをアドバタイズしません。
•![]() local-as :ローカルな AS 外部のピアにこのルートをアドバタイズしません。
local-as :ローカルな AS 外部のピアにこのルートをアドバタイズしません。
コミュニティに基づき、他のネイバーに許可、送信、配信するルーティング情報を制御できます。BGP スピーカーは、ルートを学習、アドバタイズ、または再配信するときに、ルートのコミュニティを設定、追加、または変更します。ルートを集約すると、作成された集約内の COMMUNITIES アトリビュートに、すべての初期ルートの全コミュニティが含まれます。
コミュニティ リストを使用すると、ルート マップの match ステートメントで使用されるコミュニティ グループを作成できます。さらに、アクセス リストの場合と同様、一連のコミュニティ リストを作成することもできます。ステートメントは一致が見つかるまでチェックされ、1 つのステートメントが満たされると、テストは終了します。
コミュニティに基づいて COMMUNITIES アトリビュートおよび match コマンドを設定するには、「ルート マップによるルーティング情報の再配信」に記載されている match community-list および set community ルート マップ コンフィギュレーション コマンドを参照してください。
デフォルトでは、COMMUNITIES アトリビュートはネイバーに送信されません。COMMUNITIES アトリビュートが特定の IP アドレスのネイバーに送信されるように指定するには、 neighbor send-community ルータ コンフィギュレーション コマンドを使用します。
コミュニティ リストを作成、適用するには、特権 EXEC モードで次の手順を実行します。
BGP ネイバーおよびピア グループの設定
通常、BGP ネイバーの多くは同じアップデート ポリシー(同じ発信ルート マップ、配信リスト、フィルタ リスト、アップデート送信元など)を使用して設定されます。アップデート ポリシーが同じネイバーをピア グループにまとめると設定が簡単になり、アップデートの効率が高まります。多数のピアを設定した場合は、この方法を推奨します。
BGP ピア グループを設定するには、ピア グループを作成し、そこにオプションを割り当てて、ピア グループ メンバーとしてネイバーを追加します。ピア グループを設定するには、 neighbor ルータ コンフィギュレーション コマンドを使用します。デフォルトでは、ピア グループ メンバーは remote-as(設定されている場合)、version、update-source、out-route-map、out-filter-list、out-dist-list、minimum-advertisement-interval、next-hop-self など、ピア グループの設定オプションをすべて継承します。すべてのピア グループ メンバーは、ピア グループに対する変更を継承します。また、発信アップデートに影響しないオプションを無効にするように、メンバーを設定することもできます。
各ネイバーに設定オプションを割り当てるには、ネイバーの IP アドレスを使用し、次に示すルータ コンフィギュレーション コマンドのいずれかを指定します。ピア グループにオプションを割り当てるには、ピア グループ名を使用し、いずれかのコマンドを指定します。 neighbor shutdown ルータ コンフィギュレーション コマンドを使用すると、すべての設定情報を削除せずに、BGP ピアまたはピア グループをディセーブルにできます。
BGP ピアを設定するには、特権 EXEC モードで次のコマンドを使用します。
既存の BGP ネイバーまたはネイバー ピア グループをディセーブルにするには、 neighbor shutdown ルータ コンフィギュレーション コマンドを使用します。ディセーブル化されている既存のネイバーまたはネイバー ピア グループをイネーブルにするには、 no neighbor shutdown ルータ コンフィギュレーション コマンドを使用します。
集約アドレスの設定
CIDR を使用すると、集約ルート(または スーパーネット )を作成して、ルーティング テーブルのサイズを最小化できます。BGP 内に集約ルートを設定するには、集約ルートを BGP に再配信するか、または BGP ルーティング テーブル内に集約エントリを作成します。BGP テーブル内に特定のエントリがさらに 1 つまたは複数存在する場合は、BGP テーブルに集約アドレスが追加されます。
ルーティング テーブル内に集約アドレスを作成するには、特権 EXEC モードで次のコマンドを使用します。
集約エントリを削除するには、 no aggregate-address address mask ルータ コンフィギュレーション コマンドを使用します。オプションをデフォルト値に戻すには、キーワードを指定してコマンドを使用します。
ルーティング ドメイン連合の設定
IBGP メッシュを削減する方法の 1 つは、AS を複数のサブ AS に分割して、単一の AS として認識される単一の連合にグループ化することです。各 AS は内部で完全にメッシュ化されていて、同じ連合内の他の AS との間には数本の接続があります。異なる AS 内にあるピアでは EBGP セッションが使用されますが、ルーティング情報は IBGP ピアと同様な方法で交換されます。特に、ネクスト ホップ、MED、およびローカル初期設定情報が維持されるため、すべての AS で単一の IGP を使用できます。
BGP 連合を設定するには、AS システム グループの AS 番号として機能する連合 ID を指定する必要があります。
BGP 連合を設定するには、特権 EXEC モードで次のコマンドを使用します。
|
|
|
|
|---|---|---|
bgp confederation peers autonomous-system [ autonomous-system ...] |
||
BGP ルート リフレクタの設定
BGP では、すべての IBGP スピーカーを完全メッシュ構造にする必要があります。外部ネイバーからルートを受信したルータは、そのルートをすべての内部ネイバーにアドバタイズする必要があります。ルーティング情報のループを防ぐには、すべての IBGP スピーカーを接続する必要があります。内部ネイバーは、内部ネイバーから取得されたルートを他の内部ネイバーに送信しません。
ルート リフレクタを使用すると、取得されたルートをネイバーに渡す場合に他の方法が使用されるため、すべての IBGP スピーカーを完全メッシュ構造にする必要はありません。IBGP ピアを ルート リフレクタ に設定すると、その IBGP ピアは IBGP によって取得されたルートを一連の IBGP ネイバーに送信するようになります。ルート リフレクタの内部ピアには、 クライアント ピア と 非クライアント ピア (AS 内の他のすべてのルータ)の 2 つのグループがあります。ルート リフレクタは、これらの 2 つのグループ間でルートを反映させます。ルート リフレクタおよびそのクライアント ピアは、 クラスタ を形成します。非クライアント ピアは相互に完全メッシュ構造にする必要がありますが、クライアント ピアはその必要はありません。クラスタ内のクライアントは、そのクラスタ外の IBGP スピーカーと通信しません。
アドバタイズされたルートを受信したルート リフレクタは、ネイバーに応じて、次のいずれかのアクションを実行します。
•![]() EBGP スピーカーからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。
EBGP スピーカーからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。
•![]() 非クライアント ピアからのルートをすべてのクライアントにアドバタイズします。
非クライアント ピアからのルートをすべてのクライアントにアドバタイズします。
•![]() クライアントからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。したがって、クライアントを完全メッシュ構造にする必要はありません。
クライアントからのルートをすべてのクライアントおよび非クライアント ピアにアドバタイズします。したがって、クライアントを完全メッシュ構造にする必要はありません。
通常、クライアントのクラスタにはルート リフレクタが 1 つあり、クラスタはルート リフレクタのルータ ID で識別されます。冗長性を高めて、シングル ポイントでの障害を回避するには、クラスタに複数のルート リフレクタを設定する必要があります。このように設定した場合は、ルート リフレクタが同じクラスタ内のルート リフレクタからのアップデートを認識できるように、クラスタ内のすべてのルート リフレクタに同じクラスタ ID(4 バイト)を設定する必要があります。クラスタを処理するすべてのルート リフレクタは完全メッシュ構造にし、一連の同一なクライアント ピアおよび非クライアント ピアを設定する必要があります。
ルート リフレクタおよびクライアントを設定するには、特権 EXEC モードで次のコマンドを使用します。
ルート ダンピング化の設定
ルート フラップ ダンピング化は、インターネットワーク内でフラッピング ルートの伝播を最小化するための BGP 機能です。ルートがフラッピングと見なされるのは、ルートが使用可能、使用不可能、使用可能、使用不可能のように、状態が継続的に変化する場合です。ルート ダンピング化がイネーブルの場合は、フラッピングしているルートに penalty 値が割り当てられます。ルートの累積ペナルティが設定された制限値に到達すると、ルートが稼動している場合であっても、BGP はルートのアドバタイズメントを抑制します。 再使用限度 は、ペナルティと比較される設定可能な値です。ペナルティが再使用限度より小さくなると、起動中の抑制されたルートのアドバタイズメントが再開されます。
IBGP によって取得されたルートには、ダンピング化が適用されません。このポリシーにより、IBGP ピアのペナルティが AS 外部のルートよりも大きくなることはありません。
BGP ルート ダンピング化を設定するには、特権 EXEC モードで次のコマンドを使用します。
フラップ ダンピング化をディセーブルにするには、キーワードを指定しないで no bgp dampening ルータ コンフィギュレーション コマンドを使用します。ダンピング係数をデフォルト値に戻すには、値を指定して no bgp dampening ルータ コンフィギュレーション コマンドを使用します。
BGP のモニタおよびメンテナンス
特定のキャッシュ、テーブル、またはデータベースのすべての内容を削除できます。この作業は、特定の構造の内容が無効になる場合、または無効である疑いがある場合に必要となります。
BGP ルーティング テーブル、キャッシュ、データベースの内容など、特定の統計情報を表示できます。さらに、リソースの利用率を取得したり、ネットワーク問題を解決するための情報を使用することもできます。さらに、ノードの到達可能性に関する情報を表示し、デバイスのパケットが経由するネットワーク内のルーティング パスを検出することもできます。
表 38-8 に、BGP を消去および表示するために使用する特権 EXEC コマンドを示しています。画面に表示されるフィールドについては、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 を参照してください。このマニュアルは、Cisco.com の [Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Command References] からアクセス可能です。
また、 bgp log-neighbor changes ルータ コンフィギュレーション コマンドを使用し、BGP ネイバーをリセット、起動、またはダウンさせるときに生成されるメッセージのロギングをイネーブルにすることもできます。
ISO CLNS ルーティングの設定
International Organization for Standardization(ISO; 国際標準化機構)の Connectionless Network Service(CLNS; コネクションレス型ネットワーク サービス)プロトコルは、Open System Interconnection(OSI; オープン システム インターコネクション)モデルのネットワーク層の標準です。ISO ネットワーク アーキテクチャでのアドレスは、Network Service Access Point(NSAP; ネットワーク サービス アクセス ポイント)および Network Entity Title(NET)と呼ばれます。OSI ネットワーク内の各ノードには、1 つ以上の NET が設定されています。さらに、各ノードには多数の NSAP アドレスがあります。
