Disaster Recovery Workflow
InMage CDP starts with the FX/VX agent, also known as "DataTap," which is used to monitor all writes to disk. A small amount of memory on the source machine is reserved by the DataTap (250MB). When changes are being written to primary storage, a copy of the change is stored in the reserved memory. When the memory reaches a certain size, the contents of the reserved memory are sent as a chunk to the processing server. This "write coalescing" is mainly for WAN optimization. The processing server then compresses it for WAN transmission and sends to the MT at the secondary site. Once the MT receives the compress data, it will:
1. ![]() Uncompress and store incoming data in the cache volume. One folder exists for each VMDK under protection.
Uncompress and store incoming data in the cache volume. One folder exists for each VMDK under protection.
2. ![]() Reverse coalescing received data into individual blocks.
Reverse coalescing received data into individual blocks.
3. ![]() Read/retrieve old data blocks from VMDK.
Read/retrieve old data blocks from VMDK.
4. ![]() Write old data blocks to MT retention volume for Journal.
Write old data blocks to MT retention volume for Journal.
5. ![]() Writes individual new blocks to target VMDKs.
Writes individual new blocks to target VMDKs.
For every write at the source, 2 writes and 1 read exist at the destination performed by the MT.
Data protection will continue until disaster declaration. During a DR event, a predefined VM recovery plan to secondary site can be started. The recovery plan will:
1. ![]() Unmount protected disks (VMDK) attached to the MT and release the read/write lock.
Unmount protected disks (VMDK) attached to the MT and release the read/write lock.
2. ![]() Readdress the secondary server with new IP address and subnet.
Readdress the secondary server with new IP address and subnet.
3. ![]() Power on the secondary server (VM).
Power on the secondary server (VM).
Once the primary site comes back online, a failback plan can be created. It is called a failback plan because the objective is to restore the latest data from the secondary site to the newly restored primary site. Under the covers, a failback plan works identically as a protection plan; the only difference is the direction of data protection, secondary to primary versus primary to secondary. Once failback replication reaches "Differential Sync" status, the recovery plan can be executed to bring the servers in primary site back in service.
This chapter includes the following major topics:
•![]() Failback Protection Workflows
Failback Protection Workflows
Protection Workflows
InMage vContinuum is a DR solution for VMware vSphere (ESX and ESXi) servers and physical servers. vContinuum protects VMs on your primary ESX/ESXi server, and your physical servers, by replicating them to a secondary ESX/ESXi server and recovering them on the secondary ESX/ESXi server when needed. vContinuum not only captures all changes, but also provides the ability to recover to any point in time during the configured retention period.
Figure 4-1 Protection Plan Overview

vContinuum supports two types of protection:
•![]() Virtual-to-Virtural (V2V): Primary customer VMs that reside on the primary VMware ESX server are protected and recovered as secondary provider VMs on the secondary VMware ESX server.
Virtual-to-Virtural (V2V): Primary customer VMs that reside on the primary VMware ESX server are protected and recovered as secondary provider VMs on the secondary VMware ESX server.
•![]() Physical-to-Virtual (P2V): Customer physical servers can be protected and recovered as a secondary provider VM on a secondary VMware ESX server.
Physical-to-Virtual (P2V): Customer physical servers can be protected and recovered as a secondary provider VM on a secondary VMware ESX server.
When a V2V or P2V protection plan is first created, the initial volume replication can be bandwidth intensive. Offline Sync is a feature that allows for initial volume replication to occur offline instead of over a WAN. This technique eliminates the initial volume replication over the WAN, thereby reducing the overall WAN bandwidth required to perform the protection plan.
This section includes the following topics:
•![]() Setting up Virtual-to-Virtual (V2V) Protection Plan
Setting up Virtual-to-Virtual (V2V) Protection Plan
•![]() Setting up Physical-to-Virtual (P2V) Protection Plan
Setting up Physical-to-Virtual (P2V) Protection Plan
Setting up Virtual-to-Virtual (V2V) Protection Plan
Virtual-to-virtual protection enables the recovery of a VM, including OS partition and application data, to a prior point in time. A dedicated VM, called a "master target" or "MT," needs to be prepared on the secondary vSphere server. The MT receives all the changes of the primary server and stores them in the retention store. When a disaster event is declared, the administrator can recover a VM to a specific consistency point or point in time. InMage provides a wizard to facilitate the creation of protection plans and other actions. The vContinuum wizard will be used to create a new protection plan for five primary Windows 2008 VMs in this section.

Note ![]() The following steps to configure a protection plan are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to configure a protection plan are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
Step 1 ![]() Start vContinuum wizard application.
Start vContinuum wizard application.
a. ![]() Select the primary vCenter to view available source servers.
Select the primary vCenter to view available source servers.
–![]() Select VM(s) and their volumes to protect.
Select VM(s) and their volumes to protect.
b. ![]() Select the secondary vCenter to view available MT(s).
Select the secondary vCenter to view available MT(s).
–![]() Select MT(s).
Select MT(s).
c. ![]() Configure replication options.
Configure replication options.
d. ![]() Select datastores in secondary vCenter to create recovery VM(s).
Select datastores in secondary vCenter to create recovery VM(s).
e. ![]() Configure recovery VM(s) configuration options (for example, network, hardware, display name, sparse retention settings).
Configure recovery VM(s) configuration options (for example, network, hardware, display name, sparse retention settings).
f. ![]() Finalize protection plan.
Finalize protection plan.
Step 2 ![]() Monitor protection plan.
Monitor protection plan.
Detailed Steps
Step 1 ![]() On the Management Console, start the vContinuum wizard application using the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum:
On the Management Console, start the vContinuum wizard application using the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum:
a. ![]() Select ESX in the Choose Application drop-down list for V2V protection plan.
Select ESX in the Choose Application drop-down list for V2V protection plan.
b. ![]() Enter the CX server IP address and port number (the default is 80).
Enter the CX server IP address and port number (the default is 80).
c. ![]() Select New Protection to create a new protection plan.
Select New Protection to create a new protection plan.
Figure 4-2 Creating New V2V Protection Plan in vContinuum

d. ![]() Enter the primary vSphere/vCenter IP address, Username, Password, and Guest OS Type and then click Get Details to view available source servers.
Enter the primary vSphere/vCenter IP address, Username, Password, and Guest OS Type and then click Get Details to view available source servers.
Figure 4-3 Selecting Primary vSphere/vCenter

e. ![]() Select the primary VM(s) and their volumes to protect, then click Next.
Select the primary VM(s) and their volumes to protect, then click Next.
Note![]() •
•![]() When a primary VM is selected, the General Details section of the vContinuum wizard shows details about the selected VM.
When a primary VM is selected, the General Details section of the vContinuum wizard shows details about the selected VM.
•![]() By default, all local volumes are selected for protection. Volumes can be omitted from the protection plan by deselecting the volumes, but the disk that contains the operating system must be selected or the recovered VM will not be able to start after a disaster event.
By default, all local volumes are selected for protection. Volumes can be omitted from the protection plan by deselecting the volumes, but the disk that contains the operating system must be selected or the recovered VM will not be able to start after a disaster event.
Figure 4-4 Selecting Primary VMs

f. ![]() Enter the secondary vSphere/vCenter IP address, Username, and Password, and then click Get Details to view the available MT(s).
Enter the secondary vSphere/vCenter IP address, Username, and Password, and then click Get Details to view the available MT(s).
Note ![]() The MT must be of the same OS family as the primary VM(s) it protects. If the primary VMs use Windows, then the MT must also be Windows. The same requirement exists for Linux servers. For more information on MT considerations, refer toMaster Target—Enterprise and Service Provider, page 3-1.
The MT must be of the same OS family as the primary VM(s) it protects. If the primary VMs use Windows, then the MT must also be Windows. The same requirement exists for Linux servers. For more information on MT considerations, refer toMaster Target—Enterprise and Service Provider, page 3-1.
g. ![]() Select the MT that will be used to protect the selected primary VM(s) and then click Next.
Select the MT that will be used to protect the selected primary VM(s) and then click Next.
Figure 4-5 Selecting Secondary MT(s)

h. ![]() Configure replication options.
Configure replication options.
–![]() In the Process server IP field, select the process server located in the primary network (e.g., Enterprise). Multiple process servers can be deployed and associated with a limited number of primary VMs for scalability.
In the Process server IP field, select the process server located in the primary network (e.g., Enterprise). Multiple process servers can be deployed and associated with a limited number of primary VMs for scalability.
–![]() In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
–![]() In the Retention Drive field, select the drive letter that is associated with the retention drive on the MT.
In the Retention Drive field, select the drive letter that is associated with the retention drive on the MT.
–![]() In the Retention (in days) field, enter the maximum number of days to store retention data.
In the Retention (in days) field, enter the maximum number of days to store retention data.
Note![]() •
•![]() The amount of retention data can be limited by disk space, time, or both. For more information on retention data considerations, refer to Retention Volume Sizing, page 3-3.
The amount of retention data can be limited by disk space, time, or both. For more information on retention data considerations, refer to Retention Volume Sizing, page 3-3.
•![]() The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settingspage.
The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settingspage.
i. ![]() In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the primary VMs. This value determines the RPO for consistency point-based recovery.
In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the primary VMs. This value determines the RPO for consistency point-based recovery.
Figure 4-6 Configuring Replication Options

j. ![]() Select the target datastores in secondary vCenter to create recovery VM(s) and then click Next.
Select the target datastores in secondary vCenter to create recovery VM(s) and then click Next.
Figure 4-7 Selecting Datastores in Secondary vCenter

k. ![]() Specify configuration options for recovered VM(s) in the secondary vSphere/vCenter environment (for example, network, hardware, display name, sparse retention settings).
Specify configuration options for recovered VM(s) in the secondary vSphere/vCenter environment (for example, network, hardware, display name, sparse retention settings).
–![]() Select which network interfaces to include in the recovery VM(s).
Select which network interfaces to include in the recovery VM(s).
–![]() Configure the port group to use in the secondary vSphere/vCenter network and any new network configurations. By default, the network configuration of the primary VM(s) will be used and may need to be changed. If an interface will use DHCP in the secondary vSphere/ vCenter environment to get an IP address, then select DHCP and the appropriate port group (for example, Network Label).
Configure the port group to use in the secondary vSphere/vCenter network and any new network configurations. By default, the network configuration of the primary VM(s) will be used and may need to be changed. If an interface will use DHCP in the secondary vSphere/ vCenter environment to get an IP address, then select DHCP and the appropriate port group (for example, Network Label).
Figure 4-8 Configure Network Settings for VM in Secondary vCenter (DHCP)

Figure 4-9 Configure Network Settings for VM in Secondary vCenter (New IP Address)

