Health Insights の概要
Health Insights は、リアルタイムで重要業績評価指標(KPI)のモニター、分析、アラート、トラブルシューティングを行うネットワーク正常性アプリケーションです。
動的検出および分析モジュールを構築できるので、オペレータはユーザー定義のロジックでネットワークイベントをモニターし、アラートを生成できます。
また、モデル駆動型テレメトリと SNMP ベースのテレメトリに基づいて事前に作成された KPI が用意されています。Health Insights 推奨エンジンは、データマイニングを使用してネットワークを分析し、どのテレメトリパスを有効にしてモニターすればよいかを提示します。
 重要 |
KPI と Health Insights を使用してテレメトリを収集する場合は、拡張 Cisco Crosswork Data Gateway を構成しておく必要があります。 |
(注) |
Health Insights で推奨エンジンを機能させるには、Cisco Crosswork Health Insights とデバイスとの間に接続を確立する必要があります。デバイス自体、Crosswork のデバイス構成、および Crosswork のデバイスの認証情報プロファイルで、NETCONF プロトコルを有効にしてください。 |
Health Insights は、デバイスリンクのリンク帯域幅使用率データを収集するように構成されています。そして、一定期間がすぎると、リンクごとにパフォーマンスの基準を確立します。リンクが基準から逸脱してアラートが生成された場合は、Health Insights がそのアラートを検出するので、適切なプレイブックを実行して、ネットワークを再構成し、問題を解決できます。
次に大まかな例を挙げて、Health Insights が他の Cisco Crosswork Network Controller コンポーネントとどのように対話するのか、その概要を示します。
-
Health Insights が異常を検出:ネットワーク内の各リンクでモニターしている光ビットエラーレートが突然増大します。
-
変更自動化 プレイブックが自動的に修復:ただちにアップリンクに切り替えます。サービスを復元します。チケットを開きます(ユーザーが手動で開始)。ネットワークエンジニアにアラートを発します。
対話の複雑さは、異常のタイプ、異常の検出方法、異常の修復に使用するプレイブックによって異なります。変更自動化 プレイブックを使用してあらゆる形式のネットワーク修復を調整できるため、問題解決のループを閉じ、ネットワークのダウンタイムを最小限に抑えることができます。
Health Insights アラートダッシュボード
Health Insights アラートダッシュボードでは、リアルタイムのネットワーク状態イベントに基づいたデバイス正常性サマリー情報を確認できます。特定のデバイスグループとペアになっている KPI センサーのネットワークビューが表示されます。Health Insights は、ユーザー定義の論理に基づいて、カスタマイズ可能なイベントとアラートを生成します。
(注) |
アラートダッシュボードには、個々の KPI アラートが表示されます。ただし、デバイスで KPI を有効にするメカニズムは、KPI プロファイルを介して行われます。 |
Health Insights ダッシュボードを表示するには、メインメニューから を選択します。
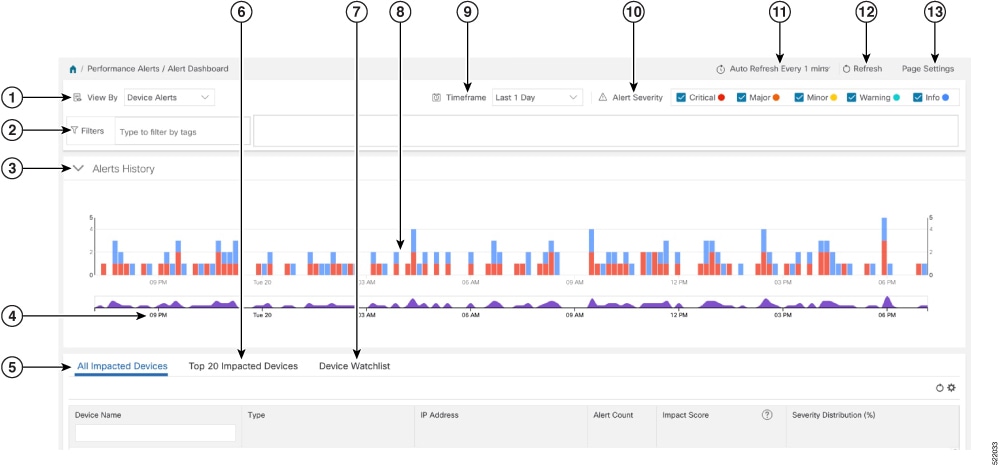
| 項目 | 説明 |
|---|---|
|
1 |
[デバイス/KPIアラートセレクタ(Device/KPI Alert Selector)]:デバイスアラートと KPI アラート情報を切り替えるには、ここをクリックします。 |
|
2 |
[フィルタ(Filters)]:このフィールドを使用すると、関連付けられたタグ名でアラートダッシュボード情報をフィルタ処理できます。タグを選択するには、次のいずれかの手順を実行します。
作成したタグフィルタは保存されません。そのため、別のウィンドウを開いてからアラートダッシュボードに戻る場合は、タグフィルタを再作成する必要があります。 |
|