スイッチで clns routing グローバル コンフィギュレーション コマンドを使用してコネクションレス ルーティングをイネーブルにすると、スイッチは転送決定だけを行い、ルーティング関連の機能は実行しません。ダイナミック ルーティングの場合は、ルーティング プロトコルもイネーブルにする必要があります。スイッチは、ISO CLNS ネットワーク用の OSI ルーティング プロトコルに基づく Intermediate System-to-Intermediate System(IS-IS)ダイナミック ルーティング プロトコルをサポートします。
ダイナミックにルーティングを行うときは、IS-IS を使用します。このルーティング プロトコルは、 エリア の概念をサポートします。エリア内では、すべてのルータはすべてのシステム ID への到達方法を認識しています。エリア間では、ルータは適切なエリアへの到達方法を認識しています。IS-IS は、 ステーション ルーティング (エリア内)と エリア ルーティング (エリア間)という 2 つのレベルのルーティングをサポートします。
ISO IGRP および IS-IS NSAP のアドレス指定方式の重要な違いは、エリア アドレスの定義に関する部分です。どちらもレベル 1 のルーティング(エリア内のルーティング)にはシステム ID を使用します。一方、エリア ルーティングでのアドレスの指定方法は異なります。ISO IGRP NSAP のアドレスには、 ドメイン 、 エリア 、および システム ID という 3 つの異なるフィールドがルーティング用に含まれます。IS-IS のアドレスには、単一の連続した エリア フィールド(ドメイン フィールドとエリア フィールドを含みます)および システム ID という 2 つのフィールドが含まれます。
(注) ISO CLNS の詳細については、『Cisco IOS Apollo Domain, Banyan VINES, DECnet, ISO CLNS and XNS Configuration Guide』Release 12.2 を参照してください。この章で使用するコマンドの構文および使用方法の詳細については、『Cisco IOS Apollo Domain, Banyan VINES, DECnet, ISO CLNS and XNS Command Reference』Release 12.2 を参照するか、IOS コマンド リファレンス マスター インデックスを使用するか、オンラインで検索してください。
IS-IS ダイナミック ルーティングの設定
IS-IS は、ISO のダイナミック ルーティング プロトコルです(ISO 105890 で説明されています)。他のルーティング プロトコルとは異なり、IS-IS をイネーブルにするには、IS-IS ルーティング プロセスを作成し、それをネットワークではなく特定のインターフェイスに割り当てる必要があります。マルチエリアの IS-IS 設定構文を使用して、レイヤ 3 のスイッチまたはルータごとに複数の IS-IS ルーティング プロセスを指定できます。その場合、IS-IS ルーティング プロセスのインスタンスごとにパラメータを設定します。
小規模の IS-IS ネットワークは、ネットワーク内のすべてのルータを含む単一のエリアとして構築します。ネットワークの規模が拡大したら、通常、すべてのエリアのすべてのレベル 2 ルータを接続して構成されるバックボーン エリアとしてネットワークを再編成し、これをローカル エリアに接続します。ローカル エリア内では、ルータはすべてのシステム ID への到達方法を認識しています。エリア間では、ルータはバックボーンへの到達方法を認識し、バックボーン ルータは他のエリアへの到達方法を認識しています。
ルータは、ローカル エリア内のルーティング(ステーション ルーティング)を実行するために、レベル 1 の隣接関係を確立します。ルータは、レベル 1 エリア間のルーティング(エリア ルーティング)を実行するために、レベル 2 の隣接関係を確立します。
1 台のシスコ ルータで、最大 29 エリアのルーティングに参加し、バックボーン内のレベル 2 ルーティングを実行できます。一般に、各ルーティング プロセスはエリアに対応します。デフォルトでは、最初に設定されるルーティング プロセスのインスタンスが、レベル 1 とレベル 2 の両方のルーティングを実行します。追加のルータ インスタンスを設定でき、追加インスタンスは自動的にレベル 1 エリアとして扱われます。IS-IS ルーティング プロセスのインスタンスごとに個別にパラメータを設定する必要があります。
IS-IS マルチエリア ルーティングの場合、レベル 2 ルーティングを実行するように設定できるプロセスは 1 つだけですが、各シスコ ユニットは最大で 29 のレベル 1 エリアを定義できます。いずれかのプロセスでレベル 2 ルーティングを設定した場合、すべての追加プロセスは自動的にレベル 1 として設定されます。レベル 2 ルーティングを設定したプロセスは、同時にレベル 1 ルーティングを実行するように設定できます。レベル 2 ルーティングがルータ インスタンスに必要ない場合は、 is-type グローバル コンフィギュレーション コマンドを使用してレベル 2 機能を削除します。別のルータ インスタンスをレベル 2 ルータとして設定する場合にも、 is-type コマンドを使用します。
(注) IS-IS の詳細については、『Cisco IOS IP Configuration Guide』Release 12.2 の「IP Routing Protocols」を参照してください。ここで使用するコマンドの構文および使用方法の詳細については、『Cisco IOS IP Command Reference』Release 12.2 を参照してください。
IS-IS のデフォルト設定
表 38-12 に、IS-IS のデフォルト設定を示します。
|
|
|
|---|---|
従来型の IS-IS:ルータはレベル 1(ステーション)およびレベル 2(エリア)の両方のルータとして動作します。 マルチエリア IS-IS:IS-IS ルーティング プロセスの最初のインスタンスは、レベル 1-2 ルータです。それ以外のインスタンスはレベル 1 ルータです。 |
|
NSG 認識4 |
イネーブル レイヤ 3 スイッチでは、ハードウェアやソフトウェアの変更中に、近接する NSF 対応ルータからのパケットを転送し続けることができます。 |
ディセーブル。イネーブルにして、引数を入力しない場合は、過負荷ビットがすぐに設定されて、 no set-overload-bit コマンドを入力するまで設定状態を維持します。 |
|
NSF 認識
IPv4 に対して統合された IS-IS NSF 認識機能がサポートされています。この機能を使用することにより、NSF 認識である Customer Premises Equipment(CPE; 宅内装置)のルータは、NSF 対応のルータによるパケットの NSF を補助できます。ローカル ルータは NSF を実行しない場合もありますが、NSF を認識することで、近接する NSF 対応ルータのルーティング データベースおよびリンクステート データベースの整合性と正確さを、スイッチオーバー プロセスの間に維持できます。
この機能は自動的にイネーブルになり、設定を行う必要はありません。この機能の詳細については、次の URL の『 Integrated IS-IS Nonstop Forwarding (NSF) Awareness Feature Guide 』を参照してください。 http://www.cisco.com/en/US/products/sw/iosswrel/ps1839/products_white_paper09186a00801541c7.shtml
IS-IS ルーティングのイネーブル化
IS-IS をイネーブルにするには、ルーティング プロセスごとに名前と NET を指定します。その後、インターフェイスで IS-IS ルーティングをイネーブルにし、ルーティング プロセスの各インスタンスに対してエリアを指定します。
IS-IS をイネーブルにして、IS-IS ルーティング プロセスの各インスタンスにエリアを指定するには、特権 EXEC モードで次の手順を実行します。
IS-IS ルーティングをディセーブルにするには、 no router isis area-tag ルータ コンフィギュレーション コマンドを使用します。
次に、IP ルーティング プロトコルとして従来型の IS-IS を実行するように 3 つのルータを設定する例を示します。従来型の IS-IS では、すべてのルータが(デフォルトで)レベル 1 およびレベル 2 のルータとして動作します。
IS-IS グローバル パラメータの設定
必要に応じて設定できる IS-IS グローバル パラメータがいくつかあります。
•![]() ルート マップで制御されるデフォルト ルートを設定することで、IS-IS ルーティング ドメインにデフォルト ルートを強制的に適用できます。ルート マップで設定可能な他のフィルタリング オプションを指定することもできます。
ルート マップで制御されるデフォルト ルートを設定することで、IS-IS ルーティング ドメインにデフォルト ルートを強制的に適用できます。ルート マップで設定可能な他のフィルタリング オプションを指定することもできます。
•![]() 受信した IS-IS LSP に内部チェックサム エラーがある場合は無視するように、または壊れている LSP を削除するように、ルータを設定できます。このようにすると、LSP の発信側は LSP を再生成します。
受信した IS-IS LSP に内部チェックサム エラーがある場合は無視するように、または壊れている LSP を削除するように、ルータを設定できます。このようにすると、LSP の発信側は LSP を再生成します。
•![]() エリアおよびドメインにパスワードを割り当てることができます。
エリアおよびドメインにパスワードを割り当てることができます。
•![]() ルーティング テーブルでサマリー アドレスによって表される集約アドレスを作成できます(ルート サマライズ)。他のルーティング プロトコルから学習されたルートもサマライズできます。サマリーのアドバタイズに使用されるメトリックは、特定のルート全体の中で最小のメトリックです。
ルーティング テーブルでサマリー アドレスによって表される集約アドレスを作成できます(ルート サマライズ)。他のルーティング プロトコルから学習されたルートもサマライズできます。サマリーのアドバタイズに使用されるメトリックは、特定のルート全体の中で最小のメトリックです。
•![]() LSP リフレッシュ インターバル、および LSP がリフレッシュされないでルータのデータベースに残っていることのできる最大時間を設定できます。
LSP リフレッシュ インターバル、および LSP がリフレッシュされないでルータのデータベースに残っていることのできる最大時間を設定できます。
•![]() LSP 生成のスロットリング タイマー、SPF 計算、および PRC を設定できます。
LSP 生成のスロットリング タイマー、SPF 計算、および PRC を設定できます。
•![]() IS-IS の隣接関係のステートが(アップまたはダウンに)変化したときにログ メッセージを生成するように、スイッチを設定できます。
IS-IS の隣接関係のステートが(アップまたはダウンに)変化したときにログ メッセージを生成するように、スイッチを設定できます。
•![]() ネットワーク内のリンクの Maximum Transmission Unit(MTU; 最大伝送ユニット)のサイズが 1500 バイト未満の場合、そのような状況でもルーティングが発生するように LSP MTU を小さくすることができます。
ネットワーク内のリンクの Maximum Transmission Unit(MTU; 最大伝送ユニット)のサイズが 1500 バイト未満の場合、そのような状況でもルーティングが発生するように LSP MTU を小さくすることができます。
•![]() partition avoidance ルータ コンフィギュレーション コマンドは、レベル 1-2 境界ルータ、隣接するレベル 1 ルータ、およびエンド ホストの間の完全な接続が失われたときに、エリアが分割されるのを防ぎます。
partition avoidance ルータ コンフィギュレーション コマンドは、レベル 1-2 境界ルータ、隣接するレベル 1 ルータ、およびエンド ホストの間の完全な接続が失われたときに、エリアが分割されるのを防ぎます。
IS-IS パラメータを設定するには、特権 EXEC モードで次の手順を実行します。
デフォルト ルートの生成をディセーブルにするには、 no default-information originate ルータ コンフィギュレーション コマンドを使用します。パスワードをディセーブルにするには、 no area-password または no domain-password ルータ コンフィギュレーション コマンドを使用します。LSP MTU の設定をディセーブルにするには、 no lsp mtu ルータ コンフィギュレーション コマンドを使用します。サマリー アドレス指定、LSP リフレッシュ インターバル、LSP 存続時間、LSP タイマー、SFP タイマー、PRC タイマーをデフォルトの設定に戻すには、コマンドの no 形式を使用します。出力フォーマットをディセーブルにするには、 no partition avoidance ルータ コンフィギュレーション コマンドを使用します。