Note ![]() If multiple interfaces are selected, some additional configuration may be required for proper routing. Only one of the interfaces should be configured with a default route and if any static routes are required, they must be added after the recovered VM is powered up via scripts or manual configuration.
If multiple interfaces are selected, some additional configuration may be required for proper routing. Only one of the interfaces should be configured with a default route and if any static routes are required, they must be added after the recovered VM is powered up via scripts or manual configuration.
–![]() Configure the hardware settings for the VM(s) in the secondary vSphere/vCenter. These settings can be applied to all VMs in the protection plan by selecting Use these values for all VMs.
Configure the hardware settings for the VM(s) in the secondary vSphere/vCenter. These settings can be applied to all VMs in the protection plan by selecting Use these values for all VMs.
–![]() Configure the display name for the VM(s) in the secondary vSphere/vCenter. To apply the "Keep same as source," "Apply Pre-fix," and "Apply Suffix" options to all VMs in the protection plan, select Use for all VM(s).
Configure the display name for the VM(s) in the secondary vSphere/vCenter. To apply the "Keep same as source," "Apply Pre-fix," and "Apply Suffix" options to all VMs in the protection plan, select Use for all VM(s).
Figure 4-10 Configure Display Name for VM in Secondary vSphere/vCenter

l. ![]() Click Advanced settings to access advanced settings for protection. The default configuration shown in Figure 4-11.
Click Advanced settings to access advanced settings for protection. The default configuration shown in Figure 4-11.
–![]() In the Sparse Retention section, advanced retention settings can be configured to have varying number of retention points based on age. A small number of retention points can be stored for weeks or months in the past, while more retention points can be stored for days in the past.
In the Sparse Retention section, advanced retention settings can be configured to have varying number of retention points based on age. A small number of retention points can be stored for weeks or months in the past, while more retention points can be stored for days in the past.
–![]() In the Folder Name Settings section, the directory for the VM in the datastore can be configured.
In the Folder Name Settings section, the directory for the VM in the datastore can be configured.
–![]() In the Compression section, compression type can be changed or disabled.
In the Compression section, compression type can be changed or disabled.
–![]() In the Encryption section, encryption can be enabled for the primary VM to the Process Server path, the Process Server to MT path, or both.
In the Encryption section, encryption can be enabled for the primary VM to the Process Server path, the Process Server to MT path, or both.
–![]() In the Resource pool section, a resource pool on the secondary vSphere/vCenter can be specified. Resource pools can be used to isolate tenants from each other.
In the Resource pool section, a resource pool on the secondary vSphere/vCenter can be specified. Resource pools can be used to isolate tenants from each other.
–![]() In the Provisioning section, thin or thick provisioning can be configured.
In the Provisioning section, thin or thick provisioning can be configured.
Figure 4-11 Optional Advanced Settings for VM Protection

–![]() Click Next to advance to the final page.
Click Next to advance to the final page.
m. ![]() Finalize the protection plan.
Finalize the protection plan.
–![]() Click Run Readiness Checks to perform checks.
Click Run Readiness Checks to perform checks.
–![]() Enter a name for the protection plan.
Enter a name for the protection plan.
–![]() Click Protect to finalize the protection plan.
Click Protect to finalize the protection plan.
Figure 4-12 Finalize Protection Plan

Step 2 ![]() Monitor theprotection plan. After finalizing the protection plan, vContinuum goes through a number of steps to put the protection plan in place. The initialization of the protection plan can be monitored from the status window.
Monitor theprotection plan. After finalizing the protection plan, vContinuum goes through a number of steps to put the protection plan in place. The initialization of the protection plan can be monitored from the status window.
Figure 4-13 Protection Plan Initializing (vContinuum)

Figure 4-14 Protection Plan Monitoring (vContinuum)

Figure 4-15 Protection Plan Initializing (Service Provider vCenter)

Figure 4-16 Master Target Disk Layout (Service Provider vCenter)

Figure 4-17 Checking Primary VM from CX UI

Setting up Physical-to-Virtual (P2V) Protection Plan
The entire physical server, including operating system and data, can be protected using vContinuum. The physical server is replicated to VMs running on ESX servers located at the secondary site. These VMs can then be powered up at the time of disaster or whenever required. Secondary VMs can be protected back to physical servers using the steps described in the virtual-to-physical (V2P) procedure found in "Virtual-to-Physical (V2P) Failback Protection" section. P2V supports both Windows and Linux operating systems.
Note ![]() The following steps to configure a protection plan are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to configure a protection plan are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Create a new protection plan using the vContinuum wizard.
Create a new protection plan using the vContinuum wizard.
2. ![]() Select the primary physical server(s) and volume(s) to protect.
Select the primary physical server(s) and volume(s) to protect.
3. ![]() Select the secondary site MT.
Select the secondary site MT.
4. ![]() Configure the replication options and select the secondary site target datastore.
Configure the replication options and select the secondary site target datastore.
5. ![]() Configure the secondary VM(s) configuration options.
Configure the secondary VM(s) configuration options.
6. ![]() Configure the secondary VM(s) configuration advanced settings (optional).
Configure the secondary VM(s) configuration advanced settings (optional).
7. ![]() Run the readiness check, name the protection plan, and protect.
Run the readiness check, name the protection plan, and protect.
8. ![]() Monitor the protection plan status from the CX UI.
Monitor the protection plan status from the CX UI.
Detailed Steps
Step 1 ![]() Create a new protection plan using the vContinuum wizard.
Create a new protection plan using the vContinuum wizard.
Figure 4-18 Create P2V Protection Plan using vContinuum

•![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
•![]() Select P2V from the Choose Application drop-down list for P2V protection plan.
Select P2V from the Choose Application drop-down list for P2V protection plan.
•![]() Enter the CX server's IP address and port number (default is 80).
Enter the CX server's IP address and port number (default is 80).
•![]() Select New Protection to create a new protection plan.
Select New Protection to create a new protection plan.
Step 2 ![]() Select the primary physical server(s) and volume(s) to protect.
Select the primary physical server(s) and volume(s) to protect.
Figure 4-19 Select Source Server

•![]() Set the OS type to Linux and select Get Details to retrieve a list of registered Linux primary servers. The list includes both virtual and physical servers.
Set the OS type to Linux and select Get Details to retrieve a list of registered Linux primary servers. The list includes both virtual and physical servers.
•![]() Select the physical server(s) and disk(s) to protect.
Select the physical server(s) and disk(s) to protect.
•![]() Click Next to continue.
Click Next to continue.
Note ![]() By default, all local volumes are selected for protection. Volumes can be omitted from the protection plan by deselecting the volumes. When protecting Linux physical servers, disk labels displayed in vContinuum may not map to the same disk in the physical server. For example, the label disk0 displayed in vContinuum may not map to the Linux physcial disk /dev/sda.
By default, all local volumes are selected for protection. Volumes can be omitted from the protection plan by deselecting the volumes. When protecting Linux physical servers, disk labels displayed in vContinuum may not map to the same disk in the physical server. For example, the label disk0 displayed in vContinuum may not map to the Linux physcial disk /dev/sda.
Step 3 ![]() Select the secondary site MT.
Select the secondary site MT.
Figure 4-20 Select Secondary ESX and Master Target

•![]() Enter the secondary vSphere/vCenter IP address and login credentials.
Enter the secondary vSphere/vCenter IP address and login credentials.
•![]() Click Get Details to list the available MT(s).
Click Get Details to list the available MT(s).
•![]() Select the MT that will be used to protect the selected primary physical server(s) or VM(s).
Select the MT that will be used to protect the selected primary physical server(s) or VM(s).
•![]() Click Next.
Click Next.
Note ![]() The MT must be of the same OS family as the primary physical server it protects. If the primary server run Linux OS, then the MT must also run Linux OS. The same requirement exists for Windows servers.
The MT must be of the same OS family as the primary physical server it protects. If the primary server run Linux OS, then the MT must also run Linux OS. The same requirement exists for Windows servers.
Step 4 ![]() Configure the replication options and specify the secondary site datastore.
Configure the replication options and specify the secondary site datastore.
Figure 4-21 Configure Replication Options and Select Datastore

•![]() In the Process server IP field, select the process server located in the primary network (e.g., Enterprise). The process server is used for both virtual and physical volume replication. Multiple process servers can be deployed for scale.
In the Process server IP field, select the process server located in the primary network (e.g., Enterprise). The process server is used for both virtual and physical volume replication. Multiple process servers can be deployed for scale.
•![]() In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
•![]() In the Retention Drive field, select the Windows drive letter or Linux mount point that is associated with the retention drive on the MT.
In the Retention Drive field, select the Windows drive letter or Linux mount point that is associated with the retention drive on the MT.
•![]() In the Retention (in days) field, enter the maximum number of days to store retention data.
In the Retention (in days) field, enter the maximum number of days to store retention data.
•![]() In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the primary VMs. This value determines the RPO for consistency point-based recovery.
In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the primary VMs. This value determines the RPO for consistency point-based recovery.
•![]() Click Next to continue.
Click Next to continue.
Note ![]() The amount of retention data can be limited by disk space, time, or both. The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settings page.
The amount of retention data can be limited by disk space, time, or both. The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settings page.
Step 5 ![]() Configure the secondary VM(s) configuration options.
Configure the secondary VM(s) configuration options.
Figure 4-22 Configure the VM Configuration

•![]() Select the network interfaces to include in the secondary VM(s).
Select the network interfaces to include in the secondary VM(s).
•![]() Click Change to assign the interface IP address and port group. The address and port group can be static or assigned dynamically via DHCP.
Click Change to assign the interface IP address and port group. The address and port group can be static or assigned dynamically via DHCP.
•![]() Configure the hardware settings for the secondary VM(s); for example, the number of CPU and size of RAM. These settings can be applied to all secondary VMs in the protection plan by selecting Use these values for all VMs.
Configure the hardware settings for the secondary VM(s); for example, the number of CPU and size of RAM. These settings can be applied to all secondary VMs in the protection plan by selecting Use these values for all VMs.
•![]() Configure the display name for the secondary VM(s) in the vSphere/vCenter. The "Keep same as source," "Apply Pre-fix," and "Apply Suffix" options can be applied to all VMs in the protection plan by selecting Use for all VM(s).
Configure the display name for the secondary VM(s) in the vSphere/vCenter. The "Keep same as source," "Apply Pre-fix," and "Apply Suffix" options can be applied to all VMs in the protection plan by selecting Use for all VM(s).
•![]() Click Advanced settings to access optional advanced settings for the protection plan.
Click Advanced settings to access optional advanced settings for the protection plan.
•![]() Or, click Next to continue.
Or, click Next to continue.
Note ![]() If multiple interfaces are selected, some additional configuration may be required for proper routing. Only one of the interfaces should be configured with a default route and if any static routes are required, they must be added after the recovered VM is powered up via scripts or manual configuration.
If multiple interfaces are selected, some additional configuration may be required for proper routing. Only one of the interfaces should be configured with a default route and if any static routes are required, they must be added after the recovered VM is powered up via scripts or manual configuration.
Step 6 ![]() Configure the secondary VM(s) configuration optional advanced settings.
Configure the secondary VM(s) configuration optional advanced settings.
Figure 4-23 VM Configuration Advanced Settings

•![]() In the Sparse Retention section, advanced retention settings can be configured to have varying number of retention points based on age. Less retention points can be stored for weeks or months in the past, while more retention points can be stored for days in the past.
In the Sparse Retention section, advanced retention settings can be configured to have varying number of retention points based on age. Less retention points can be stored for weeks or months in the past, while more retention points can be stored for days in the past.
•![]() In the Folder Name Settings section, the directory for the VM in the datastore can be configured.
In the Folder Name Settings section, the directory for the VM in the datastore can be configured.
•![]() In the Compression section, compression type can be changed or disabled.
In the Compression section, compression type can be changed or disabled.
•![]() In the Encryption section, encryption can be enabled for the primary VM to Process Server path, the Process Server to MT path, or both.
In the Encryption section, encryption can be enabled for the primary VM to Process Server path, the Process Server to MT path, or both.
•![]() In the Resource pool section, a resource pool on the secondary vSphere/vCenter can be specified. Resource pools can be used to isolate tenants from each other.
In the Resource pool section, a resource pool on the secondary vSphere/vCenter can be specified. Resource pools can be used to isolate tenants from each other.
•![]() In the Provisioning section, thin or thick provisioning can be configured.
In the Provisioning section, thin or thick provisioning can be configured.
Step 7 ![]() Run the readiness check, name the protection plan, and protect.
Run the readiness check, name the protection plan, and protect.
Figure 4-24 Run the Protection Plan

•![]() Click Run Readiness Checks to perform checks.
Click Run Readiness Checks to perform checks.
•![]() Enter a name for the protection plan.
Enter a name for the protection plan.
•![]() Click Protect to finalize the protection plan.
Click Protect to finalize the protection plan.
Step 8 ![]() Monitor the protection plan status from the CX UI.
Monitor the protection plan status from the CX UI.
Resync and differential data in transit can be monitored from the CX UI. Refer to "RPO and Health Monitoring" section on page 5-5 for details on monitoring.
Figure 4-25 Monitor the Protection Plan Status