3 |
[アラート履歴(Alerts History)]:このダッシュレットには、選択した期間中に発生したデバイスアラートまたは KPI アラートの総数が表示されます。個々のアラートセットとアラート全体のトレンドの両方が詳細なタイムラインで示されます。 |
|
4 |
[アラートトレンドライン(Alerts Trend Line)]:このラインは、選択した期間におけるアラート全体のトレンドを示しています。[アラートトレンドライン(Alerts Trend Line)] では、次のように、[アラート履歴ライン(Alerts History Line)] 内の特定の期間を選択してズームインできます。
[アラート履歴ライン(Alerts History Line)] のビュー全体の表示に戻すには、[アラートトレンドライン(Alerts Trend Line)] の薄い灰色の網掛け部分以外の任意の点をクリックします。 |
|
5 |
[影響を受けたすべてのデバイス(All Impacted Devices)]/[影響を受けたすべてのKPI(All Impacted KPIs)]:選択すると、アラートの影響を受けたすべてのデバイスまたはすべての KPI が一覧表示されます。影響を受けたデバイスまたは KPI ごとに、次の情報が表示されます。
|
|
6 |
[影響を受けた上位20個のデバイス(Top 20 Impacted Devices)]/[影響を受けた上位20個のKPI(Top 20 Impacted KPIs)]:選択すると、タイルのマップが表示されます。各タイルは、選択した期間中に発生したアラートの数が多かった上位 20 個のデバイスまたは KPI を表します。マップ内で各タイルが占めるスペースの量は、発生したアラートの数に対応しています。アラートが多いほど、タイルが大きくなります。また、タイルは色分けされています。色は、アラートの重大度に対応しています。 特定のデバイスまたは KPI の詳細な情報を表示するには、タイルの中央にあるデバイスまたは KPI 名のリンクをクリックします。 |
|
7 |
[デバイスウォッチリスト(Device Watchlist)]/[KPIウォッチリスト(KPI Watchlist)]:選択すると、アラートの影響を受けたデバイスまたは KPI のうち、[+デバイス/KPIウォッチリストの管理(+ Manage Deveice/KPI Watchlist)] から選択したものがすべて一覧表示されます。影響を受けたデバイスまたは KPI ごとに、次の情報が表示されます。
|
|
8 |
[アラート履歴(Alerts History)]:[アラート履歴(Alerts History)] 行には、アラートが個別のバーインジケータとして表示されます。その高さは、各時点で収集されたアラートの総数を表します。アラートの各タイプの総数を表示するには、バーインジケータの上にマウスカーソルを置きます。また、[アラートトレンド(Alerts Trend)] 行を使用して、アラート履歴の特定の部分をズームインすることもできます。 |
|
9 |
[タイムフレーム(Timeframe)]:過去 1 時間、過去 1 日、過去 1 週間など、ダッシュボードに表示されるアラート情報の期間を指定します。アラート情報だけがダッシュボードに表示され、テレメトリ情報は表示されないことに注意してください。 |
|
10 |
[アラート重大度(Alert Severity)]:[アラート履歴(Alert History)] ダッシュレットに使用されるバーインジケータの色を対応するアラート重大度にマップします。特定の重大度のアラートを表示または非表示にするには、その重大度のチェックボックスをオンにします。オンのチェックボックスは、その重大度のアラートが発生し、現在表示中であることを示します。オフのチェックボックスは、その重大度のアラートが現在表示中でないか、表示された期間中に発生していないことを示します。 |
|
11 |
[自動更新(Auto Refresh)]:ダッシュボードが自動的に更新される頻度を指定します。 |
|
12 |
[更新アイコン(Refresh Icon)]:ダッシュボードを更新します。 |
|
13 |