IS-IS インターフェイス パラメータの設定
必要に応じて、接続されている他のルータとは別個に、特定のインターフェイス固有の IS-IS パラメータを設定できます。ただし、係数やタイム インターバルなどの一部の値をデフォルトから変更する場合は、複数のルータおよびインターフェイスでも変更しないと意味がありません。ほとんどのインターフェイス パラメータは、レベル 1、レベル 2、または両方に対して設定できます。
設定できるインターフェイス レベル パラメータの一部を次に示します。
•![]() インターフェイスのデフォルト メトリック。IS-IS メトリックの値として使用され、Quality of Service(QoS)ルーティングが実行されていないときに割り当てられます。
インターフェイスのデフォルト メトリック。IS-IS メトリックの値として使用され、Quality of Service(QoS)ルーティングが実行されていないときに割り当てられます。
•![]() hello インターバル(インターフェイスで送信される hello パケット間の時間の長さ)、または IS-IS hello パケットで送信されるホールド タイムを決定するためにインターフェイスで使用されるデフォルトの hello パケット係数。ホールド タイムにより、ネイバーがネイバー ダウンを宣言する前に別の hello パケットを待機する時間の長さが決定されます。これにより、障害リンクまたはネイバーが検出されてルートを再計算できるまでの時間が決まります。hello パケットが頻繁に失われて、IS-IS 隣接関係の障害が必要以上に発生する環境では、hello 係数を変更してください。hello 係数を大きくし、それに対応して hello インターバルを小さくすることで、リンク障害の検出に必要な時間を延ばすことなく、hello プロトコルの信頼性を高めることができます。
hello インターバル(インターフェイスで送信される hello パケット間の時間の長さ)、または IS-IS hello パケットで送信されるホールド タイムを決定するためにインターフェイスで使用されるデフォルトの hello パケット係数。ホールド タイムにより、ネイバーがネイバー ダウンを宣言する前に別の hello パケットを待機する時間の長さが決定されます。これにより、障害リンクまたはネイバーが検出されてルートを再計算できるまでの時間が決まります。hello パケットが頻繁に失われて、IS-IS 隣接関係の障害が必要以上に発生する環境では、hello 係数を変更してください。hello 係数を大きくし、それに対応して hello インターバルを小さくすることで、リンク障害の検出に必要な時間を延ばすことなく、hello プロトコルの信頼性を高めることができます。
–![]() Complete Sequence Number PDU(CSNP)インターバル。CSNP は、データベースの同期を維持するために指定されているルータによって送信されます。
Complete Sequence Number PDU(CSNP)インターバル。CSNP は、データベースの同期を維持するために指定されているルータによって送信されます。
–![]() 再送信インターバル。ポイントツーポイント リンクに対する IS-IS LSP の再送信間の時間です。
再送信インターバル。ポイントツーポイント リンクに対する IS-IS LSP の再送信間の時間です。
–![]() IS-IS LSP 再送信スロットル インターバル。ポイントツーポイント リンクで IS-IS LSP が再送信される最大速度(パケット間のミリ秒数)です。このインターバルは、同じ LSP の連続する再送信の間の時間である再送信インターバルとは異なります。
IS-IS LSP 再送信スロットル インターバル。ポイントツーポイント リンクで IS-IS LSP が再送信される最大速度(パケット間のミリ秒数)です。このインターバルは、同じ LSP の連続する再送信の間の時間である再送信インターバルとは異なります。
•![]() 代表ルータ選出プライオリティ。マルチアクセス ネットワークで必要な隣接関係の数を減らすことができます。その結果、ルーティング プロトコル トラフィックの量およびトポロジ データベースのサイズが減ります。
代表ルータ選出プライオリティ。マルチアクセス ネットワークで必要な隣接関係の数を減らすことができます。その結果、ルーティング プロトコル トラフィックの量およびトポロジ データベースのサイズが減ります。
•![]() インターフェイス回線タイプ。指定したインターフェイス上のネイバーに適した隣接関係のタイプです。
インターフェイス回線タイプ。指定したインターフェイス上のネイバーに適した隣接関係のタイプです。
IS-IS インターフェイス パラメータを設定にするには、特権 EXEC モードで次の手順を実行します。
ISO IGRP と IS-IS のモニタおよびメンテナンス
CLNS キャッシュのすべての内容を削除したり、特定のネイバーまたはルートの情報を削除したりできます。ルーティング テーブル、キャッシュ、データベースの内容など、CLNS または IS-IS の特定の統計情報を表示できます。また、特定のインターフェイス、フィルタ、またはネイバーについての情報も表示できます。
表 38-13 に、ISO CLNS と IS-IS ルーティングを消去および表示するために使用する特権 EXEC コマンドを示します。表示フィールドの詳細については、『 Cisco IOS Apollo Domain, Banyan VINES, DECnet, ISO CLNS and XNS Command Reference 』Release 12.2 を参照するか、Cisco IOS コマンド リファレンス マスター インデックスを使用するか、オンラインで検索してください。
|
|
|
|---|---|
このルータの各 IS-IS または ISO IGRP ルーティング プロセスに対するプロトコル固有の情報を一覧表示します。 |
|
マルチ VRF CE の設定
Virtual Private Network(VPN; バーチャル プライベート ネットワーク)は、ISP バックボーン ネットワーク上でお客様にセキュアな帯域幅共有を提供します。VPN は、共通ルーティング テーブルを共有するサイトの集合です。カスタマー サイトは、1 つまたは複数のインターフェイスでサービス プロバイダー ネットワークに接続され、サービス プロバイダーは、VPN Routing/Forwarding(VRF)テーブルと呼ばれる VPN ルーティング テーブルと各インターフェイスを関連付けます。
Catalyst 3750 スイッチは、スイッチで IP サービス イメージが稼動中の場合に、Customer Edge(CE; カスタマー エッジ)デバイスの multiple VPN Routing/Forwarding(multi-VRF; マルチ VRF)インスタンスをサポートします(マルチ VRF CE)。サービス プロバイダーは、マルチ VRF CE により、重複する IP アドレスで複数の VPN をサポートできます。IP ベース イメージが稼動しているスイッチでこれを設定しようとすると、エラー メッセージが表示されます。IP ベース イメージが稼動しているスイッチで、マルチ VRF CE と EIGRP スタブ ルーティングを同時に設定することは許可されていません。
(注) スイッチでは、VPN のサポートのために Multiprotocol Label Switching(MPLS; マルチプロトコル ラベル スイッチング)が使用されません。MPLS VRF に関する詳細については、『Cisco IOS Switching Services Configuration Guide』Release 12.2 を参照してください。これには、Cisco.com のホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Command References])からアクセス可能です。
マルチ VRF CE の概要
マルチ VRF CE は、サービス プロバイダーが複数の VPN をサポートし、VPN 間で IP アドレスを重複して使用できるようにする機能です。マルチ VRF CE は入力インターフェイスを使用して、さまざまな VPN のルートを区別し、1 つまたは複数のレイヤ 3 インターフェイスと各 VRF を関連付けて仮想パケット転送テーブルを形成します。VRF 内のインターフェイスは、イーサネット ポートのように物理的なもの、または VLAN SVI のように論理的なものにもできますが、複数の VRF に属すことはできません。
(注) マルチ VRF CE インターフェイスは、レイヤ 3 インターフェイスである必要があります。
•![]() お客様は、CE デバイスにより、1 つまたは複数の Provider Edge(PE; プロバイダー エッジ)ルータへのデータ リンクを介してサービス プロバイダー ネットワークにアクセスできます。CE デバイスは、サイトのローカル ルートをルータにアドバタイズし、リモート VPN ルートをそこから学習します。Catalyst 3750 スイッチは、CE にすることができます。
お客様は、CE デバイスにより、1 つまたは複数の Provider Edge(PE; プロバイダー エッジ)ルータへのデータ リンクを介してサービス プロバイダー ネットワークにアクセスできます。CE デバイスは、サイトのローカル ルートをルータにアドバタイズし、リモート VPN ルートをそこから学習します。Catalyst 3750 スイッチは、CE にすることができます。
•![]() PE ルータは、スタティック ルーティング、または BGP、RIPv2、OSPF、EIGRP などのルーティング プロトコルを使用して、CE デバイスとルーティング情報を交換します。PE では、直接接続している VPN の VPN ルートだけを維持すればよく、すべてのサービス プロバイダー VPN ルートを維持する必要はありません。各 PE ルータは、直接接続しているサイトごとに VRF を維持します。すべてのサイトが同じ VPN に存在する場合は、PE ルータの複数のインターフェイスを 1 つの VRF に関連付けることができます。各 VPN は、指定された VRF にマッピングされます。PE ルータは、ローカル VPN ルートを CE から学習したあとで、IBGP を使用して別の PE ルータと VPN ルーティング情報を交換します。
PE ルータは、スタティック ルーティング、または BGP、RIPv2、OSPF、EIGRP などのルーティング プロトコルを使用して、CE デバイスとルーティング情報を交換します。PE では、直接接続している VPN の VPN ルートだけを維持すればよく、すべてのサービス プロバイダー VPN ルートを維持する必要はありません。各 PE ルータは、直接接続しているサイトごとに VRF を維持します。すべてのサイトが同じ VPN に存在する場合は、PE ルータの複数のインターフェイスを 1 つの VRF に関連付けることができます。各 VPN は、指定された VRF にマッピングされます。PE ルータは、ローカル VPN ルートを CE から学習したあとで、IBGP を使用して別の PE ルータと VPN ルーティング情報を交換します。
•![]() CE デバイスに接続していないサービス プロバイダー ネットワークのルータは、プロバイダー ルータやコア ルータになります。
CE デバイスに接続していないサービス プロバイダー ネットワークのルータは、プロバイダー ルータやコア ルータになります。
マルチ VRF CE では、複数のお客様が 1 つの CE を共有でき、CE と PE の間で 1 つの物理リンクだけが使用されます。共有 CE は、お客様ごとに別々の VRF テーブルを維持し、独自のルーティング テーブルに基づいて、お客様ごとにパケットをスイッチングまたはルーティングします。マルチ VRF CE は、制限付きの PE 機能を CE デバイスに拡張して、別々の VRF テーブルを維持し、VPN のプライバシーおよびセキュリティを支店に拡張します。
図 38-6 は、Catalyst 3750 スイッチを複数の仮想 CE として使用した設定を示しています。このシナリオは、中小企業など、VPN サービスの帯域幅要件の低いお客様に適しています。そのような場合、Catalyst 3750 スイッチではマルチ VRF CE のサポートが必要です。マルチ VRF CE はレイヤ 3 機能なので、VRF のそれぞれのインターフェイスはレイヤ 3 インターフェイスである必要があります。