Offline Sync
The initial copy of data in a protection plan is both WAN bandwidth intensive and takes a long time to complete. The offline sync feature can be used to limit the amount of WAN bandwidth and time required for the initial protection plan sync. This is accomplished by sending this first time copy of data to the secondary site via a removable media instead of transmitting the data across the WAN. The data copied to removable media can then be shipped to the secondary site for offline import.
Primary servers are first protected to a local vSphere server in the primary site. After volume replication to the local MT is complete, the MT is shutdown and folders containing the MT VM, along with a temporary staging folder called InMage OfflineSync Folder, are copied to a removable media and shipped to the secondary site. Folders can then be restored to the secondary vSphere server via the Offline Sync Import feature. Once the Offline Sync Import is complete, replication resumes and data changes called differentials get sent across WAN network in a normal way.
Offline sync has the following three steps:
Step 1 ![]() Offline sync export.
Offline sync export.
Step 2 ![]() Transfer folders to the removable media and copy them to the secondary vSphere server.
Transfer folders to the removable media and copy them to the secondary vSphere server.
Step 3 ![]() Offline sync import.
Offline sync import.
Note ![]() This example documents two steps in the offline sync workflow: offline sync export and offline sync import. The transfer step is completely bypassed by allowing the exported data to be replicated to the secondary site MT and copied directly to a temporary staging folder of a secondary site datastore. The primary server used in this example is a physical server running CentOS.
This example documents two steps in the offline sync workflow: offline sync export and offline sync import. The transfer step is completely bypassed by allowing the exported data to be replicated to the secondary site MT and copied directly to a temporary staging folder of a secondary site datastore. The primary server used in this example is a physical server running CentOS.
This section presents the following topics:
Offline Sync Export
Note ![]() The following steps to configure offline sync export are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to configure offline sync export are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Create an offline sync export plan using the vContinuum wizard.
Create an offline sync export plan using the vContinuum wizard.
2. ![]() Select the primary physical server(s) and volume(s) to protect.
Select the primary physical server(s) and volume(s) to protect.
3. ![]() Select the secondary site MT.
Select the secondary site MT.
4. ![]() Configure the replication options and specify the secondary site datastore.
Configure the replication options and specify the secondary site datastore.
5. ![]() Run the readiness check to finalize the offline sync export plan.
Run the readiness check to finalize the offline sync export plan.
6. ![]() Monitor the protection plan status from the CX UI.
Monitor the protection plan status from the CX UI.
7. ![]() Remove the MT from the vSphere/vCenter inventory.
Remove the MT from the vSphere/vCenter inventory.
Detailed Steps
Step 1 ![]() Create an offline sync export plan using the vContinuum wizard.
Create an offline sync export plan using the vContinuum wizard.
Figure 4-26 Create Offline Sync Export using vContinuum

•![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum.
•![]() Select P2V from the Choose Application drop-down list for P2V protection plan.
Select P2V from the Choose Application drop-down list for P2V protection plan.
•![]() Enter the CX server'IP address and port number (default is 80).
Enter the CX server'IP address and port number (default is 80).
•![]() Select Offline Sync and OfflineSync Export to create the offline sync export workflow.
Select Offline Sync and OfflineSync Export to create the offline sync export workflow.
Step 2 ![]() Select the primary physical server(s) and disk(s) to protect.
Select the primary physical server(s) and disk(s) to protect.
Figure 4-27 Select Primary Physical Server to Protect

•![]() Set the OS type to Linux and select Get Details to retrieve a list of available registered Linux primary servers. The list includes both virtual and physical servers.
Set the OS type to Linux and select Get Details to retrieve a list of available registered Linux primary servers. The list includes both virtual and physical servers.
•![]() Select the physical server(s) and disk(s) to protect.
Select the physical server(s) and disk(s) to protect.
•![]() Click Next to continue.
Click Next to continue.
Note ![]() By default, all local volumes are selected for protection. Volumes can be omitted from the protection plan by deselecting the volumes. When protecting Linux physical servers, disk labels displayed in vContinuum may not map to the same disk in the physical server. For example, the label disk0 displayed in vContinuum may not map to the Linux physical disk /dev/sda.
By default, all local volumes are selected for protection. Volumes can be omitted from the protection plan by deselecting the volumes. When protecting Linux physical servers, disk labels displayed in vContinuum may not map to the same disk in the physical server. For example, the label disk0 displayed in vContinuum may not map to the Linux physical disk /dev/sda.
Step 3 ![]() Select the secondary site MT.
Select the secondary site MT.
Figure 4-28 Select the Secondary ESX and Master Target

•![]() Enter the secondary vSphere/vCenter IP address nd login credentials.
Enter the secondary vSphere/vCenter IP address nd login credentials.
•![]() Click Get Details to list the available MT(s).
Click Get Details to list the available MT(s).
•![]() Select the MT that will be used to protect the selected primary physical server(s).
Select the MT that will be used to protect the selected primary physical server(s).
•![]() Click Next to continue.
Click Next to continue.
Note ![]() The MT must be of the same OS family as the primary VM(s) it protects. If the primary VMs use Linux, then the MT must also be Linux. The same requirement exists for Windows servers.
The MT must be of the same OS family as the primary VM(s) it protects. If the primary VMs use Linux, then the MT must also be Linux. The same requirement exists for Windows servers.
Step 4 ![]() Configure the replication options and specify the secondary site datastore.
Configure the replication options and specify the secondary site datastore.
Figure 4-29 Configure Replication Options and Select Datastore

•![]() In the Process server IP field, select the process server located in the primary network (for example, enterprise). The process server is used for both virtual and physical volume replication. Multiple process servers can be deployed for scale.
In the Process server IP field, select the process server located in the primary network (for example, enterprise). The process server is used for both virtual and physical volume replication. Multiple process servers can be deployed for scale.
•![]() In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
•![]() In the Retention Drive field, select the Windows drive letter or Linux mount point that is associated with the retention drive on the MT.
In the Retention Drive field, select the Windows drive letter or Linux mount point that is associated with the retention drive on the MT.
•![]() In the Retention (in days) field, enter the maximum number of days to store retention data.
In the Retention (in days) field, enter the maximum number of days to store retention data.
•![]() In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the primary VMs. This value determines the RPO for consistent point-based recovery.
In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the primary VMs. This value determines the RPO for consistent point-based recovery.
•![]() Click Next to continue.
Click Next to continue.
Note ![]() The amount of retention data can be limited by disk space, time, or both. The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settings page.
The amount of retention data can be limited by disk space, time, or both. The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settings page.
Step 5 ![]() Run the readiness check to finalize the offline sync export plan.
Run the readiness check to finalize the offline sync export plan.
Figure 4-30 Run the Offline Sync Import Plan

•![]() Click Run Readiness Checks to perform checks.
Click Run Readiness Checks to perform checks.
•![]() Enter a name for the protection plan.
Enter a name for the protection plan.
•![]() Click Protect to finalize the protection plan.
Click Protect to finalize the protection plan.
Step 6 ![]() Monitor the protection plan status from the CX UI.
Monitor the protection plan status from the CX UI.
Figure 4-31 Figure 4-31. Monitor the Offline Sync Export Status using the CX UI

Note ![]() Volume replication is complete when all volume replications achieve Differential Sync status. Step 7 Remove the MT from the vSphere/vCenter inventory.
Volume replication is complete when all volume replications achieve Differential Sync status. Step 7 Remove the MT from the vSphere/vCenter inventory.
Figure 4-32 Figure 4-32. Remove the Master Target from vSphere/vCenter Inventory
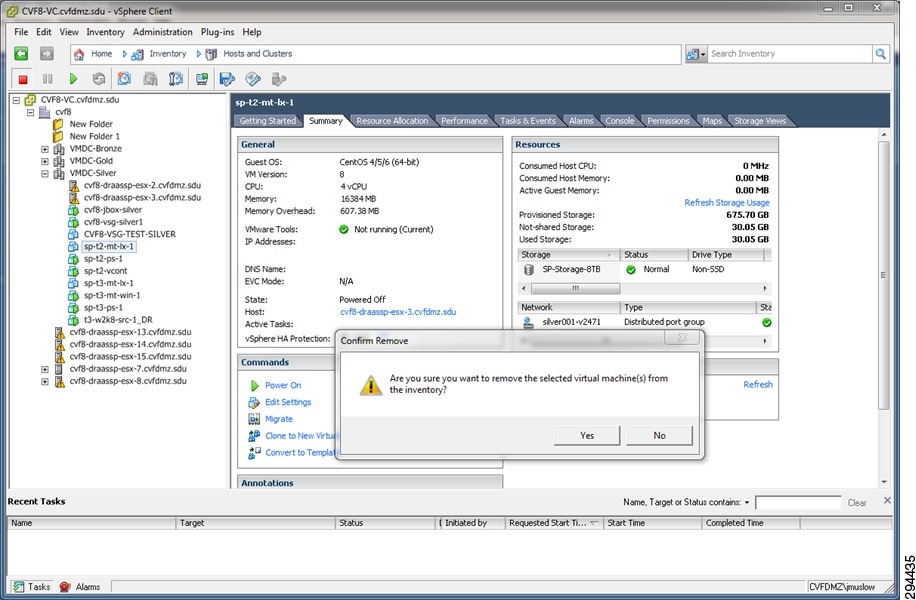
Note ![]() The MT should be powered off, then removed from the vSphere/vCenter inventory prior performing Offline Sync Import. Refer to "Offline Sync Import" sectionfor details on Offline Sync Import.
The MT should be powered off, then removed from the vSphere/vCenter inventory prior performing Offline Sync Import. Refer to "Offline Sync Import" sectionfor details on Offline Sync Import.
Offline Sync Import
Note ![]() The following steps to configure offline sync import are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to configure offline sync import are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Create an offline sync import plan using the vContinuum wizard.
Create an offline sync import plan using the vContinuum wizard.
2. ![]() Select the vSphere host and datastore.
Select the vSphere host and datastore.
3. ![]() Monitor the offline sync import plan in vContinuum.
Monitor the offline sync import plan in vContinuum.
4. ![]() Power on the MT.
Power on the MT.
Detailed Steps
Step 1 ![]() Create an offline sync import plan using the vContinuum wizard.
Create an offline sync import plan using the vContinuum wizard.
Figure 4-33 Create the Offline Sync Import Workflow using vContinuum

•![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum.
•![]() Select P2V from the Choose Application drop-down list for P2V protection plan.
Select P2V from the Choose Application drop-down list for P2V protection plan.
•![]() Enter the CX server IP address and port number (default is 80).
Enter the CX server IP address and port number (default is 80).
•![]() Select Offline Sync and OfflineSync Import to create the offline sync import workflow.
Select Offline Sync and OfflineSync Import to create the offline sync import workflow.
•![]() Select the primary physical server(s) to import.
Select the primary physical server(s) to import.
•![]() Click Next to continue.
Click Next to continue.
Step 2 ![]() Select the vSphere host and datastore.
Select the vSphere host and datastore.
Figure 4-34 Configure the Secondary vSphere Server and Select the vSphere Host and Datastore

•![]() Enter the secondary vSphere/vCenter IP aaddress and login credentials.
Enter the secondary vSphere/vCenter IP aaddress and login credentials.
•![]() Click Get Details to list the availble vSphere hosts and MT datastores.
Click Get Details to list the availble vSphere hosts and MT datastores.
•![]() Select the vSphere ESX Host.
Select the vSphere ESX Host.
•![]() Select the MT Datastore.
Select the MT Datastore.
•![]() Click Import to continue.
Click Import to continue.
Note ![]() The exported data from the offline sync export plan was copied to the temporary staging folder on the secondary site MT and datastore. Therefore, the data transfer step via removable media is not required in this example.
The exported data from the offline sync export plan was copied to the temporary staging folder on the secondary site MT and datastore. Therefore, the data transfer step via removable media is not required in this example.
Step 3 ![]() Monitor the offline sync import plan in vContinuum.
Monitor the offline sync import plan in vContinuum.
Figure 4-35 Run the Offline Sync Import Workflow