[ページ設定(Page Settings)]:特定のセッションに対するデフォルトのページ設定を指定できます。アラートタイプ、タイムフレーム、自動更新、詳細表示、アラート重大度に基づいて、ページ表示をカスタマイズできます。また、ここでは影響スコア計算の重み付けを変更することもできます。 |
(注) |
特定の KPI の個々のアラートがダッシュボードに表示されます。アラートグループ論理に起因するアラートは、ダッシュボードに表示されません。影響を受けた結果が表示されるのは API だけです。 |
ネットワークデバイスのアラートの表示
デバイスで KPI を有効にすると、そのデバイスのアラートを表示し、モニター対象の各業績評価指標のデータを取得できます。
(注) |
次の手順で示している KPI は例として挙げたものです。Health Insights で使用可能な KPI は他にもたくさんあります。完全なリストについては、Health Insights KPI のリストを参照してください。 |
手順
|
ステップ 1 |
メインメニューから、 を選択します。Health Insights アラートダッシュボードが表示されます。  |
||
|
ステップ 2 |
[デバイスアラート(Device Alerts)] ビューが表示されていることを確認します(必要に応じて [デバイスアラート(Device Alerts)] トグルを選択してください)。次に、[アラート履歴(Alert History)] パネルの下までスクロールダウンし、[影響を受けたすべてのデバイス(All Impacted Devices)] タブをクリックします。ダッシュボードに、アラートのあるデバイスのリストが表示されます。 |
||
|
ステップ 3 |
[デバイス名(Device Name)] から詳細を表示するデバイスの名前をクリックします。Health Insights に、デバイスの基本的な [概要(Overview)] 情報、[アラート履歴(Alert History)]、[トポロジ(Topology)] マップ、デバイスで現在 [有効になっているKPI(Enabled KPIs)] のリストが表示されます。  [トポロジ(Topology)] マップは、メインメニューから [トポロジ(Topology)] を選択すると表示されるマップです。 |
||
|
ステップ 4 |
[有効になっているKPI(Enabled KPIs)] で、目的の KPI の 選択した KPI が時系列でグラフィカルに表現されます。72 時間の時間枠で、1 時間ごとにスロットが表示されます。 |
||
|
ステップ 5 |
タイムライン上のブラシをクリックし、目的のタイムスロットになるように移動します(最大 6 時間のタイムスロットを選択できます)。そうすると、そのタイムスロットに応じて [未加工(Raw)] または [サマリー(Summary)] のグラフィカルデータが表示されます。グラフ内の任意のデータポイントの上にマウスカーソルを移動すると、そのデータポイントに関する追加のポップアップ情報が表示されます。  赤い線またはタグは、KPI がトリガーされたポイントを表します。つまり、ここに KPI がモニターしている登録済み統計情報がある可能性があります。そうした時間ポイントと頻度を Health Insights が収集して識別しているので、こうしたイベントがいつ運用上の問題になるかを判断する際に参考になります。

|
テレメトリデータの保持
テレメトリデータは、デバイスから収集されて、時系列データベースに保存されます。過去 72 時間分のテレメトリデータが保持されていて、ストリームベースのアラートと呼ばれるプロセスを使用してアラートを識別するために Health Insights のアラートダッシュボードで使用されます。こうして「アラート」が生成されれば、そのアラートも同じ時系列データベースに保存されます。生成されたアラートは 30 日間保持され、この保持期間を伝えるメッセージがアラートダッシュボードのデバイス/KPI ビューの右上隅に表示されます。詳細については、ネットワークデバイスのアラートの表示を参照してください。REST API を使用してアラートを照会することもできます。





 フィードバック
フィードバック