CE スイッチは、レイヤ 3 インターフェイスを VRF に追加するコマンドを受信すると、マルチ VRF CE 関連のデータ構造で VLAN ID と Policy Label(PL; ポリシー ラベル)の間に適切なマッピングを設定し、VLAN ID と PL を VLAN データベースに追加します。
マルチ VRF CE を設定すると、レイヤ 3 転送テーブルは、次の 2 つのセクションに概念的に分割されます。
•![]() マルチ VRF CE ルーティング セクションには、さまざまな VPN からのルートが含まれます。
マルチ VRF CE ルーティング セクションには、さまざまな VPN からのルートが含まれます。
•![]() グローバル ルーティング セクションには、インターネットなど、VPN 以外のネットワークへのルートが含まれます。
グローバル ルーティング セクションには、インターネットなど、VPN 以外のネットワークへのルートが含まれます。
さまざまな VRF の VLAN ID はさまざまなポリシー ラベルにマッピングされ、処理中に VRF を区別するために使用されます。レイヤ 3 設定機能では、学習した新しい VPN ルートごとに、入力ポートの VLAN ID を使用してポリシー ラベルを取得し、マルチ VRF CE ルーティング セクションにポリシー ラベルおよび新しいルートを挿入します。ルーテッド ポートからパケットを受信した場合は、ポート内部 VLAN ID 番号が使用されます。SVI からパケットを受信した場合は、VLAN 番号が使用されます。
マルチ VRF CE 対応ネットワークのパケット転送処理は次のとおりです。
•![]() スイッチは、VPN からパケットを受信すると、入力ポリシー ラベル番号に基づいてルーティング テーブルを検索します。ルートが見つかると、スイッチはパケットを PE に転送します。
スイッチは、VPN からパケットを受信すると、入力ポリシー ラベル番号に基づいてルーティング テーブルを検索します。ルートが見つかると、スイッチはパケットを PE に転送します。
•![]() 入力 PE は、CE からパケットを受信すると、VRF 検索を実行します。ルートが見つかると、ルータは対応する MPLS ラベルをパケットに追加し、MPLS ネットワークに送信します。
入力 PE は、CE からパケットを受信すると、VRF 検索を実行します。ルートが見つかると、ルータは対応する MPLS ラベルをパケットに追加し、MPLS ネットワークに送信します。
•![]() 出力 PE は、ネットワークからパケットを受信すると、ラベルを除去してそのラベルを使用し、正しい VPN ルーティング テーブルを識別します。次に、通常のルート検索を実行します。ルートが見つかると、パケットを正しい隣接デバイスに転送します。
出力 PE は、ネットワークからパケットを受信すると、ラベルを除去してそのラベルを使用し、正しい VPN ルーティング テーブルを識別します。次に、通常のルート検索を実行します。ルートが見つかると、パケットを正しい隣接デバイスに転送します。
•![]() CE は、出力 PE からパケットを受信すると、入力ポリシー ラベルを使用して正しい VPN ルーティング テーブルを検索します。ルートが見つかると、パケットを VPN 内で転送します。
CE は、出力 PE からパケットを受信すると、入力ポリシー ラベルを使用して正しい VPN ルーティング テーブルを検索します。ルートが見つかると、パケットを VPN 内で転送します。
VRF を設定するには、VRF テーブルを作成し、VRF に関連するレイヤ 3 インターフェイスを指定します。次に、VPN、および CE と PE 間でルーティング プロトコルを設定します。プロバイダーのバックボーンで VPN ルーティング情報を配信する場合は、BGP が望ましいルーティング プロトコルです。マルチ VRF CE ネットワークには、次の 3 つの主要コンポーネントがあります。
•![]() VPN ルート ターゲット コミュニティ:VPN コミュニティのその他すべてのメンバーのリスト。VPN コミュニティ メンバーごとに VPN ルート ターゲットを設定する必要があります。
VPN ルート ターゲット コミュニティ:VPN コミュニティのその他すべてのメンバーのリスト。VPN コミュニティ メンバーごとに VPN ルート ターゲットを設定する必要があります。
•![]() VPN コミュニティ PE ルータのマルチプロトコル BGP ピアリング:VPN コミュニティのすべてのメンバーに VRF 到達可能性情報を伝播します。VPN コミュニティのすべての PE ルータで BGP ピアリングを設定する必要があります。
VPN コミュニティ PE ルータのマルチプロトコル BGP ピアリング:VPN コミュニティのすべてのメンバーに VRF 到達可能性情報を伝播します。VPN コミュニティのすべての PE ルータで BGP ピアリングを設定する必要があります。
•![]() VPN 転送:VPN サービス プロバイダー ネットワークを介し、全 VPN コミュニティ メンバー間で、全トラフィックを伝送します。
VPN 転送:VPN サービス プロバイダー ネットワークを介し、全 VPN コミュニティ メンバー間で、全トラフィックを伝送します。
マルチ VRF CE のデフォルト設定
表 38-14 に、VRF のデフォルト設定を示します。
|
|
|
|---|---|
マルチ VRF CE の設定時の注意事項
(注) マルチ VRF CE を使用するには、IP サービス イメージをスイッチにインストールする必要があります。
ネットワークに VRF を設定する場合は、次のことに注意してください。
•![]() マルチ VRF CE を含むスイッチは複数のお客様によって共有され、各お客様には独自のルーティング テーブルがあります。
マルチ VRF CE を含むスイッチは複数のお客様によって共有され、各お客様には独自のルーティング テーブルがあります。
•![]() お客様は別々の VRF テーブルを使用するので、同じ IP アドレスを再利用できます。別々の VPN では IP アドレスの重複が許可されます。
お客様は別々の VRF テーブルを使用するので、同じ IP アドレスを再利用できます。別々の VPN では IP アドレスの重複が許可されます。
•![]() マルチ VRF CE では、複数のお客様が、PE と CE の間で同じ物理リンクを共有できます。複数の VLAN を持つトランク ポートでは、パケットがお客様間で分離されます。それぞれのお客様には独自の VLAN があります。
マルチ VRF CE では、複数のお客様が、PE と CE の間で同じ物理リンクを共有できます。複数の VLAN を持つトランク ポートでは、パケットがお客様間で分離されます。それぞれのお客様には独自の VLAN があります。
•![]() マルチ VRF CE ではサポートされない MPLS-VRF 機能があります。ラベル交換、LDP 隣接関係、ラベル付きパケットはサポートされません。
マルチ VRF CE ではサポートされない MPLS-VRF 機能があります。ラベル交換、LDP 隣接関係、ラベル付きパケットはサポートされません。
•![]() PE ルータの場合、マルチ VRF CE の使用と複数の CE の使用に違いはありません。図 38-6 では、複数の仮想レイヤ 3 インターフェイスがマルチ VRF CE デバイスに接続されています。
PE ルータの場合、マルチ VRF CE の使用と複数の CE の使用に違いはありません。図 38-6 では、複数の仮想レイヤ 3 インターフェイスがマルチ VRF CE デバイスに接続されています。
•![]() スイッチでは、物理ポートか VLAN SVI、またはその両方の組み合わせを使用して、VRF を設定できます。SVI は、アクセス ポートまたはトランク ポートで接続できます。
スイッチでは、物理ポートか VLAN SVI、またはその両方の組み合わせを使用して、VRF を設定できます。SVI は、アクセス ポートまたはトランク ポートで接続できます。
•![]() お客様は、別のお客様と重複しないかぎり、複数の VLAN を使用できます。お客様の VLAN は、スイッチに保存されている適切なルーティング テーブルの識別に使用される特定のルーティング テーブル ID にマッピングされます。
お客様は、別のお客様と重複しないかぎり、複数の VLAN を使用できます。お客様の VLAN は、スイッチに保存されている適切なルーティング テーブルの識別に使用される特定のルーティング テーブル ID にマッピングされます。
•![]() Catalyst 3750 スイッチは、1 つのグローバル ネットワークおよび最大 26 の VRF をサポートします。
Catalyst 3750 スイッチは、1 つのグローバル ネットワークおよび最大 26 の VRF をサポートします。
•![]() CE と PE の間では、ほとんどのルーティング プロトコル(BGP、OSPF、RIP、およびスタティック ルーティング)を使用できます。ただし、次の理由から External BGP(EBGP)を使用することを推奨します。
CE と PE の間では、ほとんどのルーティング プロトコル(BGP、OSPF、RIP、およびスタティック ルーティング)を使用できます。ただし、次の理由から External BGP(EBGP)を使用することを推奨します。
–![]() BGP では、複数の CE とのやり取りに複数のアルゴリズムを必要としません。
BGP では、複数の CE とのやり取りに複数のアルゴリズムを必要としません。
–![]() BGP は、さまざまな管理者によって稼動するシステム間でルーティング情報を渡すように設計されています。
BGP は、さまざまな管理者によって稼動するシステム間でルーティング情報を渡すように設計されています。
–![]() BGP では、ルートのアトリビュートを CE に簡単に渡すことができます。
BGP では、ルートのアトリビュートを CE に簡単に渡すことができます。
•![]() マルチ VRF CE は、パケットのスイッチング レートに影響しません。
マルチ VRF CE は、パケットのスイッチング レートに影響しません。
•![]() マルチ VRF CE 内のラインレート マルチキャスト転送をサポートしています。
マルチ VRF CE 内のラインレート マルチキャスト転送をサポートしています。
•![]() マルチキャスト VRF は、同一インターフェイス上でプライベート VLAN と共存することができません。
マルチキャスト VRF は、同一インターフェイス上でプライベート VLAN と共存することができません。
•![]() 最大 1000 のマルチキャスト ルータがサポートされていて、すべての VRF で共有可能です。
最大 1000 のマルチキャスト ルータがサポートされていて、すべての VRF で共有可能です。
•![]() VRF を設定しない場合は、105 のポリシーを設定できます。
VRF を設定しない場合は、105 のポリシーを設定できます。
•![]() VRF を 1 つでも設定する場合は、41 のポリシーを設定できます。
VRF を 1 つでも設定する場合は、41 のポリシーを設定できます。
•![]() 41 より多いポリシーを設定する場合は、VRF を設定できません。
41 より多いポリシーを設定する場合は、VRF を設定できません。
•![]() VRF とプライベート VLAN は相互に排他的です。プライベート VLAN では VRF をイネーブルにすることはできません。同じように、VLAN インターフェイスで VRF が設定されている VLAN では、プライベート VLAN をイネーブルにはできません。
VRF とプライベート VLAN は相互に排他的です。プライベート VLAN では VRF をイネーブルにすることはできません。同じように、VLAN インターフェイスで VRF が設定されている VLAN では、プライベート VLAN をイネーブルにはできません。
•![]() VRF と Policy-Based Routing(PBR; ポリシーベース ルーティング)は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスでイネーブルになっているときは、VRF をイネーブルにすることはできません。同じように、インターフェイスで VRF がイネーブルになっているときは、PBR をイネーブルにはできません。
VRF と Policy-Based Routing(PBR; ポリシーベース ルーティング)は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスでイネーブルになっているときは、VRF をイネーブルにすることはできません。同じように、インターフェイスで VRF がイネーブルになっているときは、PBR をイネーブルにはできません。