•![]() Click Done once the import operation is completed. Step 4 Power on the MT.
Click Done once the import operation is completed. Step 4 Power on the MT.
Figure 4-36 Monitor the VMs on the Secondary vSphere vCenter

Note ![]() The offline sync import process is complete once the MT VM is added back to vSphere/vCenter inventory and powered on.
The offline sync import process is complete once the MT VM is added back to vSphere/vCenter inventory and powered on.
Recovery Workflows
Once a protection plan is in place, the recover operation can be used to recover a primary server in a secondary vSphere environment when a disaster event occurs. This operation creates a VM on the secondary vSphere server based on a snapshot of the primary server. The snapshots can be based on the following consistency points or points in time:
•![]() Latest application consistent point
Latest application consistent point
•![]() Latest point in time
Latest point in time
•![]() Consistency point near (prior to) any given time
Consistency point near (prior to) any given time
•![]() Specific time
Specific time
Figure 4-37 Primary Server Recovery Overview

Note ![]() The following steps to recover a primary server are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to recover a primary server are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Start the vContinuum wizard application:
Start the vContinuum wizard application:
a. ![]() Select VM(s) to recover.
Select VM(s) to recover.
b. ![]() Specify snapshot to use based on time or tag.
Specify snapshot to use based on time or tag.
c. ![]() Perform Readiness Check to make sure the VM(s) are ready for recovery.
Perform Readiness Check to make sure the VM(s) are ready for recovery.
d. ![]() Configure network, hardware, and display name for new VM(s).
Configure network, hardware, and display name for new VM(s).
e. ![]() Specify recovery job type and time to execute.
Specify recovery job type and time to execute.
f. ![]() Finalize recovery and execute.
Finalize recovery and execute.
2. ![]() Monitor recovery.
Monitor recovery.
Detailed Steps
Step 1 ![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start > Program > InMage System > VContinuum > vContinuum.
a. ![]() Select ESX from the Choose Application drop-down list to view V2V protection plans or P2V for P2V.
Select ESX from the Choose Application drop-down list to view V2V protection plans or P2V for P2V.
b. ![]() Enter the CX server IP address and port number (default is 80) and then click Get Plans.
Enter the CX server IP address and port number (default is 80) and then click Get Plans.
c. ![]() Select the Manage Plans radio button and then click Recover.
Select the Manage Plans radio button and then click Recover.
Figure 4-38 Starting Recover on vContinuum

d. ![]() Select the primary VM(s) to recover and then click Next.
Select the primary VM(s) to recover and then click Next.
Figure 4-39 Selecting Primary VMs for Recovery

e. ![]() Specify snapshot to use based on time or tag:
Specify snapshot to use based on time or tag:
–![]() Latest Tag: Select this option to recover a VM to a latest tag that is common across all volumes of a VM. For example, if a VM that has three volumes (for example, C, E, and F), the latest common tag that is available across all volumes at same time point across all volumes is used.
Latest Tag: Select this option to recover a VM to a latest tag that is common across all volumes of a VM. For example, if a VM that has three volumes (for example, C, E, and F), the latest common tag that is available across all volumes at same time point across all volumes is used.
–![]() Latest Time: Select this option to recover a VM to a latest common point time among all volumes of a VM. Only common time points where volumes are in green state (data mode) are considered. For example, if a VM that has three volumes (for example, C, E, and F), the latest common time where all three volumes are in green state (data mode) is used.
Latest Time: Select this option to recover a VM to a latest common point time among all volumes of a VM. Only common time points where volumes are in green state (data mode) are considered. For example, if a VM that has three volumes (for example, C, E, and F), the latest common time where all three volumes are in green state (data mode) is used.
–![]() Tag at Specified Time (Source Time Zone): Select this option to recover a VM to a common tag prior to the specified time. For example, if a VM that has three volumes (for example, C, E, and F), the latest tag available prior to that time is used. The time provided is converted to GMT and compared against the timestamps in the retention logs. The closest consistency point prior to the time provided will be used to recover the VM.
Tag at Specified Time (Source Time Zone): Select this option to recover a VM to a common tag prior to the specified time. For example, if a VM that has three volumes (for example, C, E, and F), the latest tag available prior to that time is used. The time provided is converted to GMT and compared against the timestamps in the retention logs. The closest consistency point prior to the time provided will be used to recover the VM.
–![]() Specific Time (Source Time Zone): Select this option to recover a VM to a common point in time among all volumes of a VM. The time provided is converted to GMT and compared against the time stamps of the primary server. All recovery times are based on primary server's time stamps and not the secondary or management console times.
Specific Time (Source Time Zone): Select this option to recover a VM to a common point in time among all volumes of a VM. The time provided is converted to GMT and compared against the time stamps of the primary server. All recovery times are based on primary server's time stamps and not the secondary or management console times.
Note ![]() Click Apply for all VMs to perform the recovery for all VMs at the specified snapshot type.
Click Apply for all VMs to perform the recovery for all VMs at the specified snapshot type.
f. ![]() Click Run Readiness Check to make sure the VM(s) are ready for recovery. If the check passes, click Next to advance to the next page.
Click Run Readiness Check to make sure the VM(s) are ready for recovery. If the check passes, click Next to advance to the next page.
Figure 4-40 Running Readiness Check for Recovery

g. ![]() Configure network and hardware settings for the new VM(s) if these configurations need to be different than what was defined in the original protection plan. In Figure 4-41, no changes were made to the settings in the protection plan. Click Next to move to the next page.
Configure network and hardware settings for the new VM(s) if these configurations need to be different than what was defined in the original protection plan. In Figure 4-41, no changes were made to the settings in the protection plan. Click Next to move to the next page.
Figure 4-41 Modifying Network and Hardware Settings for Recovery

h. ![]() Select the order in which the new VMs should be powered up. For example, if some VM(s) are dependent on another VM to up and running before they should power up, then you want to have the dependent VM(s) power up last. The default Recover Order is all "1" and all VM(s) will be powered up within seconds of each other.
Select the order in which the new VMs should be powered up. For example, if some VM(s) are dependent on another VM to up and running before they should power up, then you want to have the dependent VM(s) power up last. The default Recover Order is all "1" and all VM(s) will be powered up within seconds of each other.
i. ![]() Specify recovery job type and time to execute based on one of the following three ways:
Specify recovery job type and time to execute based on one of the following three ways:
–![]() Recovery Option set to Recovery Now, Recovery Through set to FX Job, and plan name entered into Recovery Plan Name.
Recovery Option set to Recovery Now, Recovery Through set to FX Job, and plan name entered into Recovery Plan Name.
–![]() Recovery Option set to Recovery Now, Recovery Through set to WMI Based, and no plan name required.
Recovery Option set to Recovery Now, Recovery Through set to WMI Based, and no plan name required.
–![]() Recovery Option set to Recovery Later, and plan name entered into Recovery Plan Name. If you select Recovery Later, an FX job is created, which can manually started at any time.
Recovery Option set to Recovery Later, and plan name entered into Recovery Plan Name. If you select Recovery Later, an FX job is created, which can manually started at any time.
In Figure 4-42, the recover operation is configured for an immediate WMI-based recovery.
Figure 4-42 Finalizing Recover Operation

j. ![]() Click Recover to start the recovery operation.
Click Recover to start the recovery operation.
k. ![]() Monitor recovery.
Monitor recovery.
After starting the recovery, vContinuum goes through several steps to execute the recovery, which can be monitored from the status window.
Figure 4-43 Recover Starting (vContinuum)

Figure 4-44 Recover Monitoring (vContinuum)

Figure 4-45 Recovered VM (Service Provider vCenter)

Note ![]() Before executing the recovery, ensure that sufficient resources (for example, memory, CPU) are available on the target ESX/ESXi. If there are insufficient resources, the recovered VMs cannot be powered on and will have to be manually powered on.
Before executing the recovery, ensure that sufficient resources (for example, memory, CPU) are available on the target ESX/ESXi. If there are insufficient resources, the recovered VMs cannot be powered on and will have to be manually powered on.
Failback Protection Workflows
Prepare a MT on the primary vSphere server before starting the protection. Failback operation replicates any new changes made on the secondary VMs back to the primary VM after failover. Failback can be done only on those VMs that are failed over to the secondary server. Replication pairs are set from secondary VMs running on secondary vSphere to the MT running on primary vSphere server.
Figure 4-46 Failback Protection Overview

This section includes the following topics:
•![]() Virtual-to-Physical (V2P) Failback Protection
Virtual-to-Physical (V2P) Failback Protection
Virtual Failback Protection
Note ![]() The following steps to configure and execute a failback recovery are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to configure and execute a failback recovery are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Create failback protection plan.
Create failback protection plan.
a. ![]() Start vContinuum wizard application.
Start vContinuum wizard application.
b. ![]() Select secondary VM(s) for failback recovery.
Select secondary VM(s) for failback recovery.
c. ![]() Select MT on primary vSphere/vCenter server.
Select MT on primary vSphere/vCenter server.
d. ![]() Finalize protection plan.
Finalize protection plan.
2. ![]() Monitor failback protection.
Monitor failback protection.
3. ![]() Execute failback recovery.
Execute failback recovery.
a. ![]() Specify snapshot to use based on time or tag.
Specify snapshot to use based on time or tag.
b. ![]() Perform Readiness Check to make sure the VM(s) are ready for DR Drill.
Perform Readiness Check to make sure the VM(s) are ready for DR Drill.
c. ![]() Configure network, hardware, and display name for new VM(s).
Configure network, hardware, and display name for new VM(s).
d. ![]() Select datastore(s) for new VM(s).
Select datastore(s) for new VM(s).
e. ![]() Enter failback recovery plan name and initiate drill.
Enter failback recovery plan name and initiate drill.
4. ![]() Monitor failback recovery.
Monitor failback recovery.
Detailed Steps
Step 1 ![]() Create failback protection plan.
Create failback protection plan.
a. ![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
b. ![]() Select ESX from the Choose Application drop-down list to view V2V protection plans.
Select ESX from the Choose Application drop-down list to view V2V protection plans.
c. ![]() Enter the CX server IP address and port number (default is 80), then click Get Plans.
Enter the CX server IP address and port number (default is 80), then click Get Plans.
d. ![]() Select the Manage Plans radio button and then click Failback Protection.
Select the Manage Plans radio button and then click Failback Protection.
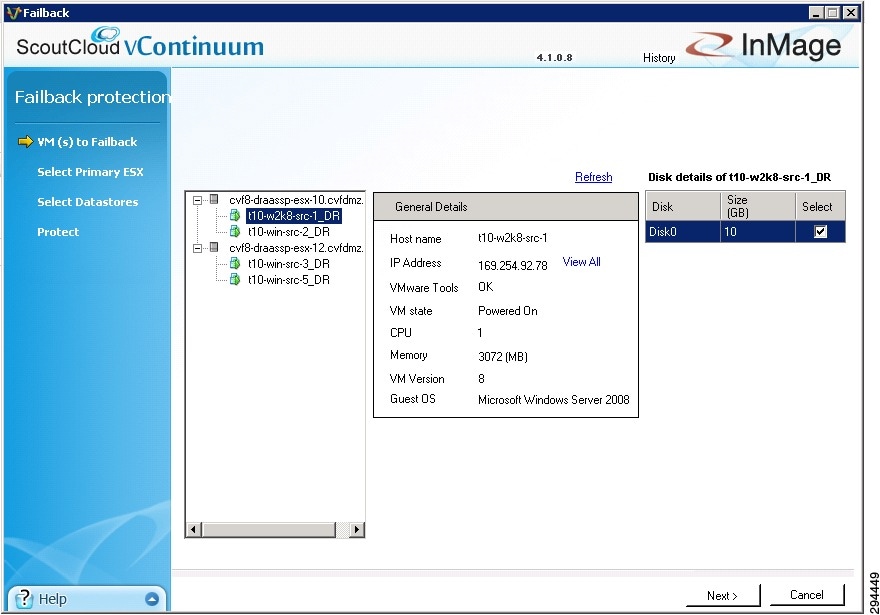
e. ![]() Select the secondary VM(s) for failback recovery and click Next.
Select the secondary VM(s) for failback recovery and click Next.
Figure 4-47 Starting Failback Recovery Protection on vContinuum

f. ![]() Verify the selected secondary VM(s) for failback recovery and click Next.
Verify the selected secondary VM(s) for failback recovery and click Next.
Figure 4-48 Verify Secondary VM(s) Selected for Failback Protection
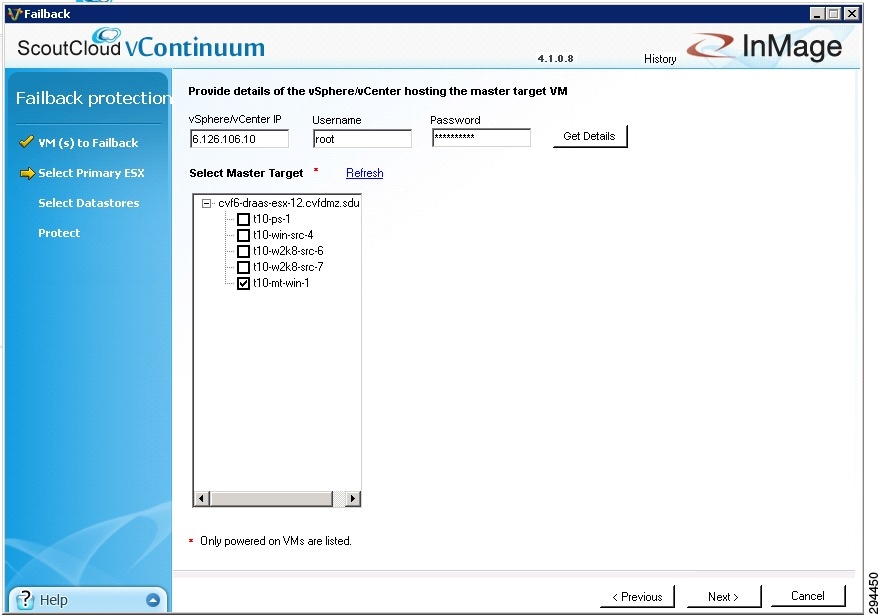
g. ![]() Enter the primary vSphere/vCenter IP address, Username, and Password, then click Get Details to view the available MT(s).
Enter the primary vSphere/vCenter IP address, Username, and Password, then click Get Details to view the available MT(s).
Note ![]() The MT must be of the same OS family as the secondary VM(s) it protects. If the secondary VMs use Windows, then the MT must also be Windows. The same requirement exists for Linux servers. For more information on MT considerations, refer to Master Target—Enterprise and Service Provider, page 3-1.
The MT must be of the same OS family as the secondary VM(s) it protects. If the secondary VMs use Windows, then the MT must also be Windows. The same requirement exists for Linux servers. For more information on MT considerations, refer to Master Target—Enterprise and Service Provider, page 3-1.
–![]() Select the MT that will be used to protect the selected secondary VM(s) and click Next.
Select the MT that will be used to protect the selected secondary VM(s) and click Next.
Figure 4-49 Selecting Primary Master Target(s)
h. ![]() Configure replication options.
Configure replication options.
–![]() In the Process server IP field, select the process server located in the secondary network (for example, SP). Multiple process servers can be deployed and associated with a limited number of secondary VMs for scalability.
In the Process server IP field, select the process server located in the secondary network (for example, SP). Multiple process servers can be deployed and associated with a limited number of secondary VMs for scalability.
–![]() In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
In the Retention size (in MB) field, enter the maximum amount of disk space to use for retention data.
–![]() In the Retention Drive field, select the drive letter that is associated with the retention drive on the MT.
In the Retention Drive field, select the drive letter that is associated with the retention drive on the MT.
–![]() In the Retention (in days) field, enter the maximum number of days to store retention data.
In the Retention (in days) field, enter the maximum number of days to store retention data.
Note![]() •
•![]() The amount of retention data can be limited by disk space, time, or both. For more information on retention data considerations, refer to "Retention Volume Sizing" section on page 3-3.
The amount of retention data can be limited by disk space, time, or both. For more information on retention data considerations, refer to "Retention Volume Sizing" section on page 3-3.
•![]() The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settings page.
The vContinuum wizard release used during testing (v.4.1.0.0) did not allow the user to configure the retention window lower than one day. If a retention window smaller than one day is desired, the retention window can be later adjusted to less than one day through the CX UI in the Protect > Volume > Settings page.
–![]() In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the secondary VMs. This value determines the RPO for consistency point based recovery.
In the Consistency interval (in mins) field, enter the number of minutes between execution of the replication jobs. The replication jobs will run every x minutes generating application consistency recovery points for the secondary VMs. This value determines the RPO for consistency point based recovery.
i. ![]() Select the target datastores in primary vCenter to create recovery VM(s) and click Next.
Select the target datastores in primary vCenter to create recovery VM(s) and click Next.
Figure 4-50 Selecting Datastores in Secondary vCenter

j. ![]() Finalize failback protection plan.
Finalize failback protection plan.
–![]() Click Run Readiness Checks to perform checks.
Click Run Readiness Checks to perform checks.
–![]() Enter a name for the failback protection plan.
Enter a name for the failback protection plan.
–![]() Click Protect to finalize the failback protection plan.
Click Protect to finalize the failback protection plan.
Figure 4-51 Finalize Protection Plan

Step 2 ![]() Monitor protection plan. After finalizing the failback protection plan, vContinuum goes through several steps to put the protection plan in place. The initialization of the protection plan can be monitored from the status window.
Monitor protection plan. After finalizing the failback protection plan, vContinuum goes through several steps to put the protection plan in place. The initialization of the protection plan can be monitored from the status window.
Figure 4-52 Failback Protection Plan Initializing (vContinuum)

Figure 4-53 Recover Monitoring (vContinuum)

Figure 4-54 Failback Replication Syncing (CX UI)

Step 3 ![]() Once the failback protection plan is completed and replication synced, a failback recovery can be executed.
Once the failback protection plan is completed and replication synced, a failback recovery can be executed.
a. ![]() Select ESX from the Choose Application drop-down list to view V2V protection plans.
Select ESX from the Choose Application drop-down list to view V2V protection plans.
b. ![]() Enter the CX server's IP address and port number (default is 80), then click Get Plans.
Enter the CX server's IP address and port number (default is 80), then click Get Plans.
c. ![]() Select the Manage Plans radio button and then click Recover.
Select the Manage Plans radio button and then click Recover.
d. ![]() Select the secondary VM(s) for failback recovery and then click Next.
Select the secondary VM(s) for failback recovery and then click Next.
Figure 4-55 Starting Failback Recovery on vContinuum

e. ![]() Specify snapshot to use based on time or tag.
Specify snapshot to use based on time or tag.
–![]() Latest Tag: Select this option to recover a VM to a latest tag that is common across all volumes of a VM. For example, if a VM that has three volumes (for example, C, E, and F), the latest common tag that is available across all volumes at same time point across all volumes is used.
Latest Tag: Select this option to recover a VM to a latest tag that is common across all volumes of a VM. For example, if a VM that has three volumes (for example, C, E, and F), the latest common tag that is available across all volumes at same time point across all volumes is used.
–![]() Latest Time: Select this option to recover a VM to a latest common point time among all volumes of a VM. Only common time points where volumes are in green state (data mode) are considered. For example, if a VM that has three volumes (for example, C, E, and F), the latest common time where all three volumes are in green state (data mode) is used.
Latest Time: Select this option to recover a VM to a latest common point time among all volumes of a VM. Only common time points where volumes are in green state (data mode) are considered. For example, if a VM that has three volumes (for example, C, E, and F), the latest common time where all three volumes are in green state (data mode) is used.
–![]() Tag at Specified Time (Source Time Zone): Select this option to recover a VM to a common tag prior to the specified time. For example, if a VM that has three volumes (for example, C, E, and F), the latest tag available prior to that time is used. The time provided is converted to GMT and compared against the timestamps in the retention logs. The closest consistency point prior to the time provided will be used to recover the VM.
Tag at Specified Time (Source Time Zone): Select this option to recover a VM to a common tag prior to the specified time. For example, if a VM that has three volumes (for example, C, E, and F), the latest tag available prior to that time is used. The time provided is converted to GMT and compared against the timestamps in the retention logs. The closest consistency point prior to the time provided will be used to recover the VM.
–![]() Specific Time (Source Time Zone): Select this option to recover a VM to a common point in time among all volumes of a VM. The time provided is converted to GMT and compared against the time stamps of the secondary server. All recovery times are based on secondary server's time stamps and not the primary or management console times
Specific Time (Source Time Zone): Select this option to recover a VM to a common point in time among all volumes of a VM. The time provided is converted to GMT and compared against the time stamps of the secondary server. All recovery times are based on secondary server's time stamps and not the primary or management console times
Note ![]() Click Apply for all VMs to perform the recovery for all VMs at the specified snapshot type.
Click Apply for all VMs to perform the recovery for all VMs at the specified snapshot type.
f. ![]() Click Run Readiness Check to make sure the VM(s) are ready for recovery. If the check passes, click Next to advance to the next page.
Click Run Readiness Check to make sure the VM(s) are ready for recovery. If the check passes, click Next to advance to the next page.
Figure 4-56 Running Readiness Check for Failback Recovery

g. ![]() Configure network and hardware settings for the new VM(s) if these configurations need to be different than what was defined in the original protection plan. In Figure 4-57, no changes were made to the settings in the protection plan. Click Next to move to the next page.
Configure network and hardware settings for the new VM(s) if these configurations need to be different than what was defined in the original protection plan. In Figure 4-57, no changes were made to the settings in the protection plan. Click Next to move to the next page.
Figure 4-57 Modifying Network and Hardware Settings for Failback Recovery

h. ![]() Select the order the new VMs should be powered up in. For example, if some VM(s) are dependent on another VM to up and running before they should power up, then you want to have the dependent VM(s) power up last. The default Recover Order is all "1" and all VM(s) will be powered up within seconds of each other.
Select the order the new VMs should be powered up in. For example, if some VM(s) are dependent on another VM to up and running before they should power up, then you want to have the dependent VM(s) power up last. The default Recover Order is all "1" and all VM(s) will be powered up within seconds of each other.
i. ![]() Specify recovery job type and time to execute based on one of the following three ways:
Specify recovery job type and time to execute based on one of the following three ways:
–![]() Recovery Option set to Recovery Now, Recovery Through set to FX Job, and plan name entered into Recovery Plan Name.
Recovery Option set to Recovery Now, Recovery Through set to FX Job, and plan name entered into Recovery Plan Name.
–![]() Recovery Option set to Recovery Now, Recovery Through set to WMI Based, and no plan name required.
Recovery Option set to Recovery Now, Recovery Through set to WMI Based, and no plan name required.
–![]() Recovery Option set to Recovery Later, and plan name entered into Recovery Plan Name. If you select Recovery Later, an FX job is created, which can manually started at any time.
Recovery Option set to Recovery Later, and plan name entered into Recovery Plan Name. If you select Recovery Later, an FX job is created, which can manually started at any time.
In Figure 4-58, the recover operation is configured for an immediate WMI-based recovery. The powering up of the servers will be staggered with T10-W2K8-SRC-1 first, T10-WINSRC-2 second, and both T10-WIN-SRC3 and T10-WIN-SRC-5 third.
Figure 4-58 Finalizing Recover Operation