•![]() VRF と Web Cache Communication Protocol(WCCP)は、スイッチ インターフェイス上で相互に排他的です。インターフェイスで WCCP がイネーブルになっているときは、VRF をイネーブルにすることはできません。同じように、インターフェイスで VRF がイネーブルになっているときは、WCCP をイネーブルにはできません。
VRF と Web Cache Communication Protocol(WCCP)は、スイッチ インターフェイス上で相互に排他的です。インターフェイスで WCCP がイネーブルになっているときは、VRF をイネーブルにすることはできません。同じように、インターフェイスで VRF がイネーブルになっているときは、WCCP をイネーブルにはできません。
VRF の設定
1 つまたは複数の VRF を設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
VRF を削除してすべてのインターフェイスを削除するには、 no ip vrf vrf-name グローバル コンフィギュレーション コマンドを使用します。VRF からあるインターフェイスを削除するには、 no ip vrf forwarding インターフェイス コンフィギュレーション コマンドを使用します。
マルチキャスト VRF の設定
VRF テーブル内にマルチキャストを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの構文と使用方法の詳細については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
マルチキャスト VRF CE 内でのマルチキャストの設定に関する詳細については、『Cisco IOS IP Configuration Guide』Release 12.4 を参照してください。
VRF 認識サービスの設定
IP サービスはグローバル インターフェイス上に設定することが可能で、これらのサービスをグローバル ルーティング インスタンス内で実行することができます。IP サービスは、複数のルーティング インスタンスで実行されるように拡張されていて、これが VRF 認識です。システム内に設定された VRF は、VRF 認識サービス用に指定できます。
VRF 認識サービスは、プラットフォームから独立したモジュールに実装されています。VRF とは、Cisco IOS で複数のルーティング インスタンスのことです。各プラットフォームには独自のサポート VRF 数の制限があります。
•![]() ユーザは、ユーザ指定の VRF 内のホストに ping を実行することができます。
ユーザは、ユーザ指定の VRF 内のホストに ping を実行することができます。
•![]() ARP エントリは個別の VRF で学習されます。ユーザは、特定の VRF の ARP アドレス解決プロトコル)エントリを表示することができます。
ARP エントリは個別の VRF で学習されます。ユーザは、特定の VRF の ARP アドレス解決プロトコル)エントリを表示することができます。
•![]() Simple Network Management Protocol(SNMP; 簡易ネットワーク管理プロトコル)
Simple Network Management Protocol(SNMP; 簡易ネットワーク管理プロトコル)
•![]() Hot Standby Router Protocol(HSRP; ホットスタンバイ ルータ プロトコル)
Hot Standby Router Protocol(HSRP; ホットスタンバイ ルータ プロトコル)
(注) VRF 認識サービスは Unicast Reverse Path Forwarding(uRPF; ユニキャスト RPF)をサポートしません。
ARP のユーザ インターフェイス
ARP の VRF 認識サービスを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
|
|
|
|
ping のユーザ インターフェイス
ping の VRF 認識サービスを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
|
|
|
|
|---|---|---|
SNMP のユーザ インターフェイス
SNMP の VRF 認識サービスを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
HSRP のユーザ インターフェイス
VRF の HSRP サポートにより、HSRP 仮想 IP アドレスが確実に正しい IP ルーティング テーブルに追加されます。
HSRP の VRF 認識サービスを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
|
|
|
|
|---|---|---|
Syslog のユーザ インターフェイス
Syslog の VRF 認識サービスを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
|
|
|
|
|---|---|---|
traceroute のユーザ インターフェイス
traceroute の VRF 認識サービスを設定するには、特権 EXEC モードで次の手順を実行します。コマンドの完全な構文と使用方法については、このリリースのスイッチのコマンド リファレンス、および『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
|
|
|
|
|---|---|---|
FTP および TFTP のユーザ インターフェイス
FTP と TFTP が VRF 認識とするためには、いくつかの FTP/TFTP CLI を設定する必要があります。たとえば、インターフェイスに添付されている VRF テーブルを使用する場合、E1/0 であれば、CLI ip [t]ftp source-interface E1/0 を設定して、特定のルーティング テーブルを使用するように [t]ftp に通知します。この例では、VRF テーブルが宛先 IP アドレスを検索するために使用されます。これらの変更には下位互換性があり、既存の動作には影響しません。つまり、VRF がそのインターフェイスに設定されていなくても、送信元インターフェイス CLI を使用してパケットを特定のインターフェイスに送信することができます。
FTP 接続の IP アドレスを指定するには、ip ftp source-interface show mode コマンドを使用します。接続が行われているインターフェイスのアドレスを使用するには、no 形式のコマンドを使用します。
|
|
|
|
|---|---|---|
TFTP 接続の送信元アドレスとしてインターフェイスの IP アドレスを指定するには、ip tftp source-interface show mode コマンドを使用します。デフォルトに戻るには、no 形式のコマンドを使用します。
|
|
|
|
|---|---|---|
VPN ルーティング セッションの設定
VPN 内のルーティングは、サポートされている任意のルーティング プロトコル(RIP、OSPF、EIGRP、BGP)、またはスタティック ルーティングで設定できます。ここで説明する設定は OSPF のものですが、その他のプロトコルでも手順は同じです。
(注) VRF インスタンス内で稼動するように EIGRP ルーティング プロセスを設定するには、autonomous-system autonomous-system-number アドレスファミリ コンフィギュレーション モード コマンドを入力して AS 番号を設定する必要があります。
VPN 内で OSPF を設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
OSPF ルーティングをイネーブルにして VPN 転送テーブルを指定し、ルータ コンフィギュレーション モードを開始します。 |
||
VPN 転送テーブルと OSPF ルーティング プロセスの関連付けを解除するには、 no router ospf process-id vrf vrf-name グローバル コンフィギュレーション コマンドを使用します。
BGP PE/CE ルーティング セッションの設定
BGP PE/CE ルーティング セッションを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
その他の BGP ルータに AS 番号を渡す BGP ルーティング プロセスを設定し、ルータ コンフィギュレーション モードを開始します。 |
||
BGP ルーティング プロセスを削除するには、 no router bgp autonomous-system-number グローバル コンフィギュレーション コマンドを使用します。ルーティング特性を削除するには、コマンドにキーワードを指定してこのコマンドを使用します。
マルチ VRF CE の設定例
図 38-7 は、図 38-6 と同じネットワークの物理接続を簡素化した例です。VPN1、VPN2、およびグローバル ネットワークで使用されるプロトコルは OSPF です。CE/PE 接続には BGP が使用されます。図のあとに続く出力は、Catalyst 3750 スイッチを CE スイッチ A として設定する例、およびカスタマー スイッチ D と F の VRF 設定を示しています。CE スイッチ C とその他のカスタマー スイッチを設定するコマンドは含まれていませんが、内容は同じです。この例には、PE ルータとして動作する Catalyst 6000 スイッチまたは Catalyst 6500 スイッチのスイッチ A へのトラフィックを設定するコマンドも含まれています。

スイッチ A の設定
スイッチ A では、ルーティングをイネーブルにして VRF を設定します。
スイッチ A のループバックおよび物理インターフェイスを設定します。ギガビット イーサネット ポート 1 は PE へのトランク接続です。ファスト イーサネット ポート 8 と 11 は VPN に接続されます。
スイッチ A で使用する VLAN を設定します。VLAN 10 は、CE と PE 間の VRF 11 によって使用されます。VLAN 20 は、CE と PE 間の VRF 12 によって使用されます。VLAN 118 と 208 は、それぞれスイッチ F とスイッチ D を含む VPN に使用されます。
VPN1 と VPN2 で OSPF ルーティングを設定します。
スイッチ D の設定
スイッチ D は VPN 1 に属します。次のコマンドを使用して、スイッチ A への接続を設定します。
スイッチ F の設定
スイッチ F は VPN 2 に属します。次のコマンドを使用して、スイッチ A への接続を設定します。
PE スイッチ B の設定
このコマンドをスイッチ B(PE ルータ)で使用すると、CE デバイス、スイッチ A に対する接続だけが設定されます。
マルチ VRF CE ステータスの表示
マルチ VRF CE の設定とステータスに関する情報を表示するには、 表 38-15 の特権 EXEC コマンドを使用します。
|
|
|
|---|---|
show ip route vrf vrf-name [ connected ] [ protocol [ as-number ]] [ list ] [ mobile ] [ odr ] [ profile ] [ static ] [ summary ] [ supernets-only ] |
|
表示される情報の詳細については、『 Cisco IOS Switching Services Command Reference 』Release 12.2 を参照してください。
プロトコル独立機能の設定
ここでは、IP ルーティング プロトコルに依存しない機能の設定方法について説明します。これらの機能は、IP ベース イメージまたは IP サービス イメージが稼動するスイッチ上で使用できますが、IP ベース イメ[ジ付属のプロトコル関連機能は RIP だけで使用できます。この章の IP ルーティング プロトコル独立コマンドの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 の「IP Routing Protocol-Independent Commands」の章を参照してください。このマニュアルには、Cisco.com ホームページ([Documentation] > [Cisco IOS Software] > [12.2 Mainline] > [Command References])からアクセスできます。
•![]() 「認証鍵の管理」
「認証鍵の管理」
dCEF の設定