Figure 4-59 Primary Master Target Credentials Required

Note ![]() The protection plans for recovery and failback recovery no londer exist in vContinuum or the CX UI. A new recovery protection plan needs to be created to re-establish disaster recovery protection.
The protection plans for recovery and failback recovery no londer exist in vContinuum or the CX UI. A new recovery protection plan needs to be created to re-establish disaster recovery protection.
Virtual-to-Physical (V2P) Failback Protection
Failback operation replicates any new changes made on the secondary VMs back to the primary physical server after failover. Failback can be done only on physical servers that are failed over to the secondary server. The V2P failback protection supports both Linux and Windows operating systems. A V2P failback of a physical server running CentOS is documented in this section.
Virtual to physical (V2P) failback protection has the following steps:
Step 1 ![]() Prepare the Physical Server.
Prepare the Physical Server.
•![]() Connect to the server console and boot from the InMage LiveCD. In this step, edit the physical server network, DNS, and firewall configurations.
Connect to the server console and boot from the InMage LiveCD. In this step, edit the physical server network, DNS, and firewall configurations.
Step 2 ![]() Prepare the USB disk.
Prepare the USB disk.
•![]() The minimum size of the USB disk should 8GB. The physical server will provide the MT function for the failback process. Because of this, the USB disk will be configured with two Linux partitions. The InMage Unified Agent is installed on the first partition and the MT retention drive is installed on the second partition.
The minimum size of the USB disk should 8GB. The physical server will provide the MT function for the failback process. Because of this, the USB disk will be configured with two Linux partitions. The InMage Unified Agent is installed on the first partition and the MT retention drive is installed on the second partition.
Step 3 ![]() Create the Failback protection plan.
Create the Failback protection plan.
•![]() The V2P failback is a similar to the protection plan, but in the reverse direction. The primary VM running in the secondary site is failed back to the physical server in the enterprise. The V2P failback plan uses the secondary site process server and the physical server as the MT.
The V2P failback is a similar to the protection plan, but in the reverse direction. The primary VM running in the secondary site is failed back to the physical server in the enterprise. The V2P failback plan uses the secondary site process server and the physical server as the MT.
Step 4 ![]() Run the Recovery plan.
Run the Recovery plan.
•![]() Run the failback recovery after the failback plan achieves differential sync status.
Run the failback recovery after the failback plan achieves differential sync status.
This section includes the following topics:
Prepare the Physical Server
Connect to the physical server console and boot from the InMage LiveCD. In this step, edit the physical server network, DNS, and firewall configurations.
Summary of Steps
1. ![]() Boot the InMage LiveCD and run Setup.
Boot the InMage LiveCD and run Setup.
2. ![]() Edit the physical server network configuration.
Edit the physical server network configuration.
3. ![]() Edit the physical server DNS configuration.
Edit the physical server DNS configuration.
4. ![]() Edit the physcial server firewall configuration.
Edit the physcial server firewall configuration.
5. ![]() Configure the physical server /etc/hosts file.
Configure the physical server /etc/hosts file.
6. ![]() Configure the physical server /etc/sysconfig/network file.
Configure the physical server /etc/sysconfig/network file.
7. ![]() Enable the physical server interface.
Enable the physical server interface.
8. ![]() Restart the network service.
Restart the network service.
Detailed Steps
Step 1 ![]() Boot the InMage LiveCD and run setup.
Boot the InMage LiveCD and run setup.
Figure 4-60 Run Setup to Configure Network and Firewall Configurations

Step 2 ![]() Edit the physical server network configuration:
Edit the physical server network configuration:
•![]() Configure the IP address.
Configure the IP address.
•![]() Configure the subnet mask.
Configure the subnet mask.
•![]() Configure the gateway.
Configure the gateway.
Figure 4-61 Edit the Network Configuration

Step 3 ![]() Edit the physical server DNS configuration:
Edit the physical server DNS configuration:
•![]() Configure the hostname.
Configure the hostname.
Figure 4-62 Edit the DNS Configuration

Step 4 ![]() Edit the physical server firewall configuration:
Edit the physical server firewall configuration:
•![]() Disable the firewall service.
Disable the firewall service.
Figure 4-63 Disable the Firewall

Step 5 ![]() Configure the physical server /etc/hosts file. Add the hostname entry scoutlivecd to the /etc/hosts file.
Configure the physical server /etc/hosts file. Add the hostname entry scoutlivecd to the /etc/hosts file.
6.126.99.216 scoutlivecd scoutlivecd
127.0.0.1 localhost.localdomain localhost scoutlivecd::1 localhost.localdomain localhost6 localhost scoutlivecd
Step 6 ![]() Configure the physical server /etc/sysconfig/network file. Configure the hostname scoutlivecd to the /etc/sysconfig/network file
Configure the physical server /etc/sysconfig/network file. Configure the hostname scoutlivecd to the /etc/sysconfig/network file
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=scoutlivecd
Step 7 ![]() Enable the physical server interface. Set the ONBOOT option to Yes.
Enable the physical server interface. Set the ONBOOT option to Yes.
DEVICE=eth0 BOOTPROTO=none
ONBOOT=yes
NETMASK=255.255.255.192
TYPE=Ethernet
HWADDR=e8:b7:48:4e:10:2e
IPADDR=6.126.99.216
GATEWAY=6.126.99.199
IPV6INIT=no USERCTL=no
Step 8 ![]() Restart the network service.
Restart the network service.
service network restart
Prepare the USB Flash Drive
The minimum size of the USB disk should 8GB. The physical server will provide the MT function for the failback process. Because of this, the USB disk will be configured with two Linux partitions. The InMage Unified Agent is installed on the first partition and the MT retention folder is installed on the second partition.
Summary of Steps
1. ![]() Insert the USB disk into the physical server and copy the InMage Unified Agent onto the USB disk.
Insert the USB disk into the physical server and copy the InMage Unified Agent onto the USB disk.
2. ![]() List the server's available disk devices.
List the server's available disk devices.
3. ![]() Create the disk partition for the InMage Unified Agent on the USB disk.
Create the disk partition for the InMage Unified Agent on the USB disk.
4. ![]() Create the disk partition for the InMage Retention Folder on the USB disk.
Create the disk partition for the InMage Retention Folder on the USB disk.
5. ![]() Verify the newly created USB disk partitions.
Verify the newly created USB disk partitions.
6. ![]() Create the directories to be mount points for the two USB disk partitions.
Create the directories to be mount points for the two USB disk partitions.
7. ![]() Format the newly created USB disk partitions.
Format the newly created USB disk partitions.
8. ![]() Mount the newly created USB disk partitions.
Mount the newly created USB disk partitions.
9. ![]() Install the InMage Unified Agent software.
Install the InMage Unified Agent software.
10. ![]() Run the InMage Unified Agent install script.
Run the InMage Unified Agent install script.
11. ![]() Agree to the license terms and conditions
Agree to the license terms and conditions
12. ![]() Specify where to install the Unified Agent installation software.
Specify where to install the Unified Agent installation software.
13. ![]() Configure the primary role of Scout Agent.
Configure the primary role of Scout Agent.
14. ![]() Configure the host agent Global settings.
Configure the host agent Global settings.
15. ![]() Configure the host agent Agent setings.
Configure the host agent Agent setings.
Detailed Steps
Step 1 ![]() Insert the USB disk into the physical server. Insert the USB disk and copy the InMage Unified Agent onto the USB disk.
Insert the USB disk into the physical server. Insert the USB disk and copy the InMage Unified Agent onto the USB disk.
Step 2 ![]() List the server's available disk devices.
List the server's available disk devices.
[root@scoutlivecd /]# fdisk -l
Disk /dev/sda: 299.0 GB, 298999349248 bytes 255 heads, 63 sectors/track, 36351 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00023254
Device Boot Start End Blocks Id System
/dev/sda1 * 1 64 512000 83 Linux Partition 1 does not end on cylinder boundary.
/dev/sda2 64 36352 291478528 8e Linux LVM
Disk /dev/sdb: 200.0 GB, 200049647616 bytes 255 heads, 63 sectors/track, 24321 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x393e8c41
Device Boot Start End Blocks Id System
Note![]() •
•![]() The fdisk -l option is used to list the partition table(s).
The fdisk -l option is used to list the partition table(s).
•![]() /dev/sda is the original disk partition, and /dev/sdb is the USB disk.
/dev/sda is the original disk partition, and /dev/sdb is the USB disk.
Step 3 ![]() Create the disk partition for the InMage Unified Agent on the USB disk.
Create the disk partition for the InMage Unified Agent on the USB disk.
[root@scoutlivecd /]# fdisk /dev/sdb
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to sectors (command 'u').
Command (m for help): n Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-24321, default 1): Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-24321, default 24321): +3126M
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Note![]() •
•![]() The fdisk <disk> is used to change the partition table(s).
The fdisk <disk> is used to change the partition table(s).
•![]() Create a 3 GB primary partition on the USB disk that will contain the InMage Agent software.
Create a 3 GB primary partition on the USB disk that will contain the InMage Agent software.
Step 4 ![]() Create the disk partition for the InMage Retention Folder on the USB disk.
Create the disk partition for the InMage Retention Folder on the USB disk.
[root@scoutlivecd /]# fdisk /dev/sdb
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to switch off the mode (command 'c') and change display units to sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (401-24321, default 401):
Using default value 401
Last cylinder, +cylinders or +size{K,M,G} (401-24321, default 24321):
Using default value 24321
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table. Syncing disks.
Note![]() •
•![]() The fdisk <disk> is used to change the partition table(s).
The fdisk <disk> is used to change the partition table(s).
•![]() Create the second primary partition on the remaining free space of the USB disk. This partition will contain the MT retention folder.
Create the second primary partition on the remaining free space of the USB disk. This partition will contain the MT retention folder.
Step 5 ![]() Verify the newly created USB disk partitions.
Verify the newly created USB disk partitions.
[root@scoutlivecd /]# fdisk -l /dev/sdb
Disk /dev/sdb: 200.0 GB, 200049647616 bytes 255 heads, 63 sectors/track, 24321 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x393e8c41
Device Boot Start End Blocks Id System
/dev/sdb1 1 400 3212968+ 83 Linux
/dev/sdb2 401 24321 192145432+ 83 Linux
Note![]() •
•![]() The fdisk -l option is used to list the partition table(s).
The fdisk -l option is used to list the partition table(s).
•![]() /dev/sdb1 is used for the InMage Unified Agent software
/dev/sdb1 is used for the InMage Unified Agent software
•![]() /dev/sdb2 is used for the InMage MT retention drive
/dev/sdb2 is used for the InMage MT retention drive
Step 6 ![]() Create the directories to be mount points for the two USB disk partitions.
Create the directories to be mount points for the two USB disk partitions.
[root@scoutlivecd /]# mkdir /mnt/InMageAgent
[root@scoutlivecd /]# mkdir /mnt/InMageCDP
Note![]() •
•![]() /mnt/InMageAgent is used for the InMage Unified Agent Software
/mnt/InMageAgent is used for the InMage Unified Agent Software
•![]() /mnt/InMageCDP is used for the MT retention folder
/mnt/InMageCDP is used for the MT retention folder
Step 7 ![]() Format the newly created USB disk partitions.
Format the newly created USB disk partitions.
[root@scoutlivecd /]# mkfs.ext3 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
201200 inodes, 803242 blocks
40162 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=826277888
25 block groups
32768 blocks per group, 32768 fragments per group
8048 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 38 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@scoutlivecd /]# mkfs.ext3 /dev/sdb2
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
12009472 inodes, 48036358 blocks
2401817 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
1466 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 38 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
Note![]() •
•![]() The mkfs.ext3 command is used to format the partitions
The mkfs.ext3 command is used to format the partitions
•![]() /dev/sdb1 contains the InMage Unified Agent software
/dev/sdb1 contains the InMage Unified Agent software
•![]() /dev/sdb2 contains the InMage MT retention folder
/dev/sdb2 contains the InMage MT retention folder
Step 8 ![]() Mount the newly created USB disk partitions.
Mount the newly created USB disk partitions.
[root@scoutlivecd /]# mount /dev/sdb1 /mnt/InMageAgent
[root@scoutlivecd /]# mount /dev/sdb2 /mnt/InMageCDP
Note![]() •
•![]() The mount command is used to mount the partitions
The mount command is used to mount the partitions
•![]() /dev/sdb1 contains the InMage Unified Agent software
/dev/sdb1 contains the InMage Unified Agent software
•![]() /dev/sdb2 contains the InMage MT retention folder
/dev/sdb2 contains the InMage MT retention folder
Step 9 ![]() Install the InMage Unified Agent software.
Install the InMage Unified Agent software.
•![]() The tar command is used to extract the Unified Agent binary.
The tar command is used to extract the Unified Agent binary.
•![]() Extract the files the newly created USB disk partition mounted to the /mnt/InMage/Agent directory.
Extract the files the newly created USB disk partition mounted to the /mnt/InMage/Agent directory.
[root@scoutlivecd InMageAgent]# tar xvzf
InMage_UA_7.1.0.0_RHEL6-64_GA_14May2013_release.tar.gz
InMageFx-7.1.0.0-1.x86_64.rpm
InMageVx-7.1.0.0-1.x86_64.rpm
.fx_build_manifest
install
uninstall.sh
install_fx
install_vx
EULA.txt
conf_file
.vx_version
.fx_version
OS_details.sh
[root@scoutlivecd InMageAgent]#
Step 10 ![]() Run the InMage Unified Agent install script. Select option 3 to install both File and Volume replication agents.
Run the InMage Unified Agent install script. Select option 3 to install both File and Volume replication agents.
[root@scoutlivecd InMageAgent]# ./install
You can install the following :
File Replication Agent
Volume Replication Agent
Both
Please make your choice (1 or 2 or 3) here . Default [3]: 3
Step 11 ![]() Agree to the license terms and conditions. Enter Y to agree to the license terms and conditions.
Agree to the license terms and conditions. Enter Y to agree to the license terms and conditions.
Please press (Y/y) if you agree to the license terms and conditions: y
Step 12 ![]() Specify where to install the Unified Agent installation software. The agent software will be installed on the newly created USB disk partition.
Specify where to install the Unified Agent installation software. The agent software will be installed on the newly created USB disk partition.
Where do you want to install the InMage UA agent (default /usr/local/InMage) : /mnt/ InMageAgent
Step 13 ![]() Configure the primary role of Scout Agent. Select option 2 to set the primary role of this agent to MT.
Configure the primary role of Scout Agent. Select option 2 to set the primary role of this agent to MT.
What is the Primary Role of this Agent ?
Scout Agent
Select 'Scout Agent' for installation on servers that need to be protected, or for servers that act as targets in a failover/failback situation.
Master Target
Select 'Master Target' for installation on a VMWare VM that acts as the protection target for other protected physical or virtual servers.
Please make your choice ? (1/2) [Default: 1] 2
Step 14 ![]() Configure the host agent Global settings. Configure the IP address and port number of the CX server, the default port number is 80.
Configure the host agent Global settings. Configure the IP address and port number of the CX server, the default port number is 80.
+ +
| Host Config Interface | |Pick the command you wish to run. |
| Press ? for help. |
+ +
| Global Agent NAT Logging Quit |
+ + CX Server settings
+ +
| Enter IP Address |
|IP: 8.24.71.101 |
+ +
+ + |Enter Port number|
|Port: 80 |
+ +
Step 15 ![]() Configure the host agent Agent settings. Set the application cache directory to /mnt/InMageAgent.
Configure the host agent Agent settings. Set the application cache directory to /mnt/InMageAgent.
+ +
| Host Config Interface | |Pick the command you wish to run. |
| Press ? for help. |
+ +
| Global Agent NAT Logging Quit |
+ + VX Agent
+ +
| Application Cache Directory: |
|/mnt/InMageAgent |
+ +
+ |Note: Changing cache directory requires the following steps.
| Not following these steps can result into data loss. |
Stop svagents
Wait for svagent and child processes to stop completely
Create the new cache directory
Move contents from old cache directory to new cache directory
change cache directory using hostconfigcli/hostconfigui
start svagents
+
Create the V2P Failback Plan
Summary of Steps
1. ![]() Create failback protection plan.
Create failback protection plan.
2. ![]() Select secondary VM(s) disk to include in the failback protection plan.
Select secondary VM(s) disk to include in the failback protection plan.
3. ![]() Select the physical server.
Select the physical server.
4. ![]() Configure V2P failback replication options and finalize the failback protection plan.
Configure V2P failback replication options and finalize the failback protection plan.
5. ![]() Monitor failback protection plan.
Monitor failback protection plan.
Detailed Steps
Step 1 ![]() Create the failback protection plan.
Create the failback protection plan.
Figure 4-64 Create the V2P Failback Protection Plan in vContinuum