Cisco Express Forwarding(CEF)は、ネットワーク パフォーマンスを最適化するために使用されるレイヤ 3 IP スイッチング技術です。CEF には高度な IP 検索および転送アルゴリズムが実装されているため、レイヤ 3 スイッチングのパフォーマンスを最大化できます。高速スイッチング ルート キャッシュよりも CPU にかかる負担が少ないため、CEF はより多くの CPU 処理能力をパケット転送に振り分けることができます。Catalyst 3750 スイッチ スタックでは、ハードウェアはスタックの dCEF を使用します。動的なネットワークでは、ルーティングの変更によって、高速スイッチング キャッシュ エントリが頻繁に無効となります。高速スイッチング キャッシュ エントリが無効になると、トラフィックがルート キャッシュによって高速スイッチングされずに、ルーティング テーブルによってプロセス スイッチングされることがあります。CEF および dCEF は Forwarding Information Base(FIB; 転送情報ベース)検索テーブルを使用して、宛先ベースの IP パケット スイッチングを実行します。
dCEF の 2 つの主要な構成要素は、分散 FIB と分散隣接テーブルです。
•![]() FIB はルーティング テーブルや情報ベースと同様、IP ルーティング テーブルに転送情報のミラー イメージが保持されます。ネットワーク内でルーティングまたはトポロジが変更されると、IP ルーティング テーブルがアップデートされ、これらの変更が FIB に反映されます。FIB には、IP ルーティング テーブル内の情報に基づいて、ネクスト ホップのアドレス情報が保持されます。FIB にはルーティング テーブル内の既知のルートがすべて格納されているため、CEF はルート キャッシュをメンテナンスする必要がなく、トラフィックのスイッチングがより効率化され、トラフィック パターンの影響も受けません。
FIB はルーティング テーブルや情報ベースと同様、IP ルーティング テーブルに転送情報のミラー イメージが保持されます。ネットワーク内でルーティングまたはトポロジが変更されると、IP ルーティング テーブルがアップデートされ、これらの変更が FIB に反映されます。FIB には、IP ルーティング テーブル内の情報に基づいて、ネクスト ホップのアドレス情報が保持されます。FIB にはルーティング テーブル内の既知のルートがすべて格納されているため、CEF はルート キャッシュをメンテナンスする必要がなく、トラフィックのスイッチングがより効率化され、トラフィック パターンの影響も受けません。
•![]() リンク レイヤ上でネットワーク内のノードが 1 ホップで相互に到達可能な場合、これらのノードは隣接関係にあると見なされます。CEF は隣接テーブルを使用し、レイヤ 2 アドレッシング情報を付加します。隣接テーブルには、すべての FIB エントリに対する、レイヤ 2 のネクスト ホップのアドレスが保持されます。
リンク レイヤ上でネットワーク内のノードが 1 ホップで相互に到達可能な場合、これらのノードは隣接関係にあると見なされます。CEF は隣接テーブルを使用し、レイヤ 2 アドレッシング情報を付加します。隣接テーブルには、すべての FIB エントリに対する、レイヤ 2 のネクスト ホップのアドレスが保持されます。
スイッチ スタックは、ギガビット速度の回線レート IP トラフィックを達成するため Application Specific Integrated Circuit(ASIC; 特定用途向け IC)を使用しているので、dCEF 転送はソフトウェア転送パス(CPU により転送されるトラフィック)にだけ適用されます。
デフォルトで、dCEF はグローバルでイネーブルに設定されています。何らかの理由でこれがディセーブルになった場合は、 ip cef distributed グローバル コンフィギュレーション コマンドを使用し、再度イネーブルに設定できます。
デフォルト設定では、すべてのレイヤ 3 インターフェイスで dCEF がイネーブルです。 no ip route-cache cef インターフェイス コンフィギュレーション コマンドを入力すると、ソフトウェアが転送するトラフィックに対して CEF がディセーブルになります。このコマンドは、ハードウェア転送パスには影響しません。CEF をディセーブルにして debug ip packet detail 特権 EXEC コマンドを使用すると、ソフトウェア転送トラフィックをデバッグするのに便利です。ソフトウェア転送パス用のインターフェイスで CEF をイネーブルにするには、 ip route-cache cef インターフェイス コンフィギュレーション コマンドを使用します。
ディセーブルである dCEF をグローバルにイネーブルにしたり、ソフトウェア転送トラフィックのインターフェイス上でイネーブルにするには、特権 EXEC モードで、次の手順を実行します。
|
|
|
|
|---|---|---|
スタック内のすべてのスイッチ、または指定されたスイッチに対して、スタック メンバー別に CEF 関連インターフェイス情報を表示します。 |
||
等価コスト ルーティング パスの個数の設定
同じネットワークへ向かう同じメトリックのルートが複数ルータに格納されている場合、これらのルートは等価コストを保有していると見なされます。ルーティング テーブルに複数の等価コスト ルートが含まれる場合は、これらを パラレル パス と呼ぶこともあります。ネットワークへの等価コスト パスがルータに複数格納されている場合、ルータはこれらを同時に使用できます。パラレル パスを使用すると、パスに障害が発生した場合に冗長性を確保できます。また、使用可能なパスにパケットの負荷を分散し、使用可能な帯域幅を有効利用することもできます。等価コスト ルートは、スタック内の各スイッチでサポートされます。
等価コスト ルートはルータによって自動的に取得、設定されますが、ルーティング テーブルの IP ルーティング プロトコルでサポートされるパラレル パスの最大数は制御可能です。スイッチ ソフトウェアでは最大 32 の等価コスト ルーティングが許可されていますが、スイッチ ハードウェアはルートあたり 17 パス以上は使用しません。
ルーティング テーブルに格納されるパラレル パスのデフォルトの最大数を変更するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
プロトコル ルーティング テーブルのパラレル パスの最大数を設定します。指定できる範囲は 1 ~ 16 です。ほとんどの IP ルーティング プロトコルでデフォルトは 4 ですが、BGP の場合は 1 です。 |
||
スタティック ユニキャスト ルートの設定
スタティック ユニキャスト ルートは、特定のパスを通過して送信元と宛先間でパケットを送受信するユーザ定義のルートです。ルータが特定の宛先へのルートを構築できない場合、スタティック ルートは重要で、到達不能なすべてのパケットが送信される最終ゲートウェイを指定する場合に有効です。
スタティック ルートを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
スタティック ルートを削除するには、 no ip route prefix mask { address | interface } グローバル コンフィギュレーション コマンドを使用します。
ユーザによって削除されるまで、スタティック ルートはスイッチに保持されます。ただし、管理距離の値を割り当て、スタティック ルートをダイナミック ルーティング情報で上書きできます。各ダイナミック ルーティング プロトコルには、デフォルトの管理距離が設定されています( 表 38-16 を参照)。ダイナミック ルーティング プロトコルの情報でスタティック ルートを上書きする場合は、スタティック ルートの管理距離がダイナミック プロトコルの管理距離よりも大きな値になるように設定します。
|
|
|
|---|---|
インターフェイスを指し示すスタティック ルートは、RIP、IGRP、およびその他のダイナミック ルーティング プロトコルを通してアドバタイズされます。 redistribute スタティック ルータ コンフィギュレーション コマンドが、これらのルーティング プロトコルに対して指定されているかどうかは関係ありません。これらのスタティック ルートがアドバタイズされるのは、インターフェイスを指し示すスタティック ルートが接続された結果、静的な性質を失ったとルーティング テーブルで見なされるためです。ただし、network コマンドで定義されたネットワーク以外のインターフェイスに対してスタティック ルートを定義する場合は、ダイナミック ルーティング プロトコルに redistribute スタティック コマンドを指定しないかぎり、ルートはアドバタイズされません。
インターフェイスがダウンすると、ダウンしたインターフェイスを経由するすべてのスタティック ルートが IP ルーティング テーブルから削除されます。転送ルータのアドレスとして指定されたアドレスへ向かう有効なネクスト ホップがスタティック ルート内に見つからない場合は、IP ルーティング テーブルからそのスタティック ルートも削除されます。
デフォルトのルートおよびネットワークの指定
ルータが他のすべてのネットワークへのルートを学習することはできません。完全なルーティング機能を実現するには、一部のルータをスマート ルータとして使用し、それ以外のルータのデフォルト ルートをスマート ルータ宛に指定します(スマート ルータには、インターネットワーク全体のルーティング テーブル情報が格納されます)。これらのデフォルト ルートは動的に学習されるか、ルータごとに設定されます。ほとんどのダイナミックな内部ルーティング プロトコルには、スマート ルータを使用してデフォルト情報をダイナミックに生成し、他のルータに転送するメカニズムがあります。
指定されたデフォルト ネットワークに直接接続されたインターフェイスがルータに存在する場合は、そのデバイス上で動作するダイナミック ルーティング プロトコルによってデフォルト ルートが生成されます。RIP の場合は、疑似ネットワーク 0.0.0.0 がアドバタイズされます。
ネットワークのデフォルトを生成しているルータには、そのルータ自身のデフォルト ルートも指定する必要があります。ルータが自身のデフォルト ルートを生成する方法の 1 つは、適切なデバイスを経由してネットワーク 0.0.0.0 に至るスタティック ルートを指定することです。
ネットワークへのスタティック ルートをスタティック デフォルト ルートとして定義するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
ルートを削除するには、 no ip default-network network number グローバル コンフィギュレーション コマンドを使用します。
ダイナミック ルーティング プロトコルによってデフォルト情報を送信するときは、特に設定する必要はありません。ルーティング テーブルは定期的にスキャンされ、デフォルト ルートとして最適なデフォルト ネットワークが選択されます。IGRP ネットワークでは、システムのデフォルト ネットワークの候補が複数存在する場合もあります。シスコのルータでは、デフォルト ルートまたは最終ゲートウェイを設定するため、管理距離およびメトリック情報を使用します。
ダイナミックなデフォルト情報がシステムに送信されない場合は、 ip default-network グローバル コンフィギュレーション コマンドを使用し、デフォルト ルートの候補を指定します。このネットワークが任意の送信元のルーティング テーブルに格納されている場合は、デフォルト ルートの候補としてフラグ付けされます。ルータにデフォルト ネットワークのインターフェイスが存在しなくても、そこへのパスが格納されている場合、そのネットワークは 1 つの候補と見なされ、最適なデフォルト パスへのゲートウェイが最終ゲートウェイになります。
ルート マップによるルーティング情報の再配信
スイッチでは複数のルーティング プロトコルを同時に実行し、ルーティング プロトコル間で情報を再配信できます。ルーティング プロトコル間での情報の再配信は、サポートされているすべての IP ベース ルーティング プロトコルに適用されます。
2 つのドメイン間で拡張パケット フィルタまたはルート マップを定義することにより、ルーティング ドメイン間でルートの再配信を条件付きで制御することもできます。 match および set ルート マップ コンフィギュレーション コマンドは、ルート マップの条件部分を定義します。 match コマンドは、一致しなければならない条件を指定します。 set コマンドは、ルーティング アップデートが match コマンドによって定義される条件と一致した場合に実行されるアクションを指定します。再配信はプロトコルに依存しない機能ですが、 match および set ルート マップ コンフィギュレーション コマンドの一部は特定のプロトコル固有のものです。
route-map コマンドのあとに、 match コマンドおよび set コマンドをそれぞれ 1 つまたは複数指定します。 match コマンドを指定しない場合は、すべて一致すると見なされます。 set コマンドを指定しない場合、一致以外の処理はすべて実行されません。このため、少なくとも 1 つの match または set コマンドを指定する必要があります。