•![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
•![]() Select P2V from the Choose Application drop-down list to view V2P protection plans.
Select P2V from the Choose Application drop-down list to view V2P protection plans.
•![]() Enter the CX server IP address and port number (default is 80), then click Get Plans.
Enter the CX server IP address and port number (default is 80), then click Get Plans.
•![]() Select the Manage Plans radio button and click Failback Protection.
Select the Manage Plans radio button and click Failback Protection.
•![]() Select the secondary VM(s) for failback recovery.
Select the secondary VM(s) for failback recovery.
•![]() Click Next to continue.
Click Next to continue.
Step 2 ![]() Select secondary VM(s) disk to include in the failback protection plan.
Select secondary VM(s) disk to include in the failback protection plan.
Figure 4-65 Select the VM and VM Disk to Failback

Step 3 ![]() Select the physical server.
Select the physical server.
Figure 4-66 Select the Target Physical Server

•![]() Set the OS Type to Linux.
Set the OS Type to Linux.
•![]() Click Get details to list the primary physical servers available for failback.
Click Get details to list the primary physical servers available for failback.
•![]() Select the physical server booted with the Linux LiveCD.
Select the physical server booted with the Linux LiveCD.
•![]() Click Next to continue.
Click Next to continue.
Step 4 ![]() Configure V2P failback replication options and finalize the failback protection plan.
Configure V2P failback replication options and finalize the failback protection plan.
Figure 4-67 Select Physical Server Disk and Retention Policy

•![]() In the Process server IP field, select the process server located in the secondary site (for example, service provider).
In the Process server IP field, select the process server located in the secondary site (for example, service provider).
•![]() In the Retention Drive field, select the mount point /mnt/InMageAgent that is associated with the retention drive on the master target.
In the Retention Drive field, select the mount point /mnt/InMageAgent that is associated with the retention drive on the master target.
•![]() In the Retention (in days) field, enter the maximum number of days to store retention data.
In the Retention (in days) field, enter the maximum number of days to store retention data.
•![]() In the Consistency Interval field, enter the Consistency Interval in mins. Jobs will run every x minutes generating application consistency recovery points in primary VMs using which you can recover at the time of recovery. This value determines the RPO in case of consistency point-based recovery.
In the Consistency Interval field, enter the Consistency Interval in mins. Jobs will run every x minutes generating application consistency recovery points in primary VMs using which you can recover at the time of recovery. This value determines the RPO in case of consistency point-based recovery.
•![]() In the Select Target Disk field, select the physical server's target disk(s).
In the Select Target Disk field, select the physical server's target disk(s).
•![]() Click Next to continue.
Click Next to continue.
Step 5 ![]() Monitor the failback protection plan, wait for differential sync status.
Monitor the failback protection plan, wait for differential sync status.
Figure 4-68 Monitor the Failback Status

Note ![]() The failback protection is complete once all volume replications reach differential sync status.
The failback protection is complete once all volume replications reach differential sync status.
Recover the Physical Server
Note The following steps to configure and execute a failback recovery are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Create an failback recovery plan using the vContinuum wizard.
Create an failback recovery plan using the vContinuum wizard.
2. ![]() Select the VM(s) to recover.
Select the VM(s) to recover.
3. ![]() Configure the network settings for the physical server.
Configure the network settings for the physical server.
4. ![]() Configure the NIC properties.
Configure the NIC properties.
5. ![]() Run the recovery plan.
Run the recovery plan.
Detailed Steps
Step 1 ![]() Create an failback recovery plan using the vContinuum wizard.
Create an failback recovery plan using the vContinuum wizard.
Figure 4-69 Create the V2P Failback Recovery Plan in vContinuum

•![]() Select P2V from the Choose Application drop-down list to view V2P failback plans.
Select P2V from the Choose Application drop-down list to view V2P failback plans.
•![]() Enter the CX server IP address and port number (default is 80) and then click Get Plans.
Enter the CX server IP address and port number (default is 80) and then click Get Plans.
•![]() Select the Manage Plans radio button and then click Recover.
Select the Manage Plans radio button and then click Recover.
•![]() Select the secondary VM(s) for failback recovery.
Select the secondary VM(s) for failback recovery.
•![]() Click Next to continue.
Click Next to continue.
Step 2 ![]() Select the VM(s) to recover and specify whether to base the recovery on time or tag.
Select the VM(s) to recover and specify whether to base the recovery on time or tag.
Figure 4-70 Select Machines to Recover

•![]() Latest Tag: Selecting this option recovers to a latest tag that is common across all protected disks of a server. For example, consider a server that has three disks: /dev/sda,/dev/sdb,/dev/sdc. By using this option. you would recover to a latest common tag that is available across all disks at same point.
Latest Tag: Selecting this option recovers to a latest tag that is common across all protected disks of a server. For example, consider a server that has three disks: /dev/sda,/dev/sdb,/dev/sdc. By using this option. you would recover to a latest common tag that is available across all disks at same point.
•![]() Latest Time: Selecting this option recovers to a latest common point in time among all disks protected from a server. Only the latest common point in time where disks are in green state (data mode) is considered. For example, consider a server that has three disks: /dev/sda,/dev/sdb,/dev/ sdc. By using this option, you would recover to a latest common point in time where all three disks are in green state (data mode).
Latest Time: Selecting this option recovers to a latest common point in time among all disks protected from a server. Only the latest common point in time where disks are in green state (data mode) is considered. For example, consider a server that has three disks: /dev/sda,/dev/sdb,/dev/ sdc. By using this option, you would recover to a latest common point in time where all three disks are in green state (data mode).
•![]() Tag at Specified Time: Selecting this option recovers to a common tag prior to the specified time. For example, consider a server that has three disks: /dev/sda,/dev/sdb,/dev/sdc. By using this option, you would recover to a latest tag available prior to that time.
Tag at Specified Time: Selecting this option recovers to a common tag prior to the specified time. For example, consider a server that has three disks: /dev/sda,/dev/sdb,/dev/sdc. By using this option, you would recover to a latest tag available prior to that time.
•![]() Specified time: Selecting this option recovers to common point in time among all the disks protected by you.
Specified time: Selecting this option recovers to common point in time among all the disks protected by you.
Note ![]() Click Apply for all VMs to perform the recovery for all VMs at the specified snapshot type.
Click Apply for all VMs to perform the recovery for all VMs at the specified snapshot type.
Step 3 ![]() Configure the network settings for the physical server.
Configure the network settings for the physical server.
Figure 4-71 Configure the Network and Hardware Configurations

•![]() For each VM being recovered, click Change to configure the network configuration.
For each VM being recovered, click Change to configure the network configuration.
•![]() Click Next after all selected machines are configured.
Click Next after all selected machines are configured.
Note ![]() The network configuration can be assigned statically or dynamically via DHCP. When the physical server is recovered and powered on it will contain these new values provided. If no new network settings are provided, original settings will be retained.
The network configuration can be assigned statically or dynamically via DHCP. When the physical server is recovered and powered on it will contain these new values provided. If no new network settings are provided, original settings will be retained.
Step 4 ![]() Configure the NIC properties.
Configure the NIC properties.
Figure 4-72 Configure the NIC Properties

•![]() Select the NIC properties mode, static or dynamic (DHCP).
Select the NIC properties mode, static or dynamic (DHCP).
•![]() If NIC properties are set to static, configure the IP address, Subnet Mask, Gateway, and DNS server.
If NIC properties are set to static, configure the IP address, Subnet Mask, Gateway, and DNS server.
•![]() Configure the interface VLAN.
Configure the interface VLAN.
•![]() Click Add to continue.
Click Add to continue.
Step 5 ![]() Run the recovery plan.
Run the recovery plan.
Figure 4-73 Recover the Physical Server