(注) set ルート マップ コンフィギュレーション コマンドが指定されていないルート マップは CPU に送信され、CPU の利用率が高くなります。
ルートマップ ステートメントは、 permit または deny として識別することもできます。ステートメントが拒否としてマークされている場合、一致基準を満たすパケットは通常の転送チャネルを通じて送り返されます(宛先ベース ルーティング)。ステートメントが許可としてマークされている場合は、一致基準を満たすパケットに set コマンドが適用されます。一致基準を満たさないパケットは、通常のルーティング チャネルを通じて転送されます。
BGP ルート マップ continue コマンドを使用すると、match および set コマンドが正常に実行されたあと、ルート マップの他のエントリを実行することができます。 continue コマンドを使用することで、よりモジュール化したポリシー定義の構成と編成ができるので、同じルート マップ内に特定のポリシー設定を繰り返す必要がなくなります。スイッチでは、発信ポリシーに continue コマンドを使用できます。ルート マップ continue コマンドの使用方法の詳細については、次の URL で、『BGP Route-Map Continue Support for an Outbound Policy feature guide for Cisco IOS Release 12.4(4)T』を参照してください。
http://www.cisco.com/en/US/products/ps6441/products_feature_guides_list.html
(注) 次に示すステップ 3 ~ 14 はそれぞれ任意ですが、少なくとも 1 つの match ルート マップ コンフィギュレーション コマンド、および 1 つの set ルート マップ コンフィギュレーション コマンドを入力する必要があります。
再配信用のルート マップを設定するには、特権 EXEC モードで次の手順を実行します。
エントリを削除するには、 no route-map map tag グローバル コンフィギュレーション コマンド、または no match や no set ルートマップ コンフィギュレーション コマンドを使用します。
ルーティング ドメイン間でルートを配信したり、ルート再配信を制御できます。
ルート再配信を制御するには、特権 EXEC モードで次の手順を実行します。キーワードは前述の手順で定義されたキーワードと同じです。
再配信をディセーブルにするには、そのコマンドの no 形式を使用します。
ルーティング プロトコルのメトリックを、必ずしも別のルーティング プロトコルのメトリックに変換する必要はありません。たとえば、RIP メトリックはホップ カウントで、IGRP メトリックは 5 つの特性の組み合わせです。このような場合は、メトリックを独自に設定し、再配信されたルートに割り当てます。ルーティング情報を制御せずにさまざまなルーティング プロトコル間で交換するとルーティング ループが発生し、ネットワーク動作が著しく低下することもあります。
メトリック変換の代わりに使用されるデフォルトの再配信メトリックが定義されていない場合は、ルーティング プロトコル間で自動的にメトリック変換が発生することもあります。
•![]() RIP はスタティック ルートを自動的に再配信できます。スタティック ルートにはメトリック 1(直接接続)が割り当てられます。
RIP はスタティック ルートを自動的に再配信できます。スタティック ルートにはメトリック 1(直接接続)が割り当てられます。
PBR の設定
PBR を使用すると、トラフィック フローに定義済みポリシーを設定できます。PBR を使用してルーティングをより細かく制御するには、ルーティング プロトコルから取得したルートの信頼度を小さくします。PBR は、次の基準に基づいて、パスを許可または拒否するルーティング ポリシーを設定したり、実装したりできます。
PBR を使用すると、等価アクセスや送信元依存ルーティング、双方向対バッチ トラフィックに基づくルーティング、専用リンクに基づくルーティングを実現できます。たとえば、在庫記録を本社に送信する場合は広帯域で高コストのリンクを短時間使用し、電子メールなど日常的に使用するアプリケーション データは狭帯域で低コストのリンクで送信できます。
PBR がイネーブルの場合は、Access Control List(ACL; アクセス コントロール リスト)を使用してトラフィックを分類し、各トラフィックがそれぞれ異なるパスを経由するようにします。PBR は着信パケットに適用されます。PBR がイネーブルのインターフェイスで受信されたすべてのパケットは、ルート マップを通過します。ルート マップで定義された基準に基づいて、パケットは適切なネクスト ホップに転送(ルーティング)されます。
•![]() パケットがルート マップ ステートメントと一致しない場合は、すべての set コマンドが適用されます。
パケットがルート マップ ステートメントと一致しない場合は、すべての set コマンドが適用されます。
•![]() ステートメントが許可とマークされている場合、どのルートマップ ステートメントとも一致しないパケットは通常の転送チャネルを通じて送信され、宛先ベースのルーティングが実行されます。
ステートメントが許可とマークされている場合、どのルートマップ ステートメントとも一致しないパケットは通常の転送チャネルを通じて送信され、宛先ベースのルーティングが実行されます。
•![]() PBR に対して、拒否のマークが付いているルートマップ ステートメントはサポートされていません。
PBR に対して、拒否のマークが付いているルートマップ ステートメントはサポートされていません。
ルート マップの設定の詳細については、「ルート マップによるルーティング情報の再配信」を参照してください。
標準 IP ACL を使用すると、アプリケーション、プロトコル タイプ、またはエンド ステーションに基づいて一致基準を指定するように、送信元アドレスまたは拡張 IP ACL の一致基準を指定できます。一致が見つかるまで、ルート マップにこのプロセスが行われます。不一致が見つからない場合は、通常の宛先ベース ルーティングが発生します。match ステートメント リストの末尾には、暗黙の拒否エントリがあります。
match コマンドが満たされた場合は、set コマンドを使用して、パス内のネクスト ホップ ルータを識別する IP アドレスを指定できます。
PBR コマンドおよびキーワードの詳細については、『 Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols 』Release 12.2 を参照してください。表示されているにもかかわらずスイッチでサポートされない PBR コマンドについては、 付録 D「Cisco IOS Release 12.2(52)SE でサポートされていないコマンド」 を参照してください。
PBR 設定はスタック全体に適用され、すべてのスイッチでスタック マスターの設定が使用されます。
(注) このソフトウェア リリースは、IPv4 および IPv6 トラフィック処理時に PBR をサポートしません。
PBR 設定時の注意事項
•![]() PBR を使用するには、スタック マスター上で IP サービス イメージが稼動している必要があります。
PBR を使用するには、スタック マスター上で IP サービス イメージが稼動している必要があります。
•![]() マルチキャスト トラフィックには、ポリシーによるルーティングが行われません。PBR が適用されるのはユニキャスト トラフィックだけです。
マルチキャスト トラフィックには、ポリシーによるルーティングが行われません。PBR が適用されるのはユニキャスト トラフィックだけです。
•![]() ルーテッド ポートまたは SVI 上で、PBR をイネーブルにできます。
ルーテッド ポートまたは SVI 上で、PBR をイネーブルにできます。
•![]() スイッチは、PBR の route-map deny ステートメントをサポートしていません。
スイッチは、PBR の route-map deny ステートメントをサポートしていません。
•![]() レイヤ 3 モードの EtherChannel ポート チャネルにはポリシー ルート マップを適用できますが、EtherChannel のメンバーである物理インターフェイスには適用できません。適用しようとすると、コマンドが拒否されます。ポリシー ルート マップが適用されている物理インターフェイスは、EtherChannel のメンバーになることができません。
レイヤ 3 モードの EtherChannel ポート チャネルにはポリシー ルート マップを適用できますが、EtherChannel のメンバーである物理インターフェイスには適用できません。適用しようとすると、コマンドが拒否されます。ポリシー ルート マップが適用されている物理インターフェイスは、EtherChannel のメンバーになることができません。
•![]() スイッチ スタックには最大 246 個の IP ポリシー ルート マップを定義できます。
スイッチ スタックには最大 246 個の IP ポリシー ルート マップを定義できます。
•![]() スイッチ スタックには、PBR 用として最大 512 個の Access Control Entry(ACE; アクセス コントロール エントリ)を定義できます。
スイッチ スタックには、PBR 用として最大 512 個の Access Control Entry(ACE; アクセス コントロール エントリ)を定義できます。
•![]() ルート マップに一致基準を設定するときには、次の注意事項に従ってください。
ルート マップに一致基準を設定するときには、次の注意事項に従ってください。
–![]() ローカル アドレス宛のパケットを許可する ALC と一致させないでください。PBR はこれらのパケットを転送しますが、ping や Telnet 障害またはルート プロトコル フラッピングが発生する可能性があります。
ローカル アドレス宛のパケットを許可する ALC と一致させないでください。PBR はこれらのパケットを転送しますが、ping や Telnet 障害またはルート プロトコル フラッピングが発生する可能性があります。
–![]() 拒否 ACE のある ACL と一致させないでください。拒否 ACE と一致するパケットが CPU に送信されると、CPU の利用率が高くなる可能性があります。
拒否 ACE のある ACL と一致させないでください。拒否 ACE と一致するパケットが CPU に送信されると、CPU の利用率が高くなる可能性があります。
•![]() PBR を使用するには、 sdm prefer routing グローバル コンフィギュレーション コマンドを使用して、まずルーティング テンプレートをイネーブルにする必要があります。VLAN またはデフォルト テンプレートでは、PBR がサポートされません。SDM テンプレートの詳細については、「SDM テンプレートの設定」を参照してください。
PBR を使用するには、 sdm prefer routing グローバル コンフィギュレーション コマンドを使用して、まずルーティング テンプレートをイネーブルにする必要があります。VLAN またはデフォルト テンプレートでは、PBR がサポートされません。SDM テンプレートの詳細については、「SDM テンプレートの設定」を参照してください。
•![]() VRF と PBR は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスでイネーブルになっているときは、VRF をイネーブルにすることはできません。同じように、インターフェイスで VRF がイネーブルになっているときは、PBR をイネーブルにはできません。
VRF と PBR は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスでイネーブルになっているときは、VRF をイネーブルにすることはできません。同じように、インターフェイスで VRF がイネーブルになっているときは、PBR をイネーブルにはできません。
•![]() WCCP と PBR は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスでイネーブルになっているときは、WCCP をイネーブルにすることはできません。同じように、インターフェイスで WCCP がイネーブルになっているときは、PBR をイネーブルにすることはできません。
WCCP と PBR は、スイッチ インターフェイス上で相互に排他的です。PBR がインターフェイスでイネーブルになっているときは、WCCP をイネーブルにすることはできません。同じように、インターフェイスで WCCP がイネーブルになっているときは、PBR をイネーブルにすることはできません。