•![]() Specify the recovery job type and time to execute based on one of the following two ways:
Specify the recovery job type and time to execute based on one of the following two ways:
•![]() Recovery Option set to Recovery Now, and plan name entered into Recovery Plan Name.
Recovery Option set to Recovery Now, and plan name entered into Recovery Plan Name.
•![]() Recovery Option set to Recovery Later, and plan name entered into Recovery Plan Name, a Recovery Later can be manually started at any time.
Recovery Option set to Recovery Later, and plan name entered into Recovery Plan Name, a Recovery Later can be manually started at any time.
Resume Protection Workflows
When a primary server is recovered at a secondary vCenter, two ways to switch back to the primary server exist:
•![]() The first is a resume operation and it will discard any changes that occurred while the secondary server was been online and bring the primary server back online and into the existing protection plan. The volume replication will continue based on the last recovery.
The first is a resume operation and it will discard any changes that occurred while the secondary server was been online and bring the primary server back online and into the existing protection plan. The volume replication will continue based on the last recovery.
•![]() The second is a failback operation and similar to the recover operation, the primary server will be created from a snapshot of the secondary server based on a consistency point or point in time.
The second is a failback operation and similar to the recover operation, the primary server will be created from a snapshot of the secondary server based on a consistency point or point in time.
In "Recovery Workflows" section, a single primary VM in a protection plan was recovered to the secondary vCenter. This can be seen in Figure 4-74 and will be the starting state for the resume protection discussion in this section.
Figure 4-74 Single VM Recovered to Secondary vCenter

Note ![]() The following steps to recover a primary server are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to recover a primary server are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() Start vContinuum wizard application.
Start vContinuum wizard application.
2. ![]() Select VM(s) for which to resume protection.
Select VM(s) for which to resume protection.
3. ![]() Finalize resume and execute.
Finalize resume and execute.
4. ![]() Monitor resume.
Monitor resume.
Detailed Steps
Step 1 ![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
a. ![]() Select ESX from the Choose Application drop-down list to view V2V protection plans or P2V for P2V.
Select ESX from the Choose Application drop-down list to view V2V protection plans or P2V for P2V.
b. ![]() Enter the CX server IP address and port number (default is 80), then click Get Plans. Looking at Figure 4-75, there are five primary servers in the Tenant9-V2V-W2K8-PP protection plan. Actually, the last server in the list was recently recovered to the secondary vCenter.
Enter the CX server IP address and port number (default is 80), then click Get Plans. Looking at Figure 4-75, there are five primary servers in the Tenant9-V2V-W2K8-PP protection plan. Actually, the last server in the list was recently recovered to the secondary vCenter.
Figure 4-75 Existing Plans on vContinuum

c. ![]() Select the Manage Plans radio button and then click Resume.
Select the Manage Plans radio button and then click Resume.
d. ![]() Select the primary VM t9-w2k8-src-1.
Select the primary VM t9-w2k8-src-1.
Figure 4-76 Selecting VM for Resume

e. ![]() Click Resume to start the resume operation.
Click Resume to start the resume operation.
Step 2 ![]() Monitor recovery. After starting the resume, vContinuum goes through a number of steps to execute the recovery, which can be monitored from the status window.
Monitor recovery. After starting the resume, vContinuum goes through a number of steps to execute the recovery, which can be monitored from the status window.
Figure 4-77 Resume Operation Started

Figure 4-78 Secondary VM Shutdown Confirmation

Figure 4-79 Secondary VM Shutdown in Secondary vCenter

Figure 4-80 Volume Resyncing After Resume

DR Drill Workflows
The Disaster Recovery (DR) Drill allows the administrator the ability to verify primary VM protection by creating a secondary VM using a physical snapshot from any of the following recovery points:
•![]() Latest application consistent point
Latest application consistent point
•![]() Latest point in time
Latest point in time
•![]() Consistency point near (prior to) any given time
Consistency point near (prior to) any given time
•![]() Specific time
Specific time
DR Drill does not impact protection pairs, so all VMs currently under protection will remain protected while the DR Drill is being performed.
Figure 4-81 DR Drill Overview

Note ![]() The following steps to configure and execute a DR Drill are based on the online Scout Help, which can be accessed from the main vContinuum page.
The following steps to configure and execute a DR Drill are based on the online Scout Help, which can be accessed from the main vContinuum page.
Summary of Steps
1. ![]() 1. Start vContinuum wizard application.
1. Start vContinuum wizard application.
a. ![]() Select VM(s) for DR Drill.
Select VM(s) for DR Drill.
b. ![]() Specify snapshot to use based on time or tag.
Specify snapshot to use based on time or tag.
c. ![]() Perform Readiness Check to make sure the VM(s) are ready for DR Drill.
Perform Readiness Check to make sure the VM(s) are ready for DR Drill.
d. ![]() Configure network, hardware, and display name for new VM(s).
Configure network, hardware, and display name for new VM(s).
e. ![]() Select datastore(s) for new VM(s).
Select datastore(s) for new VM(s).
2. ![]() Monitor DR Drill progess from CX UI or vContinuum wizard application.
Monitor DR Drill progess from CX UI or vContinuum wizard application.
Detailed Steps
Step 1 ![]() On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
On the Management Console, start the vContinuum wizard application via the desktop icon or Start menu shortcut Start>Program>InMage System>VContinuum>vContinuum.
a. ![]() Select ESX from the Choose Application drop-down list to view V2V protection plans or P2V for P2V.
Select ESX from the Choose Application drop-down list to view V2V protection plans or P2V for P2V.
b. ![]() Enter the CX server IP address and port number (default is 80) and click Get Plans.
Enter the CX server IP address and port number (default is 80) and click Get Plans.
c. ![]() Select the Manage Plans radio button and click DR Drill.
Select the Manage Plans radio button and click DR Drill.
Figure 4-82 Starting DR Drill on vContinuum

d. ![]() Select the primary VM(s) for the DR Drill and then click Next.
Select the primary VM(s) for the DR Drill and then click Next.
Figure 4-83 Selecting Primary VMs for DR Drill

e. ![]() Specify snapshot to use based on time or tag.
Specify snapshot to use based on time or tag.
–![]() Latest Tag: Select this option to recover a VM to a latest tag that is common across all volumes of a VM. For example, if a VM that has three volumes (e.g., C, E, and F), the latest common tag that is available across all volumes at same time point across all volumes is used.
Latest Tag: Select this option to recover a VM to a latest tag that is common across all volumes of a VM. For example, if a VM that has three volumes (e.g., C, E, and F), the latest common tag that is available across all volumes at same time point across all volumes is used.
–![]() Latest Time: Select this option to recover a VM to a latest common point time among all volumes of a VM. Only common time points where volumes are in green state (data mode) are considered. For example, if a VM that has three volumes (e.g., C, E, and F), the latest common time where all three volumes are in green state (data mode) is used.
Latest Time: Select this option to recover a VM to a latest common point time among all volumes of a VM. Only common time points where volumes are in green state (data mode) are considered. For example, if a VM that has three volumes (e.g., C, E, and F), the latest common time where all three volumes are in green state (data mode) is used.
–![]() Tag at Specified Time (Source Time Zone): Select this option to recover a VM to a common tag prior to the specified time. For example, if a VM that has three volumes (e.g., C, E, and F), the latest tag available prior to that time is used. The time provided is converted to GMT and compared against the timestamps in the retention logs. The closest consistency point prior to the time provided will be used to recover the VM.
Tag at Specified Time (Source Time Zone): Select this option to recover a VM to a common tag prior to the specified time. For example, if a VM that has three volumes (e.g., C, E, and F), the latest tag available prior to that time is used. The time provided is converted to GMT and compared against the timestamps in the retention logs. The closest consistency point prior to the time provided will be used to recover the VM.
–![]() Specific Time (Source Time Zone): Select this option to recover a VM to a common point in time among all volumes of a VM. The time provided is converted to GMT and compared against the time stamps of the primary server. All recovery times are based on primary server's time stamps and not the secondary or management console times
Specific Time (Source Time Zone): Select this option to recover a VM to a common point in time among all volumes of a VM. The time provided is converted to GMT and compared against the time stamps of the primary server. All recovery times are based on primary server's time stamps and not the secondary or management console times
Note ![]() Click Apply for all VMs to perform the DR Drill for all VMs at the specified snapshot type.
Click Apply for all VMs to perform the DR Drill for all VMs at the specified snapshot type.
f. ![]() Click Run Readiness Check to make sure the VM(s) are ready for DR Drill. If the check passes, then click Next to advance to the next page.
Click Run Readiness Check to make sure the VM(s) are ready for DR Drill. If the check passes, then click Next to advance to the next page.
Figure 4-84 Running Readiness Check for DR Drill

g. ![]() Configure network, hardware, and display name for new VM(s) if these configurations need to be different than what was defined in the original protection plan. In Figure 4-85, we are just appending "DRILL" to the end of each recovery VM display name, no other changes were made.
Configure network, hardware, and display name for new VM(s) if these configurations need to be different than what was defined in the original protection plan. In Figure 4-85, we are just appending "DRILL" to the end of each recovery VM display name, no other changes were made.
Figure 4-85 Modifying Network, Hardware, Display Name Settings for DR Drill

–![]() Click Advanced settings to access advanced settings for DR Drill. The default configuration shown in Figure 4-86. The options are greyed out except for the folder name section.
Click Advanced settings to access advanced settings for DR Drill. The default configuration shown in Figure 4-86. The options are greyed out except for the folder name section.
–![]() In the Folder Name Settings section, the directory for the VM in the datastore can be configured.
In the Folder Name Settings section, the directory for the VM in the datastore can be configured.
Figure 4-86 Optional Advanced Settings for DR Drill

–![]() Click Next to advance to the final page.
Click Next to advance to the final page.
h. ![]() Select the datastore(s) for the new VM(s) that will be created for the DR Drill, then click Next.
Select the datastore(s) for the new VM(s) that will be created for the DR Drill, then click Next.
Figure 4-87 Selecting Datastores for DR Drill

i. ![]() Select the order the new VM(s) should be powered up in. For example, if some VM(s) are dependent on another VM to up and running before they should power up, then you want to have the dependent VM(s) power up last. The default Recover Order is all "1" and all VM(s) will be powered up within seconds of each other. In Figure 4-88, the Recovery Order was changed to 1 through 5, so each DR Drill VM will be powered up about 90 seconds after the previous VM.
Select the order the new VM(s) should be powered up in. For example, if some VM(s) are dependent on another VM to up and running before they should power up, then you want to have the dependent VM(s) power up last. The default Recover Order is all "1" and all VM(s) will be powered up within seconds of each other. In Figure 4-88, the Recovery Order was changed to 1 through 5, so each DR Drill VM will be powered up about 90 seconds after the previous VM.
Figure 4-88 . Recovery Order for DR Drill

j. ![]() Click Readiness check to verify the Master Target is ready to perform a DR Drill.
Click Readiness check to verify the Master Target is ready to perform a DR Drill.
Figure 4-89 Readiness Check for DR Drill

k. ![]() Enter DR Drill plan name and initiate drill.
Enter DR Drill plan name and initiate drill.
Figure 4-90 Naming and Starting DR Drill

Step 2 ![]() Monitor DR Drill progess. After starting the DR Drill, vContinuum goes through several steps to execute the drill, which can be monitored from the status window.
Monitor DR Drill progess. After starting the DR Drill, vContinuum goes through several steps to execute the drill, which can be monitored from the status window.
Figure 4-91 DR Drill Starting (vContinuum)

Figure 4-92 DR Drill Monitoring (vContinuum)

Figure 4-93 DR Drill VMs (Service Provider vCenter)

Figure 4-94 DR Drill Status

 Feedback
Feedback