•![]() PBR で使用される Ternary CAM(TCAM)エントリ数は、ルート マップ自体、使用される ACL、ACL およびルート マップ エントリの順序によって異なります。
PBR で使用される Ternary CAM(TCAM)エントリ数は、ルート マップ自体、使用される ACL、ACL およびルート マップ エントリの順序によって異なります。
•![]() パケット長、Type of Service(ToS; サービス タイプ)、set interface、set default next hop、または set default interface に基づく PBR は、サポートされていません。有効な set アクションがないか、または set アクションが Don't Fragment に設定されているポリシー マップは、サポートされていません。
パケット長、Type of Service(ToS; サービス タイプ)、set interface、set default next hop、または set default interface に基づく PBR は、サポートされていません。有効な set アクションがないか、または set アクションが Don't Fragment に設定されているポリシー マップは、サポートされていません。
•![]() スイッチは PBR ルート マップでの Quality of Service(QoS)DSCP および IP precedence の一致をサポートしていて、次のような制限事項があります。
スイッチは PBR ルート マップでの Quality of Service(QoS)DSCP および IP precedence の一致をサポートしていて、次のような制限事項があります。
–![]() QoS DSCP 変換マップと PBR ルート マップを同じインターフェイスに適用することができません。
QoS DSCP 変換マップと PBR ルート マップを同じインターフェイスに適用することができません。
–![]() 透過的な DSCP と PBR DSCP ルート マップを同一スイッチに設定することはできません。
透過的な DSCP と PBR DSCP ルート マップを同一スイッチに設定することはできません。
–![]() PBR と QoS DSCP を設定する際に、QoS をイネーブルに設定( mls qos グローバル コンフィギュレーション コマンドを入力)するか、ディセーブルに設定( no mls qos グローバル コンフィギュレーション コマンドを入力)することができます。QoS がイネーブルの場合、トラフィックの DSCP 値が変更されないようにするには、 mls qos trust dscp インターフェイス コンフィギュレーション コマンドを入力して、スイッチの入力トラフィック ポートで DSCP 信頼状態を設定します。信頼状態が DSCP でない場合、デフォルトですべての信頼されていないトラフィックの DSCP 値が 0 に設定されます。
PBR と QoS DSCP を設定する際に、QoS をイネーブルに設定( mls qos グローバル コンフィギュレーション コマンドを入力)するか、ディセーブルに設定( no mls qos グローバル コンフィギュレーション コマンドを入力)することができます。QoS がイネーブルの場合、トラフィックの DSCP 値が変更されないようにするには、 mls qos trust dscp インターフェイス コンフィギュレーション コマンドを入力して、スイッチの入力トラフィック ポートで DSCP 信頼状態を設定します。信頼状態が DSCP でない場合、デフォルトですべての信頼されていないトラフィックの DSCP 値が 0 に設定されます。
PBR のイネーブル化
デフォルトでは、PBR はスイッチ上でディセーブルです。PBR をイネーブルにするには、一致基準およびすべての match コマンドと一致した場合の動作を指定するルート マップを作成する必要があります。次に、特定のインターフェイスでそのルート マップ用の PBR をイネーブルにします。指定したインターフェイスに着信したパケットのうち、match コマンドと一致したものはすべて PBR の対象になります。
PBR は、スイッチの速度低下を引き起こさない速度で、高速転送したり実装したりできます。高速スイッチングされた PBR では、ほとんどの match および set コマンドを使用できます。PBR の高速スイッチングをイネーブルにするには、事前に PBR をイネーブルにする必要があります。PBR の高速スイッチングは、デフォルトでディセーブルです。
スイッチで生成されたパケットまたはローカル パケットは、通常どおりにポリシー ルーティングされません。スイッチ上でローカル PBR をグローバルにイネーブルにすると、そのスイッチから送信されたすべてのパケットがローカル PBR の影響を受けます。ローカル PBR は、デフォルトでディセーブルに設定されています。
(注) PBR をイネーブルにするには、スタック マスター上で IP サービス イメージが稼動している必要があります。
PBR を設定するには、特権 EXEC モードで次の手順を実行します。
エントリを削除するには、 no route-map map-tag グローバル コンフィギュレーション コマンド、または no match または no set ルート マップ コンフィギュレーション コマンドを使用します。インターフェイス上で PBR をディセーブルにするには、 no ip policy route-map map-tag インターフェイス コンフィギュレーション コマンドを使用します。PBR の高速スイッチングをディセーブルにするには、 no ip route-cache policy インターフェイス コンフィギュレーション コマンドを使用します。スイッチから送信されるパケットに対して PBR をディセーブルにするには、 ip local policy route-map map-tag グローバル コンフィギュレーション コマンドを使用します。
ルーティング情報のフィルタリング
ルーティング プロトコル情報をフィルタリングする場合は、次の作業を実行します。
(注) OSPF プロセス間でルートが再配信される場合、OSPF メトリックは保持されません。
パッシブ インターフェイスの設定
ローカル ネットワーク上の他のルータが動的にルートを取得しないようにするには、 passive-interface ルータ コンフィギュレーション コマンドを使用し、ルーティング アップデート メッセージがルータ インターフェイスから送信されないようにします。OSPF プロトコルでこのコマンドを使用すると、パッシブに指定したインターフェイス アドレスが OSPF ドメインのスタブ ネットワークとして表示されます。OSPF ルーティング情報は、指定されたルータ インターフェイスから送受信されません。
多数のインターフェイスが存在するネットワークで、インターフェイスを手動でパッシブに設定する作業を回避するには、 passive-interface default ルータ コンフィギュレーション コマンドを使用し、すべてのインターフェイスをデフォルトでパッシブになるように設定します。このあとで、隣接関係が必要なインターフェイスを手動で設定します。
パッシブ インターフェイスを設定するには、特権 EXEC モードで次の手順を実行します。
|
|
|
|
|---|---|---|
(任意)ルーティング プロセス用のネットワーク リストを指定します。 network-address は IP アドレスです。 |
||
パッシブとしてイネーブルにしたインターフェイスを確認するには、 show ip ospf interface などのネットワーク モニタ用特権 EXEC コマンドを使用します。アクティブとしてイネーブルにしたインターフェイスを確認するには、 show ip interface 特権 EXEC コマンドを使用します。
ルーティング アップデートの送信を再度イネーブルにするには、 no passive-interface interface-id ルータ コンフィギュレーション コマンドを使用します。 default キーワードを指定すると、すべてのインターフェイスがデフォルトでパッシブに設定されます。次に、 no passive-interface ルータ コンフィギュレーション コマンドを使用し、隣接関係を必要とする各インターフェイスを個別に設定します。 default キーワードは、ほとんどの配信ルータに 200 を超えるインターフェイスが備わっているインターネット サービス プロバイダーや大規模な企業ネットワークの場合に役立ちます。
ルーティング アップデートのアドバタイズメントおよび処理の制御
ACL と distribute-list ルータ コンフィギュレーション コマンドを組み合わせて使用すると、ルーティング アップデート中にルートのアドバタイズメントを抑制し、他のルータが 1 つまたは複数のルートを取得しないようにできます。この機能を OSPF で使用した場合は外部ルートだけに適用されるため、インターフェイス名を指定することはできません。
distribute-list ルータ コンフィギュレーション コマンドを使用し、着信したアップデートのリストのうち特定のルートを処理しないようにすることもできます(OSPF にこの機能は適用されません)。
ルーティング アップデートのアドバタイズメントまたは処理を制御するには、特権 EXEC モードで次の手順を実行します。
フィルタを変更またはキャンセルするには、 no distribute-list in ルータ コンフィギュレーション コマンドを使用します。アップデート中のネットワーク アドバタイズメントの抑制をキャンセルするには、 no distribute-list out ルータ コンフィギュレーション コマンドを使用します。
ルーティング情報の送信元のフィルタリング
一部のルーティング情報が他の情報よりも正確な場合があるため、フィルタリングを使用して、さまざまな送信元から送られる情報にプライオリティを設定できます。「 管理距離 」は、ルータやルータのグループなど、ルーティング情報の送信元の信頼性を示す数値です。大規模ネットワークでは、他のルーティング プロトコルよりも信頼できるルーティング プロトコルが存在する場合があります。管理距離の値を指定すると、ルータはルーティング情報の送信元をインテリジェントに区別できるようになります。常にルーティング プロトコルの管理距離が最短(値が最小)であるルートが選択されます。表 38-16 に、さまざまなルーティング情報送信元のデフォルトの管理距離を示しています。
各ネットワークには独自の要件があるため、管理距離を割り当てる一般的な注意事項はありません。
ルーティング情報の送信元をフィルタリングするには、特権 EXEC モードで、次の手順を実行します。
認証鍵の管理
鍵管理を使用すると、ルーティング プロトコルで使用される認証鍵を制御できます。一部のプロトコルでは、鍵管理を使用することができません。認証鍵は EIGRP および RIP バージョン 2 で使用できます。
認証鍵を管理する前に、認証をイネーブルにする必要があります。プロトコルに対して認証をイネーブルにする方法については、該当するプロトコルについての説明を参照してください。認証鍵を管理するには、キー チェーンを定義してそのキー チェーンに属する鍵を識別し、各鍵の有効期間を指定します。各鍵には、ローカルに格納される独自の鍵 ID( key number キー チェーン コンフィギュレーション コマンドで指定)があります。鍵 ID、およびメッセージに関連付けられたインターフェイスの組み合わせにより、使用中の認証アルゴリズムおよび Message Digest 5(MD5)認証鍵が一意に識別されます。
有効期間が指定された複数の鍵を設定できます。存在する有効な鍵の個数に関係なく、1 つの認証パケットだけが送信されます。鍵番号は小さい方から大きい方へ順に調べられ、最初に見つかった有効な鍵が使用されます。鍵変更中は、有効期間が重なっても問題ありません。これらの有効期間は、ルータに通知する必要があります。
認証鍵を管理するには、特権 EXEC モードで次の手順を実行します。
キー チェーンを削除するには、 no key chain name-of-chain グローバル コンフィギュレーション コマンドを使用します。
IP ネットワークのモニタおよびメンテナンス
特定のキャッシュ、テーブル、またはデータベースのすべての内容を削除できます。特定の統計情報を表示することもできます。ルートを消去したり、ステータスを表示するには、 表 38-17 に示す特権 EXEC コマンドを使用します。
|
|
|
|---|---|
show ip route [ address [ mask ] [ longer-prefixes ]] | [ protocol [ process-id ]] |
|
 フィードバック
フィードバック